Machine Learning Techniques and How To Use Them
Machine learning is a form of AI that allows a system to learn from data rather than through explicit programming. Learn about the most-used techniques here.

.png)
.avif)
Machine learning is a type of artificial intelligence (AI) that mines big data and uses algorithms to mimic the brain’s ability to improve on a task through practice and repetition. Increasingly, organizations are embracing machine learning techniques to enable decision-making without human intervention. This can provide strategic insights and business intelligence through superior data analytics and forecasting.
Machine learning techniques can be divided into three broad categories: supervised, unsupervised, and reinforcement learning. Supervised learning algorithms are used to create a model based on known input and output data to make future predictions. Unsupervised learning detects hidden patterns in input data to make its predictions. Reinforcement learning uses trial and error to come to a solution through a sequence of decisions.
Machine learning algorithms generally depend on frameworks, such as TensorFlow and PyTorch for Python, to speed up solutions development.
Whether you’re new to machine learning or a veteran, here are some of the techniques you should have in your repertoire.
Linear Regression
Regression algorithms fall under the umbrella of supervised learning–they predict solutions according to prior data. For example, a regression model could predict how a group of stocks might do based on historical data.
There are many different kinds of regression techniques or methods, including polynomial regression, decision trees, neural nets, random forest regression, logistic regression, regularization, and the Gaussian process. But the simplest one, and the best place to start, is linear regression.

A simple linear regression works out the relationship between at least two variables, which can be dependent (target variables) and independent (predictor) variables. A model set is created using the mathematical equation y = m * x + b. Data pairs (x,y) are used for training data in a linear model and calculating the position and slope of a line, in which the total distance among all the data points is minimized.
Classification
Classification is a supervised machine learning method that involves predicting and sometimes explaining a class value. With the right input data, for example, it might be able to predict whether a customer will purchase a certain product, with the possible outcomes being “yes buyer” or “no buyer.” Of course, this method can cover situations with more than two possible outcomes, such as predicting different credit scores.
Classification works best when you can easily tag, categorize, or separate the data into specific groups or classes. A classified model analyzes input to learn how to classify new data. Different types of algorithms for classifiers include binary, multiclass, and multilabel.

