The SearchRank Redemption: Inquiry's Quest From Click To Curiosity


When I first learned about P versus NP during my Ph.D., the professor emphasized a simple truth: Some problems are fundamentally harder than others, and the difference lies between finding a solution and verifying it. This distinction between P-class problems (polynomial time or, easy to solve) and NP-class problems (nondeterministic polynomial time or, hard to solve but easy to verify) seemed like abstract computer science. Then right before the final exam, I stumbled upon a quote1 that crystallized everything:
"If P=NP, then the world would be a profoundly different place than we usually assume it to be. There would be no special value in 'creative leaps,' no fundamental gap between solving a problem and recognizing the solution once it's found. Everyone who could appreciate a symphony would be Mozart; everyone who could follow a step-by-step argument would be Gauss."
In that moment, I had my own creative leap – P versus NP wasn't just about computational complexity but about the very nature of human ingenuity. I walked into that final and got an A, but more importantly, I walked out with profound appreciation for what the PNP conjecture reveals: There's no algorithm for genius, there’s no shortcut to creativity.

At Upwork, we're unlocking opportunity at scale by empowering clients and freelancers through our work marketplace. Building Uma™, Upwork's Mindful AI, I've realized that the P versus NP distinction defines the core challenge of our marketplace. P-class problems are simple: "Find a React developer" is solved with string matching. But most real-world hiring is NP-class: "Find someone who challenges assumptions" or "Help build something magical." These aren't queries you can match with exact words; these are problems of discovery. You recognize the right freelancer when you see their work, but can't specify in advance what makes them right. That's the essence of NP: easy to verify, hard to find.
Generative AI today makes these problems tractable not through brute force but by understanding nuance and navigating toward "good enough, fast enough" solutions. Uma uses embedding models for meaning, graph neural networks for analysis, and LLMs for reasoning. Together, they help us explore vast possibilities and surface solutions that feel like creative leaps, even though they’re grounded in data. This mirrors my original epiphany about P vs NP: Some problems can’t be reduced to formulas because they require exploration, iteration, and insight. And that’s what we’re building with Uma, an AI that doesn’t just compute answers, but helps our customers ask better questions and discover the right match for their unique needs.
The evolution of search is the story of how we’re learning to chip away at computational intractability, what I call our “SearchRank Redemption.” Like Andy Dufresne carving his tunnel to freedom with a rock hammer in the Hollywood masterpiece, we’ve been working to narrow the gap between “good” and “best,” between what’s computable and what sparks true discovery. This story told through the lens of search at Upwork spans three eras: conceptual, contextual and intellectual, each bringing us closer to our redemption, where human curiosity and machine intelligence unite to solve the hardest problems in exploration.
The Conceptual Era: When search was literal
In the 1990s, search began with TF-IDF2, a simple algorithm based on the intuition that rare words are informative. This was revolutionary when the web was young, with only a handful of search results. You could find that one academic paper among thousands by searching for its unique terminology. But as the web exploded, TF-IDF alone couldn’t distinguish between a million pages all mentioning “React developer.”
Enter PageRank. Different search engines tried different concepts of what made a page “good”–-some counted keywords, others measured traffic, but Google’s definition won: Good is popular, with popularity recursively determined by connections to other popular pages. PageRank plus TF-IDF didn't just find pages with the right words; it defined "good" at web scale, fast. These algorithms represented the golden age of P-class problems with pre-computed universal rankings for millions. It also meant one algorithm, one answer for everyone. It worked exactly as designed and that was our SearchRank prison. Searching "chatbot developer" found only exact matches. The brilliant engineer who’d built conversational AI but called it something else? Invisible.
We organized information for humans to navigate, not to understand intent. P-class solutions were elegantly deterministic but uniform. The “good enough, fast enough” mantra hid a deeper truth: Searchers didn’t click on the most authoritative talent on React, but they clicked on the most relevant React developer for them, right now, in their specific context.
