You will get Data Engineering and Deep Learning using Spark & Python on Azure/AWS/Google
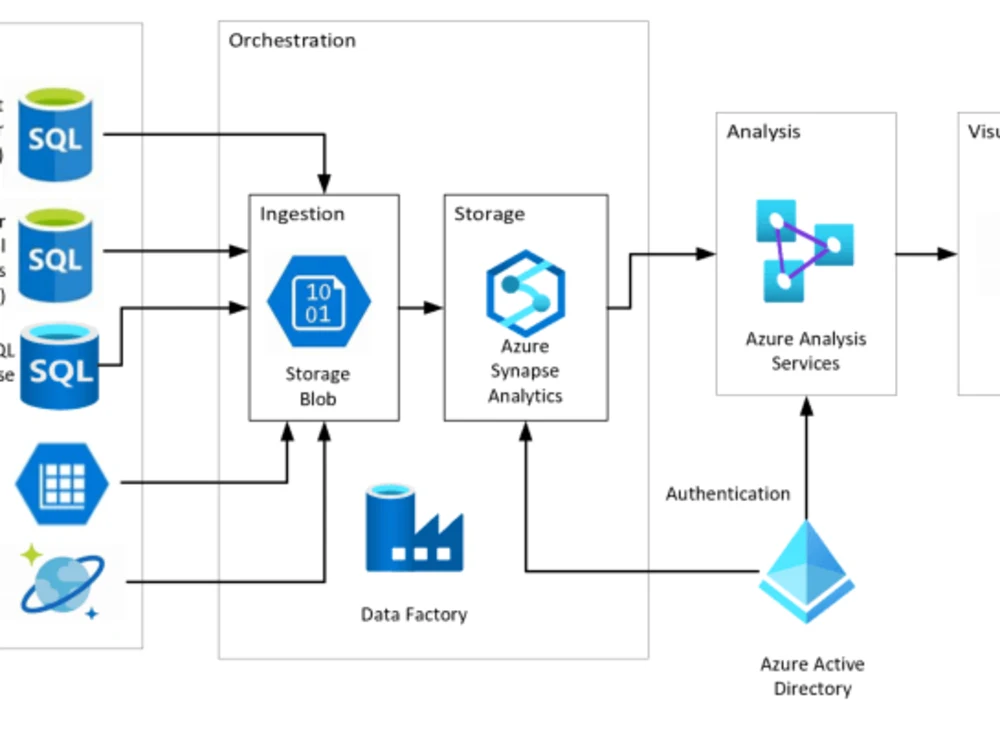
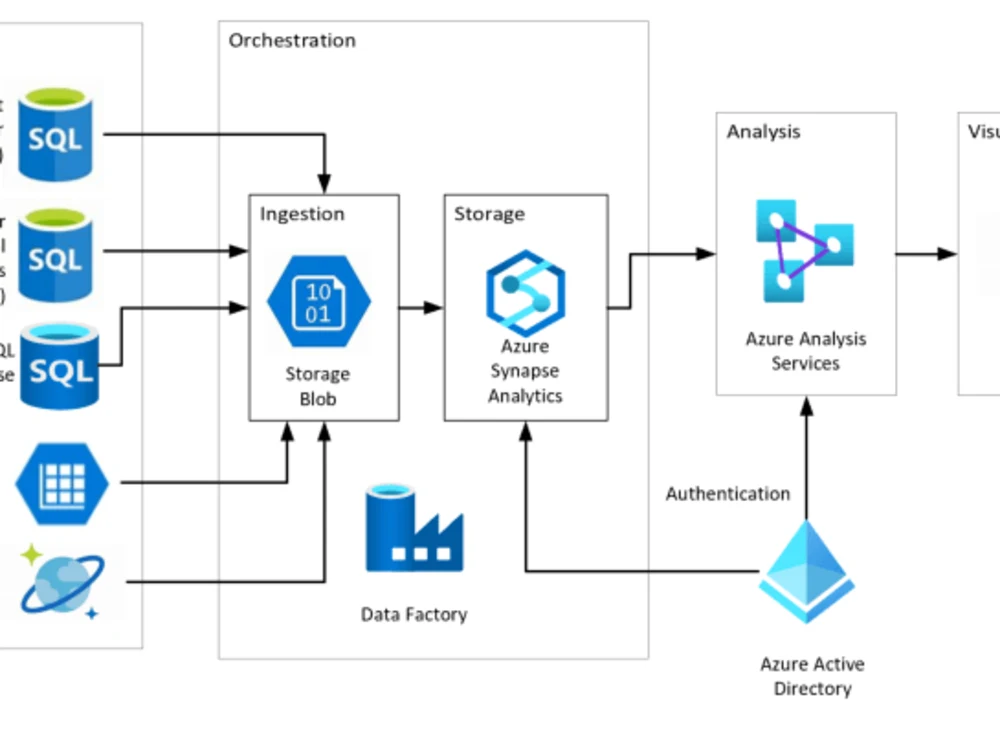
Project details
I am a Databricks Certified Data Engineering professional who has progressive experience in delivering business insights through data-driven methods. I am adept at gathering and analyzing data, using machine learning, deep learning.