In a multiclass classification, for example, the machine learning method might be able to identify different flowers, trees, bushes, and other plants. For accurate identification, the model must fully comprehend the special features that allow the classification of different items into specific categories.
Clustering
Clustering is the most common example of untrained machine learning. It depends on exploratory analysis to discover hidden patterns or groupings in data. Here’s a real-world example: A clustering algorithm is used to segment customers by different features to better target marketing campaigns or upload specific blog posts to a certain type of identified customer.
Clustering allows data points to be identified and grouped into structures—huge datasets that can be manipulated to yield new insights. The method doesn’t depend on the labeled data approach used by classification. Instead, it tries to achieve pattern recognition through shared or similar properties and then leverages these properties to create separate groups or clusters.
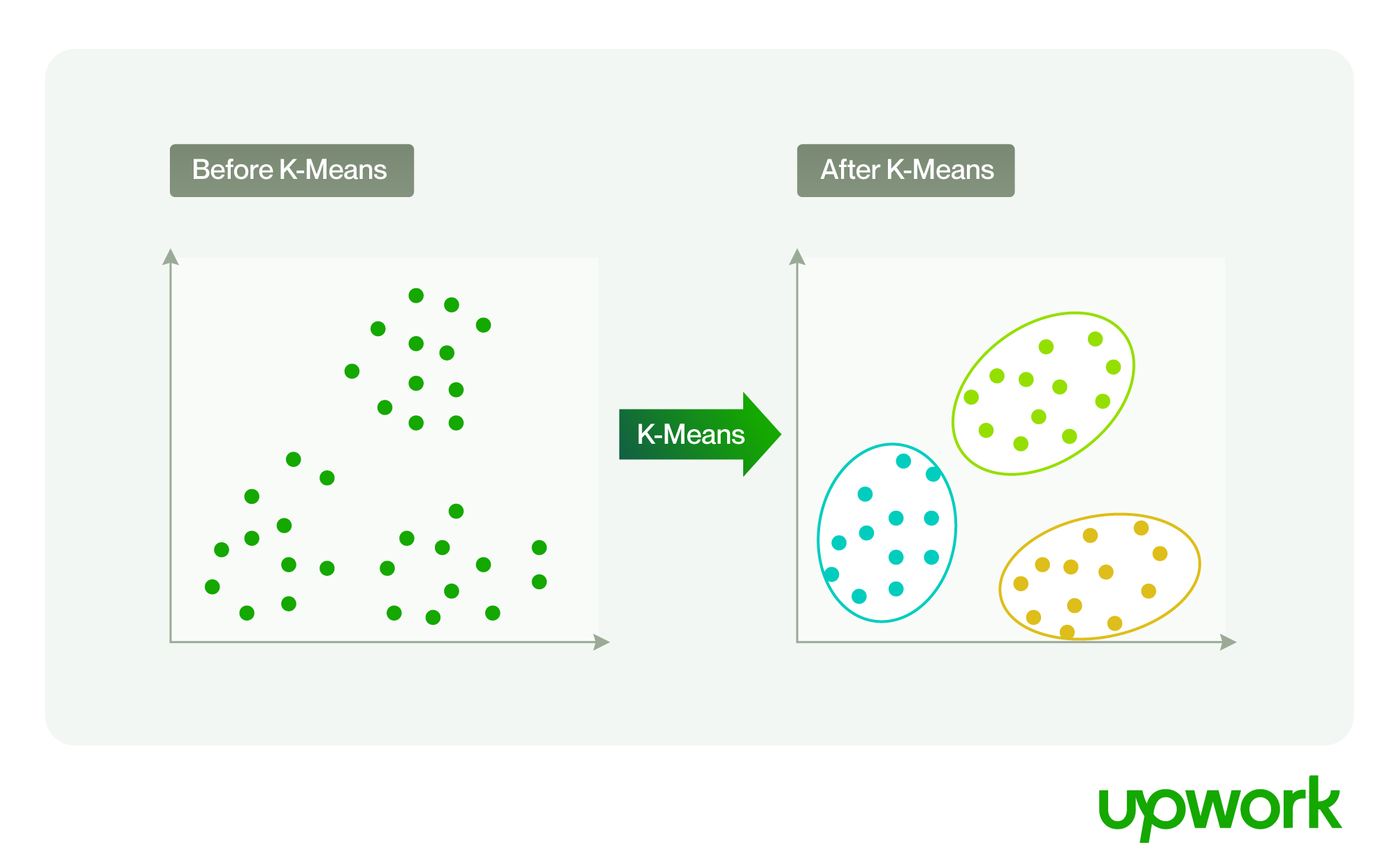
Because clustering is good at identifying patterns that may not be obvious, it has become one of the most common AI techniques in business and marketing. Different clustering approaches include starting with the randomly initialized center points of K-Means (K represents the number of clusters a user selects) or using different hierarchical, density, or distribution-based approaches.
Decision tree
This form of supervised machine learning is where data is split on an ongoing basis according to a specific parameter. The tree has both decision nodes and leaves. The leaves are the ultimate outcomes (decisions) and the decision nodes are where the algorithm has selected one outcome as more probable than another.
In determining if a person is fit, for example, a health care decision tree might be constructed with a lot of yes/no questions related to exercise, diet, blood pressure, weight, and so on. This is called a classification tree.

Regression trees use various data types to predict continuous outcomes from unseen data. Decision trees are employed to calculate the likely success of different decisions that aim to achieve a defined goal.
Neural networks
This form of machine learning is also known as artificial neural networks (ANNs) or simulated neural networks (SNNs). Neural networks look to the human brain, and how biological neurons signal each other, for inspiration . Neural networks are used to discern nonlinear data patterns, adding multilayers of parameters to the machine learning model.