The Contextual Era: When search learned nuance
The internet’s transition from conceptual to contextual search meant learning to discover, not just organize. We were transitioning to NP-class problems where verification is easy, discovery is hard. Consider this query: "Find a creative fintech UX designer in the Bay Area who challenges assumptions." This was impossible with keywords in the conceptual era. But the contextual era introduced deep neural networks over a decade ago along with the "lift and simplify" phenomenon. Like the kernel trick3, we lifted representations into higher-dimensional spaces where complex patterns became linear separable. "Challenges assumptions" could connect to testimonials like "asked why we were building a banking app when users needed a spending diary,” and “Bay Area” to talent ranging from San Francisco to San Jose.
At Upwork, we developed BERT-based4 embedding models to bring contextual awareness to Uma and understand intent beyond keywords. Our two-stage model training demonstrated how to solve the canonical NP-class problem of separating similar-sounding requests. For the example query, stage 1 used random negatives to learn designers differ from developers. Stage 2 used hard negatives to learn that fintech designers differ from healthcare designers. By distinguishing "almost right" from "exactly right," we transformed exponential search into a polynomial one. "Good" became what data said was good. There was no single concept guiding the formulation, only patterns latent in millions of successful matches.
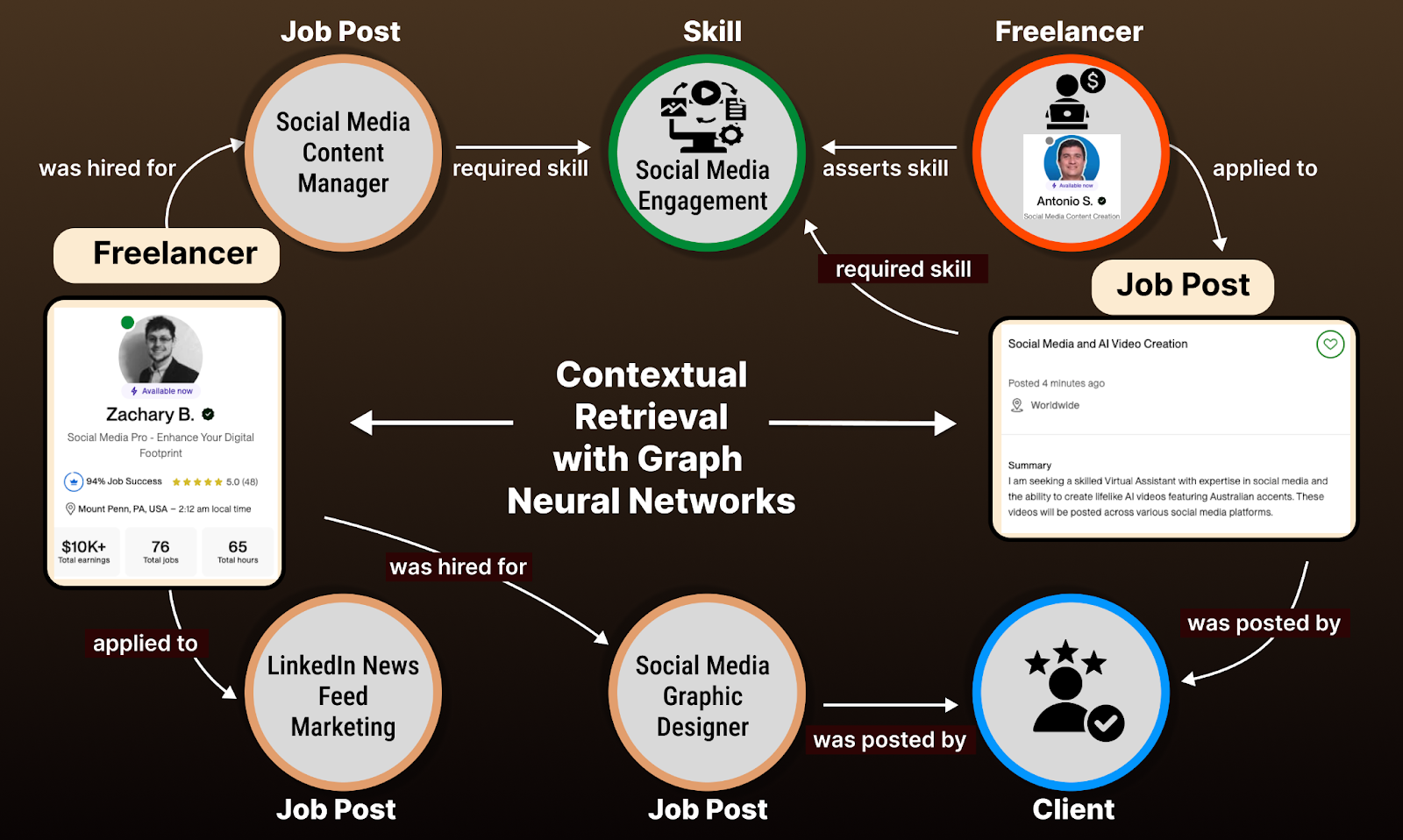
Our latest advancement goes beyond semantic matches to understand marketplace dynamics. While our embedding models capture intent, our graph neural network (GNN) models reveal who works well together. Using GraphSage's5 formulation with our embeddings as node attributes for freelancers, clients, and job posts, the GNN model reveals talent cohesion by utilizing the underlying connectivity structure as shown in the accompanying figure above. Furthermore, we observed that