The Last Mile Problem: Why the Best Off-the-Shelf LLMs Aren't Always Good Enough


Large language models (LLMs) have crossed a threshold. GPT-4, Claude, Gemini, and their open-weight counterparts can summarize, draft, translate, and reason at levels that are genuinely impressive and for many tasks, incredibly useful.
But if you're building an LLM-powered product — not a chatbot toy, but a real product that people depend on — you've probably noticed that the last 10% of needed quality still feels missing. Users don't complain that the model "can't do the task." They complain that the output feels off, like they’re talking to a generic model as opposed to something bespoke to their profile, platform, or task. These subtle quality issues translate directly into weaker outcomes and leave users wondering whether they should have just done it themselves.
At Upwork, we've been building AI-powered tools that help professionals write stronger proposals, among a host of other customer experiences supercharged by Uma™, Upwork’s Mindful AI. What we've learned from analyzing over 100,000 conversations is that tuning an LLM for a production chat interface is less about making the model generally smarter and more about understanding the nuanced patterns that separate effective LLM-user conversations from ineffective ones.
Nuance doesn't show up in benchmarks
When you evaluate an LLM on standard benchmarks like MMLU, HumanEval, or MT-Bench, you're measuring general capability. That's useful for model selection for popular tasks like coding and general knowledge, but it tells you little about how the model will perform in your specific product context.
Consider a system that helps users draft professional job proposals by pulling together a talent profile, work history, and the context of the job they're applying for. Off the shelf, a frontier model can produce a grammatically correct, well-structured proposal in seconds. On a summarization benchmark, that might score well. In production, however, users still don't get the outcome they want, and the reasons are surprisingly hard to pin down.
The core problem is that quality in a production chat interface is multidimensional and context-dependent. It's not just about whether the model generated a coherent response. It's a constellation of factors: Did the output sound like the user, or like a machine? Did it accurately reflect the user's real experience, or did it hallucinate details? Did the user engage deeply with the tool, or just click a button and walk away? And most importantly, did any of this actually lead to the outcome the user cared about?
These are the kinds of questions that benchmarks can't answer, regardless of what model you use or whether you fine-tune your own. AI product teams need to evaluate, measure, and act using their own conversation logs at scale to gain insights, which is exactly what we set out to do.
From our investigation, the biggest insight wasn’t that we needed a smarter model. It was that we needed better measurement, tighter feedback loops, and stronger product incentives for users to engage meaningfully with AI.
Evaluate: Effective LLM-as-a-judge linked to outcomes
To understand what "good" actually looks like in our system, we built an evaluation framework that scored over 100,000 real conversations against 25 binary quality metrics for the Upwork proposal writing use case — 2.5 million measurable signals in total. These metrics fall into two categories: heuristic signals that can be easily measured programmatically, like conversation length and structure, and LLM-judged signals that require interpretation, like tone, hallucination detection, and whether the user's personality was preserved in LLM-edited conversations.
Then we did something that most LLM evaluations skip: We joined those quality scores to actual business outcomes — specifically, whether the talent who used the tool got hired. What we found challenged several of our assumptions about what makes a proposal effective.
Measure: User engagement matters more than model capability
The single strongest predictor of a good outcome wasn't any model quality metric; it was whether the user engaged deeply with the tool. Nearly 79% of users simply clicked the default button to draft a proposal automatically, without adding any custom context to their request. We noticed that users can benefit from a significant 4x likelihood boost in getting hired when they engage with the tool as opposed to those who impatiently accepted the first proposal given. Actually, the most successful users were nearly 7x more likely to get hired when they took the time to use the tool to edit, critique, and get feedback on their original proposals. That held true whether they were using an off-the-shelf model or our custom one.