Neural network algorithms are used in the deep learning process (usually with more hidden layers), breaking down complex problems into different levels of data and then solving them. The complex function is supposed to emulate how a human brain operates as we recognize new objects and learn new information while interacting with the world.
Deep learning and deep neural networks are particularly useful in text, audio, video, and image classification and identification.
Dimensionality reduction
If too many variables are introduced to an algorithm, machine learning performance can suffer or degrade. But an adequate number of attributes are required to provide as useful a dataset as possible. This is where dimensionality reduction can help. The technique reduces the number of input features, variables, or attributes to avoid overburdening the machine learning model.
For example, an image may have tens of thousands of pixels that are not pertinent to your analysis. In this case, you would use dimensionality reduction to narrow the data set to more manageable dimensions.

The most common method here is the principal component analysis (PCA), which reduces the dimensionality of datasets while making them easier to interpret and keeping important data loss to a minimum.
Transfer learning
Transfer learning is an ML technique in which a model created for a task is repurposed as the model for a second task. Let’s say you’ve developed a successful model to classify shoes, boots, sandals, and other footwear. You might reuse it, with some tweaks, to classify clothing items like shirts, pants, and socks.
Basically, you take your model and use it for a similar task. You can adapt the model for the new task by adding a few new layers to the trained ones. The original model may be one you’ve trained yourself, or it could be pre-trained from another source (such as another team that’s worked on a similar AI project).

With a transfer model, you save time from having to develop an original model for the second task.
Ensemble methods
Ensemble approaches combine different base models to create a single model with the greatest optimization. While there are many different ensemble methods to choose from, the three most common are:
- Bagging. Averaging the predictions of different decision trees set on a variety of test data samples of one dataset.
- Stacking. Using different predictive models for the same data and working with another model to learn how to best combine the results.
- Boosting. Different ensemble methods are added sequentially, each correcting prior results and providing an output with a weighted average of predictions.

To understand how this method could be useful, think of asking one friend for a movie recommendation. You might expand the potential viewing possibilities (and increase the possibility of getting something you like) by asking 10 friends whose movie tastes you trust. You would get even better results if you could ask hundreds or thousands of people for their choices, thus leveraging the power of ensemble methodology.
Word embedding
With natural language processing (NLP), word embedding is used to represent words for text analysis. This usually involves a real-valued vector that encodes the meaning of words, so those that are closer in the vector space are usually closer in meaning.
The ability to measure the similarity of words in mathematical terms allows for a range of data analyses. You can map words to a neural vector using a neural net-based method, such as Word2Vec. This is useful for finding synonyms, using words in arithmetic functions, and representing full text documents.

Word embedding helps bridge the distance between human and machine understandings of text. For example, you can use it to get actionable metrics from online customer reviews, perhaps analyzing survey responses in specific contexts and gaining insights to help improve your product or service.
Find the best machine learning professionals on Upwork
Whether you’re an organization looking for experienced help with a machine learning project or a data scientist looking for an interesting machine learning assignment, Upwork’s Talent Marketplace is a proven way to connect.
The portal makes it easy for companies to post a job and get responses from a variety of qualified candidates. Their expertise is essential; machine learning isn’t something you can pick up in a few online tutorials. You can check their qualifications with their verified work histories and reviews.
Once a job is underway, Talent Marketplace makes it easy to use chat and video conferencing to collaborate with your freelance supplier. It also has file-sharing capabilities and advanced reporting and tracking tools.
Use our job portal’s resources to make your complex machine learning gradient gentle and rewarding.

.avif)

Author Spotlight

Upwork is the world’s largest human and AI-powered work marketplace that connects businesses with independent talent from across the globe. We serve everyone from one-person startups to large organizations with a powerful, trust-driven platform that enables companies and talent to work together in new ways that unlock their potential.