adding adversarial training examples6 to the GNN sampled from the base embedding model failure modes forced crisper distinctions through competition. A simple example: A client who hired a designer for their app later needed a writer for their pitch deck. The model learned that clients who value "challenges assumptions" in design often want "straight talk" in writing, a connection no human would have programmed. These higher-order patterns emerged from user interactions, not rules.
But training on millions of verified matches revealed a subtle yet fundamental limit. While we could match "challenges assumptions" to (hypothetically) Sarah from Palo Alto through concrete testimonials and portfolio examples, some queries like "Find a team like the one that made our competitor's app feel magical" pushed the boundaries of pattern matching. We were at the edge of NP-class problems, which required navigating exponential combinations of talent, chemistry, and collective capability. This would push us toward the next era, where search would learn not just to match, but to plan.
The Intellectual Era: When search learned to explore
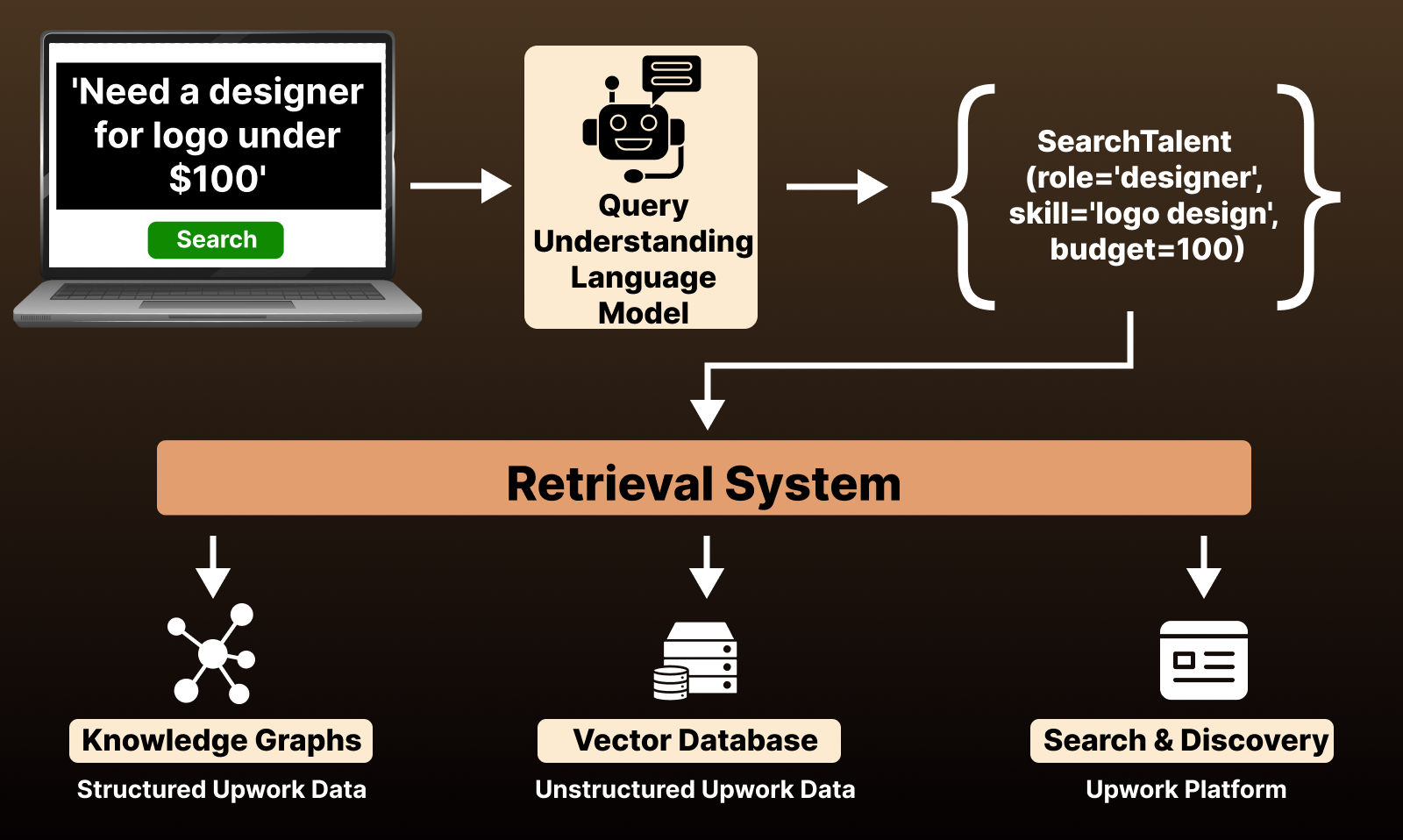
The emergence of large language models with ChatGPT in 2022 marked the web’s transition into the intellectual era, where we could finally tackle NP-complete problems, the hardest within the NP-class. For example, "team to emulate competitor's magical app" is technically verifiable but requires orchestrating a plan:
- Parse client preference for "magical" with text embedding model.
- Find matching designer portfolios with a multimodal embedding model.
- Shortlist developers using tools co-occurring with identified design framework.
- Find designer-developer pairs likely to collaborate well using GNN.
- Filter against competitor attributes and recommend the top-ranked pairs.
Each step builds on the last. The client will recognize the great alignment seeing them work together, but finding this ideal pair means navigating compositional complexity where chemistry matters as much as capability.