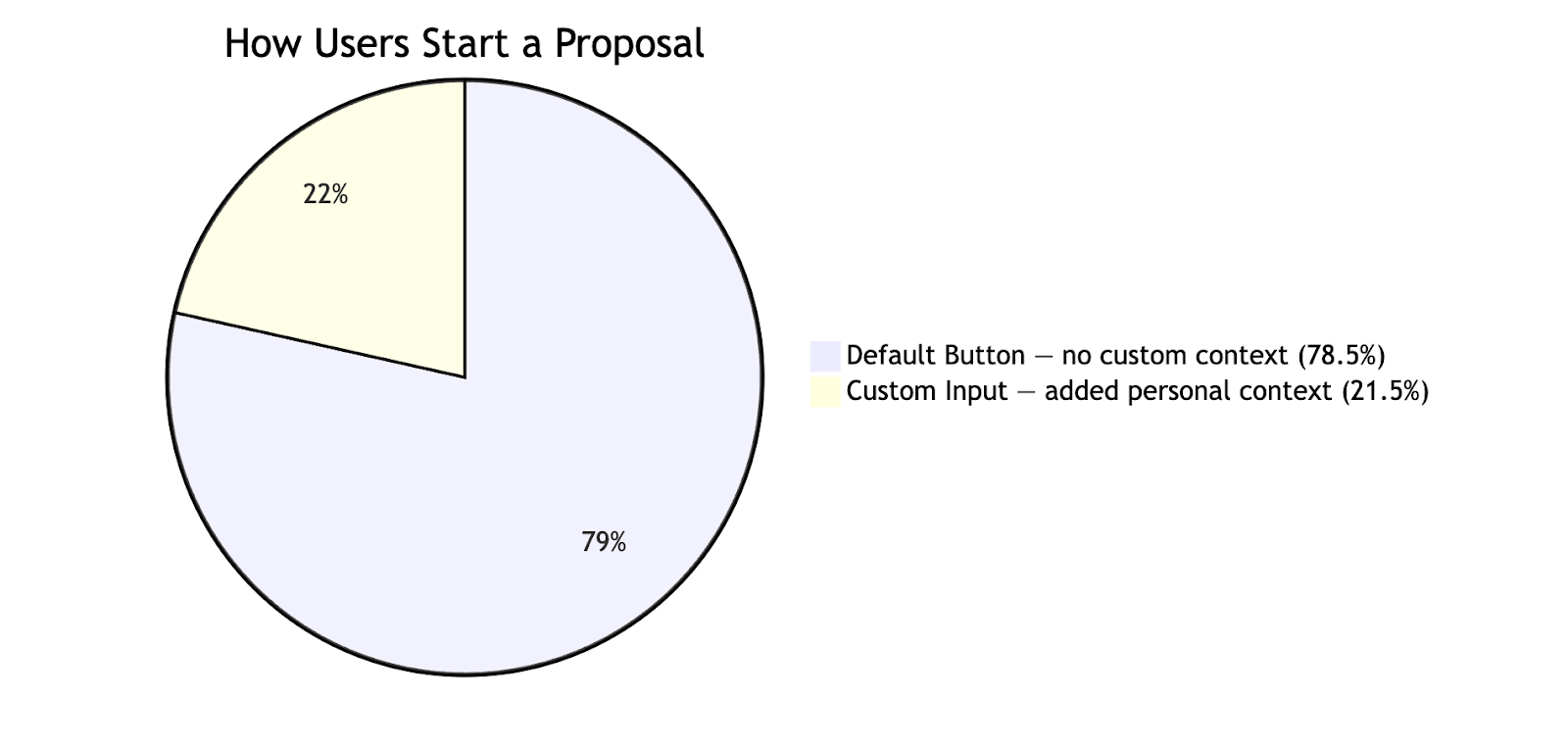
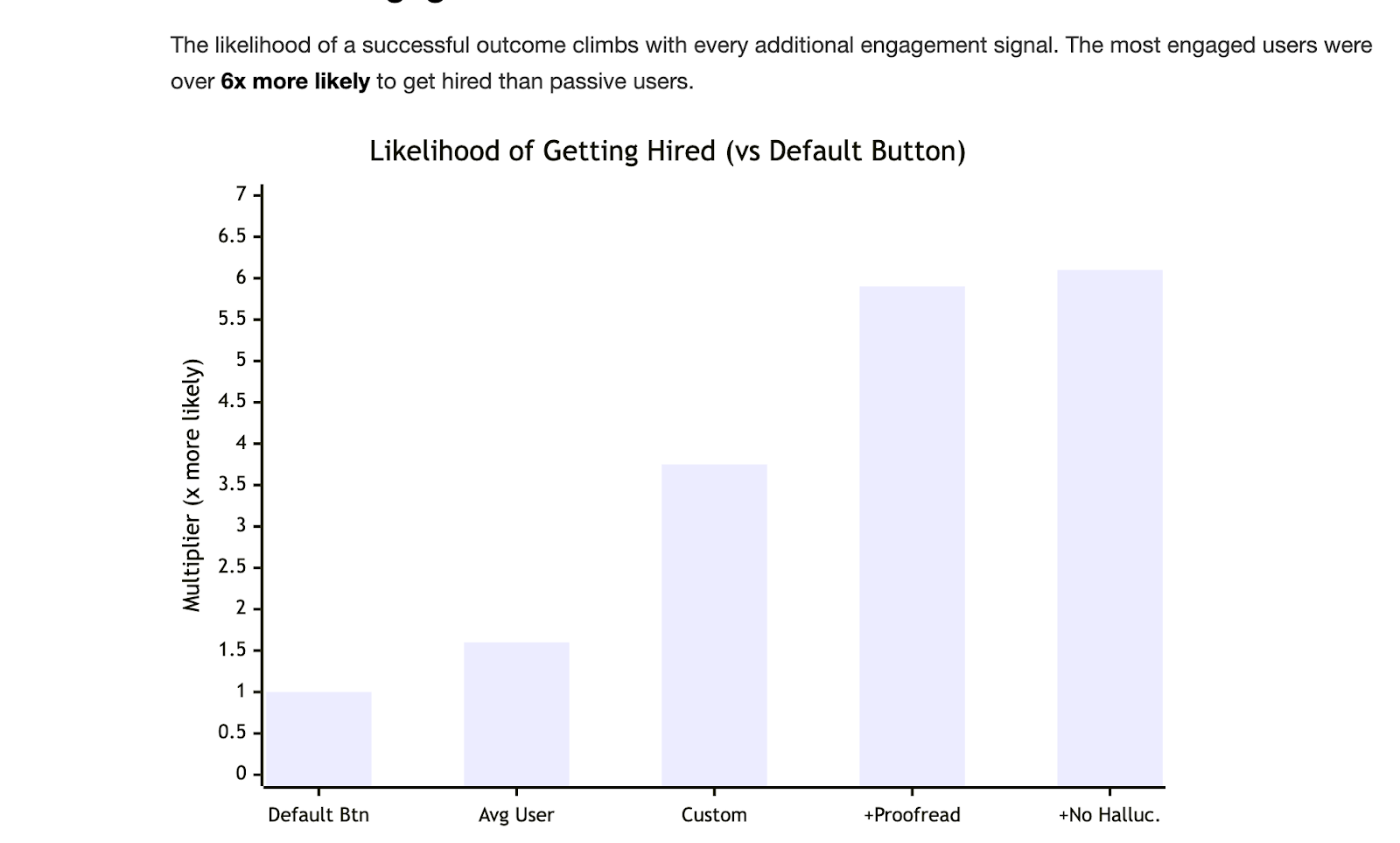
Closing the gap here isn't just a model intelligence problem. It's about giving users enough confidence in the experience that they're willing to invest effort in it — because that effort correlates with intent, and intent correlates with outcomes.
Measure: Robotic outputs are the silent killer
We found that 74% of conversations were flagged as sounding robotic in some regard. Conversations that avoided the robotic flag had a 1.8x higher success rate. These successful users were those that brought their original proposal and leveraged our LLM tool to edit and refine. Robotic voice and structure is a common complaint users have about AI-generated content, and it's one of the hardest things to fix with standard fine-tuning because "robotic" is subjective and contextual.
A proposal for a creative writing job should sound different from one for an enterprise data engineering role. That level of stylistic control requires curated, domain-specific training data and deliberate optimization for outcome quality. Without it, you’re left with a model that technically completes the task but quietly underperforms in the moments that matter.
