Introducing the UPHELD Dataset: Upwork Human-Evaluated Longer Dialogues
.png)


This blog posts accompanies the paper Evaluating Language Models in Realistic Conversational Contexts, which was accepted for presentation at the International Conference on Machine Learning (ICML) 2026 in Seoul, Korea.
Most benchmarks say today’s LLMs are already excellent conversationalists. Our experience building Uma, Upwork’s AI work agent, suggested otherwise.
When we evaluated models on realistic, multi-turn conversations, the gap was clear: even advanced models often produced responses that felt overly verbose, or just slightly off. In customer-facing workflows, that last mile matters. It’s the difference between something that works in theory and something users actually trust.
To better understand and close that gap, we built a new benchmark for assessing the conversational skills of LLMs: UPHELD (Upwork Human-Evaluated Longer Dialogues). UPHELD is made up of ~14,000 data points, and we used it to train an internal model that supports Uma to nearly doubled conversation quality score in human evaluations across content and style.
Evaluating longer, multi-turn conversations
Most benchmarks focus on single-turn tasks — like mathematics problems, writing code, or simple instruction-following. Even some of the more inherently conversation-oriented tasks like multi-turn question-answering (e.g. HotpotQA, MultiHopQA), are evaluated based on whether the model produces the targeted factual information. These tests assume users behave in predictable ways, which is not true in real life. In our experience with models like productionized LLMs, such as Upwork’s job post generator model or proposal writer model, users often give short, vague, or ambiguous inputs — things that most benchmarks fail to capture. Because of this gap, we decided to build our own benchmark. UPHELD is designed to test how well AI models can really hold a conversation, even when inputs are messy or unclear.
So, we are tasked with creating a benchmark to evaluate how a model performs at holding conversations that are:
- Multi-turn and human-to-human
- Not anchored to specific verifiable knowledge
- Not anchored to a specific verifiable target task
Some research on open dialogue systems, such as Wizard of Wikipedia or Ubuntu Corpus, develops conversational datasets that satisfy the first condition. However, these datasets are either tied to specific knowledge bases (for example, a Wikipedia segment) or to specialized knowledge (such as a user’s Ubuntu expertise).
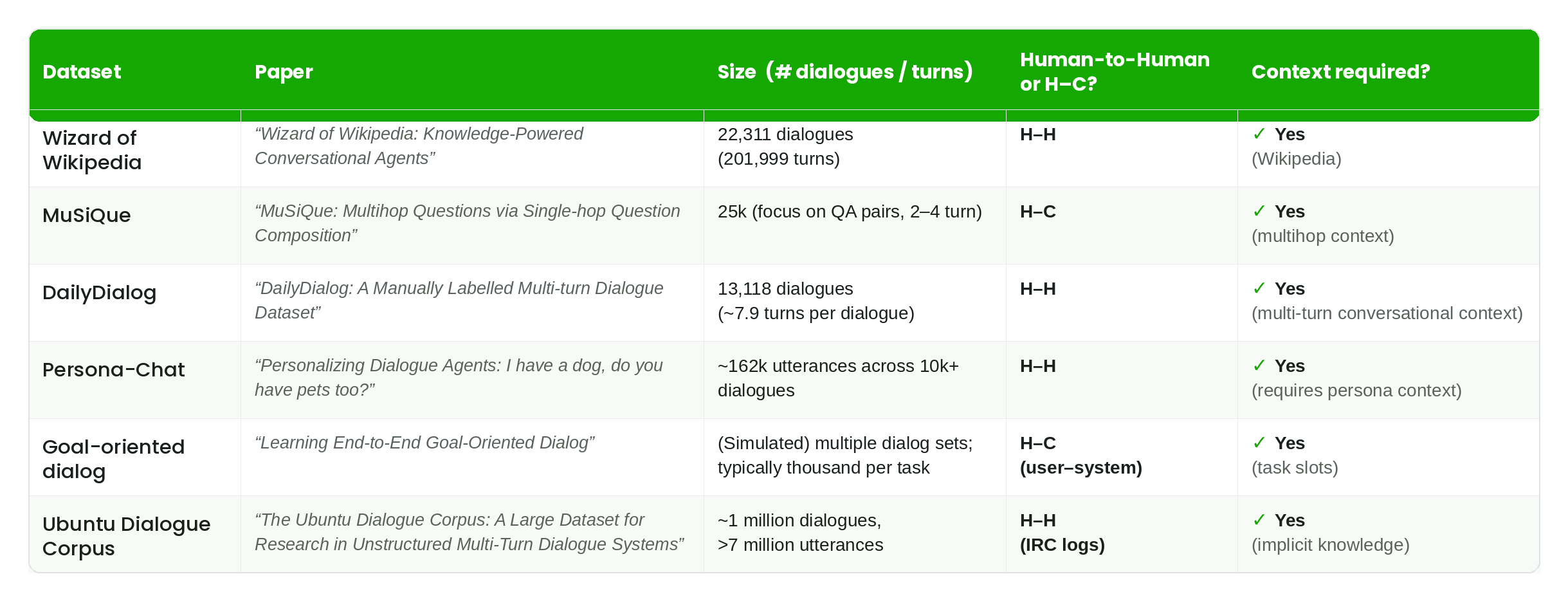
Unfortunately, testing a model’s ability to produce specific knowledge is generally unrelated to that model’s ability to hold a conversation. Specialized skills and knowledge can be ingrained into a model in very standard ways that do not help with conversational ability, like in-context learning or RAG, so we need something better to get to the crux of a model’s ability to hold a dialogue.