We fine-tuned a 7B parameter tool-calling LLM that outperformed GPT-4o (~200x larger) at orchestrating Upwork's search APIs and our knowledge bases through intelligent tool chaining, as illustrated above. Here are our key learnings:
- Synthetic data generation: We reverse-engineered conversational experiences. Past designer-client matches became dialogues about "someone who gets our brand." This taught the LLM why tools solve problems, not just how.
- Natural plan composition: The model learned that subjective queries need a text-based embedding model before GNN, i.e., know what you're looking for before tracing influence. Tool synergies emerged from data, not programming.
- Orchestration power: Access to dozens of models/APIs lets the planner compose novel combinations outside the training data distribution like TF-IDF for exact skills, then embedding models for semantics, blending techniques by what works.
What makes the intellectual era transformative is that LLMs not only tolerate ambiguity, but also depend on it. Their stochastic behavior becomes the universal translator that allows techniques from every previous era to work together. Temperature parameters, sampling strategies, and probabilistic generation in LLMs aren't workarounds for indeterminacy, but essential features exploring spaces that deterministic approaches can't reach. Where conceptual and contextual systems tried to minimize uncertainty through better data or more sophisticated models, LLMs use uncertainty itself to guide their search exploration. These features emerged because LLMs don't require perfect input-output mappings, but thrive in spaces between our engineered solutions.
Yet our best pattern matching and tool orchestration continues to reveal a deeper challenge. A search prompt like "Find that magical team" has verifiable answers. The clients know magic when they see it. Today, we use LLM-as-judge as a practical automated solution to these verification challenges. But some queries defy verification entirely like "Who would Steve Jobs hire for this design project?"