Measure: Quality over quantity
When we first trained our custom models, we assumed that explicitly referencing job requirements and profile skills would strongly predict success. Instead, both showed a slight negative correlation with hiring outcomes. The reason was simple: these behaviors were nearly universal, so they didn’t differentiate strong proposals from average ones. The real separator wasn’t whether requirements were mentioned, it was how thoughtfully and nuanced a user presented themselves in ways that cut through the noise. Users who showed some level of satisfaction or more confidence in their AI-generated proposals were also shown to be less likely to get hired. This implies that perhaps a bias towards proposals that feel polished or detailed may be less effective in practice and what matters is how well a proposal stands out.
We found that shorter proposals were more likely to get chosen. Not because brevity is inherently better, but because they tend to read as authentically human, confident, and direct. Longer, information-dense proposals may feel more thorough to the person writing them, but they often work against the writer in practice.
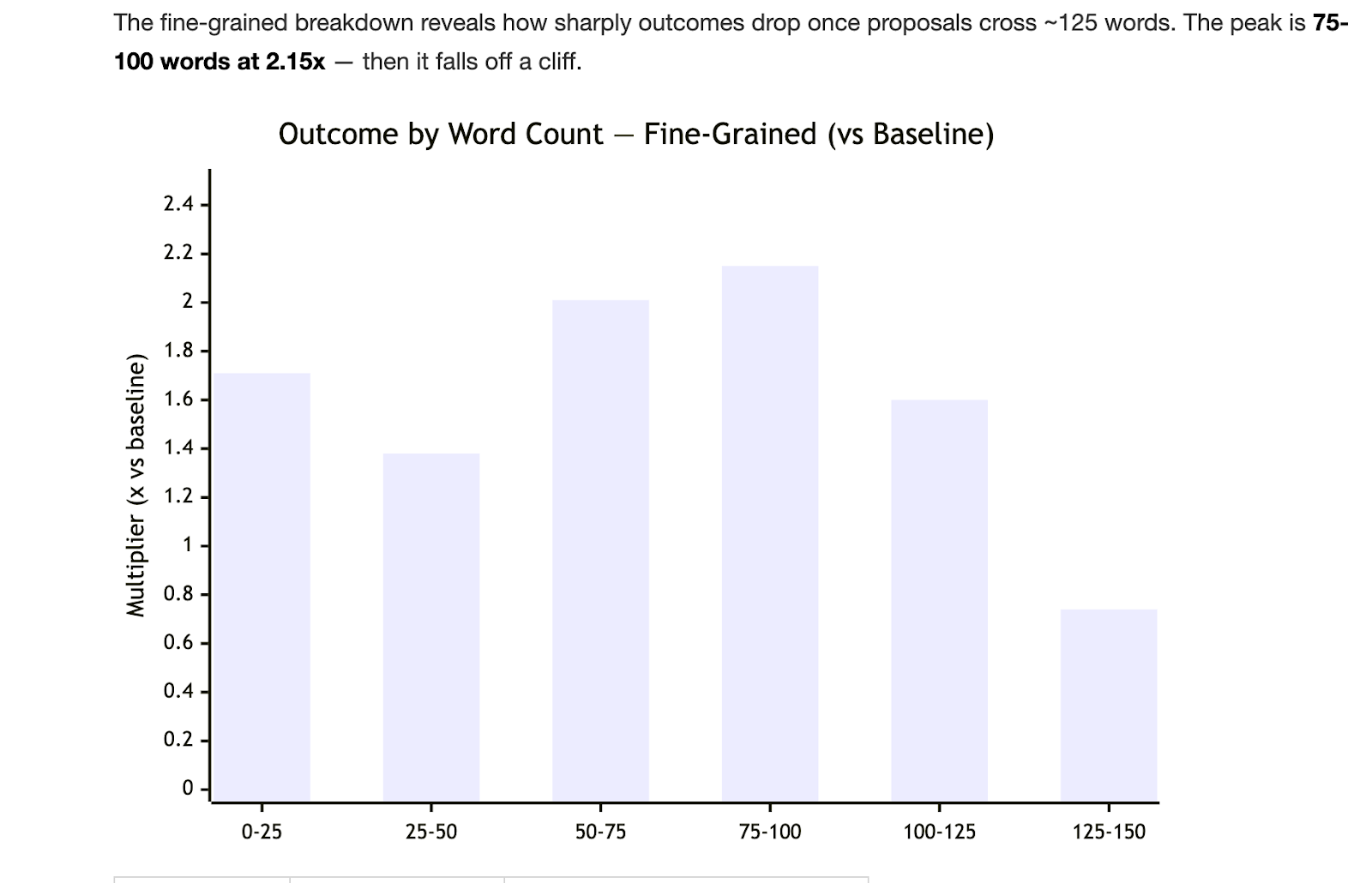
Smart LLMs crowd the proposals with information. The lesson is clear: Intuitive quality signals aren’t enough. Only outcome-linked measurement reveals what truly drives results.