Here are my key achievements in data engineering so far :
• Derived actionable insights from massive data sets using statistical analysis, SQL queries, real-time data ingestion.
• Improved data pipeline completion time using Apache Spark Caching and Databricks DBIO caching.
• Removed the overheads of a parquet data format by tunning of spark configuration.
• Improved Spark-Streaming Jobs performance by implementing Back-Pressure in the stream.
• Expertise in Big Data Eco-system.
Here are my key achievements in data engineering so far :
• Derived actionable insights from massive data sets using statistical analysis, SQL queries, real-time data ingestion.
• Improved data pipeline completion time using Apache Spark Caching and Databricks DBIO caching.
• Removed the overheads of a parquet data format by tunning of spark configuration.
• Improved Spark-Streaming Jobs performance by implementing Back-Pressure in the stream.
• Expertise in Big Data Eco-system.
Project Type
Data Analysis, Development, Cybersecurity, Data Protection, IT, File Conversion, QA, User TestingWhat's included
| Service Tiers |
Starter
$30
|
Standard
$40
|
Advanced
$50
|
|---|---|---|---|
| Delivery Time | 4 days | 4 days | 4 days |
Number of Revisions | 2 | 2 | 2 |
About Gaurav
Data & AI Architect | Cloud (Azure, AWS, GCP) | Databricks, Snowflake
Jaipur, India - 6:54 pm local time
I help companies build scalable data platforms and high-performance ETL pipelines that turn raw data into reliable insights for analytics, reporting, and AI.
With strong experience in Databricks, PySpark, SQL, and cloud data engineering, I design and implement data solutions that handle large-scale datasets efficiently while ensuring performance, reliability, and maintainability.
I specialize in building modern data pipelines and cloud data architectures that power business intelligence, machine learning, and real-time analytics.
What I Can Help You With
✔ Building scalable ETL/ELT pipelines using Databricks and PySpark
✔ Designing end-to-end data platforms on Azure or AWS
✔ Developing data ingestion pipelines from APIs, databases, and files
✔ Creating high-performance Spark transformations for large datasets
✔ Implementing data warehouse solutions for analytics and reporting
✔ Optimizing slow pipelines and reducing processing costs
✔ Building data pipelines for AI and machine learning workflows
Core Technologies
Data Engineering
Databricks, Snowflake
Apache Spark / PySpark
Delta Lake, Iceberg
SQL, Python, R, Scala, Java
Cloud Platforms: Azure, AWS, GCP
Data Integration:
Azure Data Factory
AWS Lambda
REST APIs
Batch & incremental pipelines
Data Warehousing & Lakehouse
Databricks Lakehouse
Snowflake
BigQuery
Steps for completing your project
After purchasing the project, send requirements so Gaurav can start the project.
Delivery time starts when Gaurav receives requirements from you.
Gaurav works on your project following the steps below.
Revisions may occur after the delivery date.
Understanding of Domain/Business of the Data
How data is helpful to the client and what all business logic needs to be implemented on top of the Process layer.