The Redemption: When search begins to reason
The pursuit of reasoning models marks our transition to NP-hard problems, where even verification becomes intractable. "Who would Steve Jobs hire?" involves unspoken rules and countless interpretations. You can verify Steve Jobs’ hiring of Jony Ive was great by admiring the iPhone. But channeling Jobs' intuition for a new project? No ground truth exists.
This challenge comes as the three levers of AI advancement — model design, capacity and data — face diminishing returns. Model design improvements drove the conceptual era, scaling deep learning models powered the contextual era, and data has been a continuous fuel to-date, but we're running out. Even Upwork's deep well of platform data can't solve the intellectual era's fundamental challenge: systems must reason about problems they've never seen.
The breakthrough is emerging through feedback loops. ChatGPT showed what's possible when human feedback teaches not just what but how in RLHF7. Chain-of-thought gives us a glimpse of internal feedback, the model's monologue as it reasons. I believe the next advancement in reasoning capabilities will stem from distinguishing outcome from process. We are exploring training large reasoning models on the hiring process, like "this interview question revealed talent," and not just the outcome of a hire. Each step benefits from feedback and agentic workflows naturally emerge from this decomposition.
For queries like "Who would Steve Jobs hire?" we envision multiple agents exploring design philosophy, analyzing portfolios against principles, and synthesizing matches recursively. Uma would aggregate insights and surface pairs spanning traits of minimalism, perfectionism and visionary to varying degrees. Clients would then evaluate and guide refinement toward their ideal match.
We're building Uma on the hypothesis that effective AI enhances rather than replaces human judgment. This is the future we're working toward at Upwork: Not just search, but an experience8. Not human vs AI, but human-plus-AI synergy through feedback loops. Humans excel at novel pattern recognition and creative leaps. AI excels at exploring vast possibilities and maintaining consistency. Together, they amplify the test-time scaling process9 itself and create understanding that neither could achieve alone. When the system explores 99 failed paths, human insight redirects toward the one that works. We're building this scaffolding for Uma where uncertainty becomes the shared medium for collaboration with our users. The future belongs to these agentic workflows with Uma, wherein human feedback transforms the hardest inquiries into meaningful insights.
From every corner of inquiry, the universe reminds us that limits are real. Gödel proved that even perfect logic leaves some truths unprovable. Physicists chase dark matter that bends spacetime yet can't be seen. When search begins reasoning, we'll realize our deepest inquiries have no perfect answers, only better questions — the existential echo of “good enough.” This isn't failure; it's how discovery works. After decades of building search systems, we've learned that the inquiry's quest isn't just about the right click, but discovering AI is only meaningful in light of human curiosity. Our freedom lies in every inquiry yielding something reasonable we needed and something incredible we never knew existed. This is our SearchRank Redemption.
References:
[1] Aaronson, S. (2006, September 4). Reasons to Believe. Shtetl-Optimized. https://scottaaronson.blog/?p=122
[2] Sparck Jones, K. (1972), “A statistical interpretation of term specificity and its application in retrieval”, Journal of Documentation, Vol. 28, pp. 11–21.
[3] Jordan, M.I., and Romain, T.. "The Kernel Trick." Lecture Notes. 2004. Web. 5 Jan. 2013. http://www.cs.berkeley.edu/~jordan/courses/281B-spring04/lectures/lec3.pdf
[4] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4171–4186).
[5] Hamilton, W., Ying, Z., & Leskovec, J. (2017). Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems (Vol. 30).
[6] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. In Advances in Neural Information Processing Systems (Vol. 27).
[7] Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep Reinforcement Learning from Human Preferences. In Advances in Neural Information Processing Systems (Vol. 30).
[8] Silver, D. , and Sutton, R.S. “Welcome to the Era of Experience” https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf
[9] Snell, C., Lee, J., Xu, K., & Kumar, A. (2024). Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters.


.svg)
You might like






Join the world’s work marketplace

Find talent your way and get things done.
Find Talent