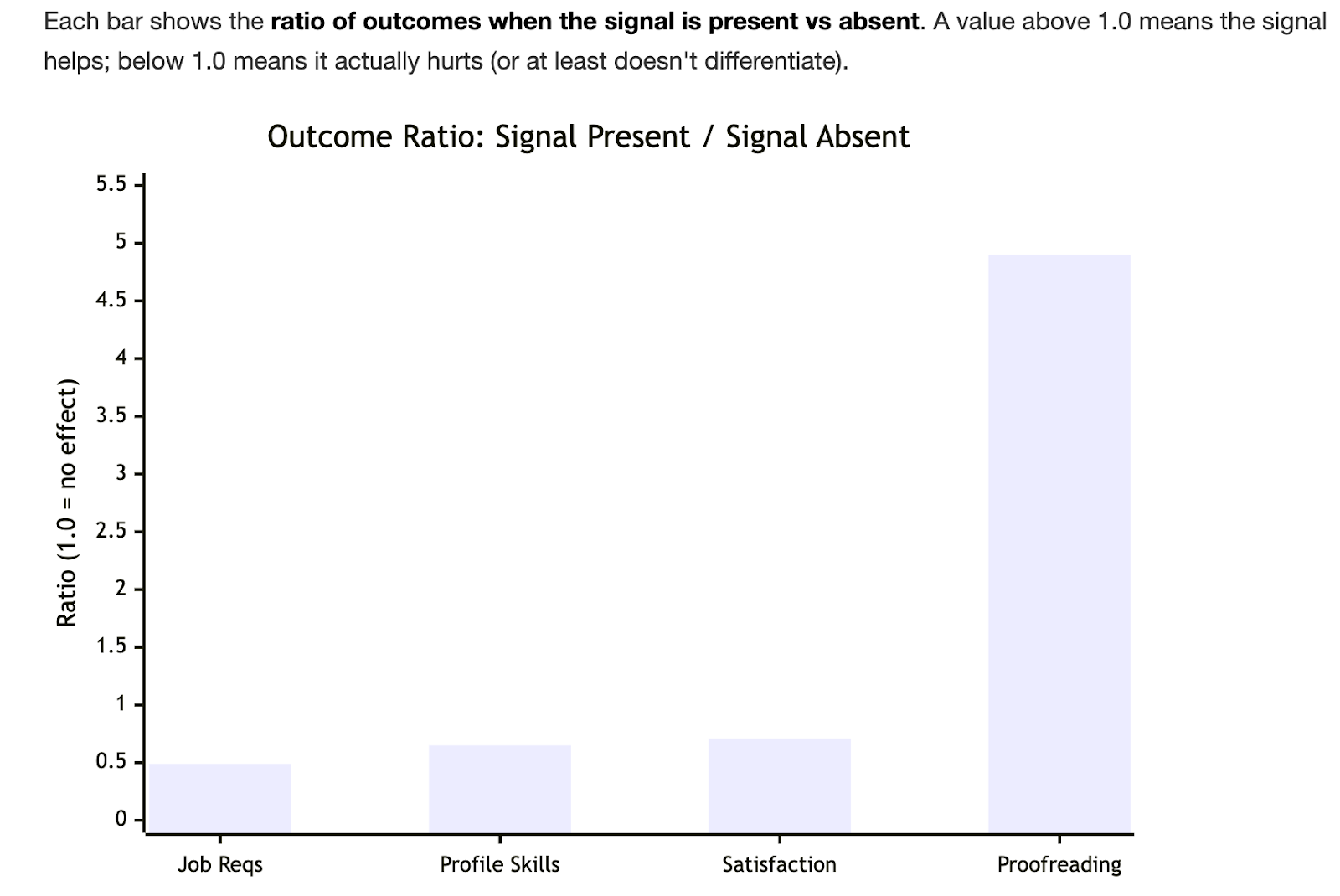
Measure: Hallucinations erode trust
If robotic output is the silent killer, hallucinations are the loud one. Proposals with hallucination flags saw a 34% reduction in positive outcomes like leading to a hire or getting an interview.
The tricky thing is that many of these hallucinations are subtle. The model doesn't say something obviously wrong. It confabulates plausible-sounding details that the user might not even catch before submitting, but that the person on the receiving end might. You want an amazing proposal that will certainly get the best client’s attention? An LLM will be good at obliging, but don't expect it to be honest. LLMs can sometimes be too good at giving what you ask for. Effective LLM model training needs to capture when an LLM should ask for clarification or more user input before giving an answer.
Action: From analysis to training data
Understanding what went wrong is only half the problem. The other half is correcting the model's behavior in a targeted way.
Our analysis naturally segmented conversations into quality tiers. The best-performing segment was users who provided custom context, engaged in proofreading, and avoided hallucination flags. They showed a roughly 4x better hire rate than baseline. That segment gave us thousands of high-quality conversations to use as a positive training signal.
But understanding failure modes was equally important. We identified more than 20,000 conversations that served as negative examples: outputs that sounded too robotic, contained hallucinated claims, or came from disengaged interactions—roughly a quarter of our total conversation volume. Through regular supervised fine-tuning and preference optimization tricks, we used both the positive and negative signals to tweak model behavior in ways that meaningfully outperform an off-the-shelf or naively fine-tuned model.
Of course, this isn't a one-shot process. You analyze, train, deploy, and then measure again. The quality bar shifts as the model improves, and new failure modes emerge. It's an ongoing feedback loop between product analytics, model development, and UI.
The real work of the last mile
After scoring conversations, tying them to hiring outcomes, and retraining both success and failure modes, a few durable patterns emerged that are system-level truths:
1. Tie everything to outcomes. Quality metrics that aren't anchored to business results will mislead you. "Sounds good to me" is not a metric. "Led to a hire" is.
2. User behavior is part of the model problem. You can't fully separate model quality from how users interact with it. A better UX that encourages deeper engagement can, in some cases, have more impact than a better model.
3. Minimizing negatives beats maximizing positives. Our data showed that reducing negative signals (hallucinations, robotic tone, bloated length) improved outcomes more than adding positive features. Getting out of the user's way matters more than impressing them.
4. Your intuitions about quality are probably wrong. Build the instrumentation to test them. Several of our "obviously good" metrics turned out to be neutral or even negatively correlated with success.
5. Smarter models don’t guarantee better products. The last mile is a product problem, not a model problem.
Any decision to "just use GPT" for critical business interfaces should be questioned. Not because frontier models aren't capable, but because production-grade AI products require behavioral nuance that no off-the-shelf model provides. The companies and product teams that win will be the ones that build the feedback loops to understand, at a granular level, what successful user-model behavior looks like, and hence use that understanding to continuously improve both their models and their product experience. The data to do this already exists for most teams. The question is whether they’re set up to learn from it.
For anyone building LLM-powered products: invest in outcome-linked evaluation early. It's not glamorous work, but it's the difference between a product that demos well and one that actually delivers value. The last mile in production isn't about making the model smarter. It's about making the experience work.


.svg)
You might like






Join the world’s work marketplace

Find talent your way and get things done.
Find Talent