AI chatbots are poor conversationalists
One of the key motivations for launching this project was our early observation that, counterintuitively, AI chatbots can be poor at holding conversations. They’re generally proficient at answering questions and information retrieval (modulo hallucinations), but in targeted goal-driven conversations — like those in customer-facing settings — AI models tend to be overly verbose and templatized. For example, when asking GPT-4o to judge itself on conversational quality, the results below were fairly bleak. Moreover, the problem doesn’t appear to be improving: Our tests at the time showed that there was a small but measurable regression between conversational quality of GPT-3.5 and GPT-4o. We are currently updating our experiments to include more recent models, such as the GPT-5 class, but we don’t foresee major improvements due to their focus on non-conversational contexts like coding and math.
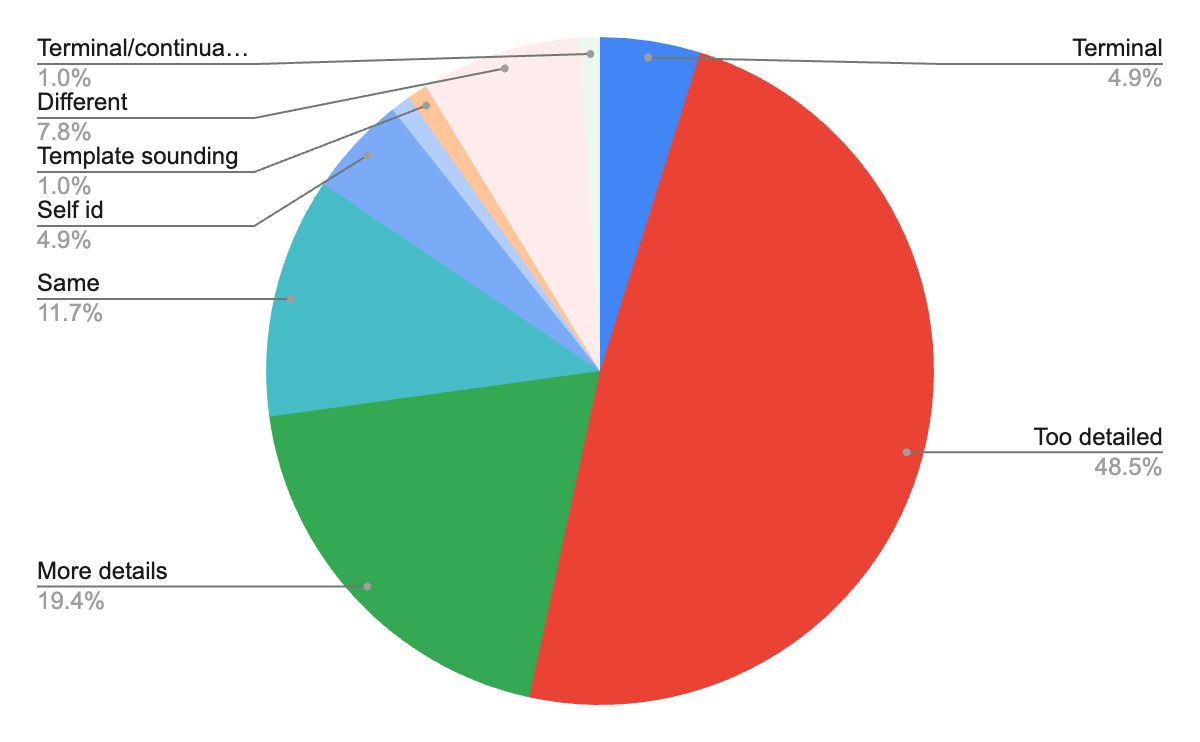
In other words, the generally available models seemed to be suboptimal within this multi-turn conversational setting, which further motivates and demands a robust dataset around this task.
Professional screenwriters from Upwork power the UPHELD dataset
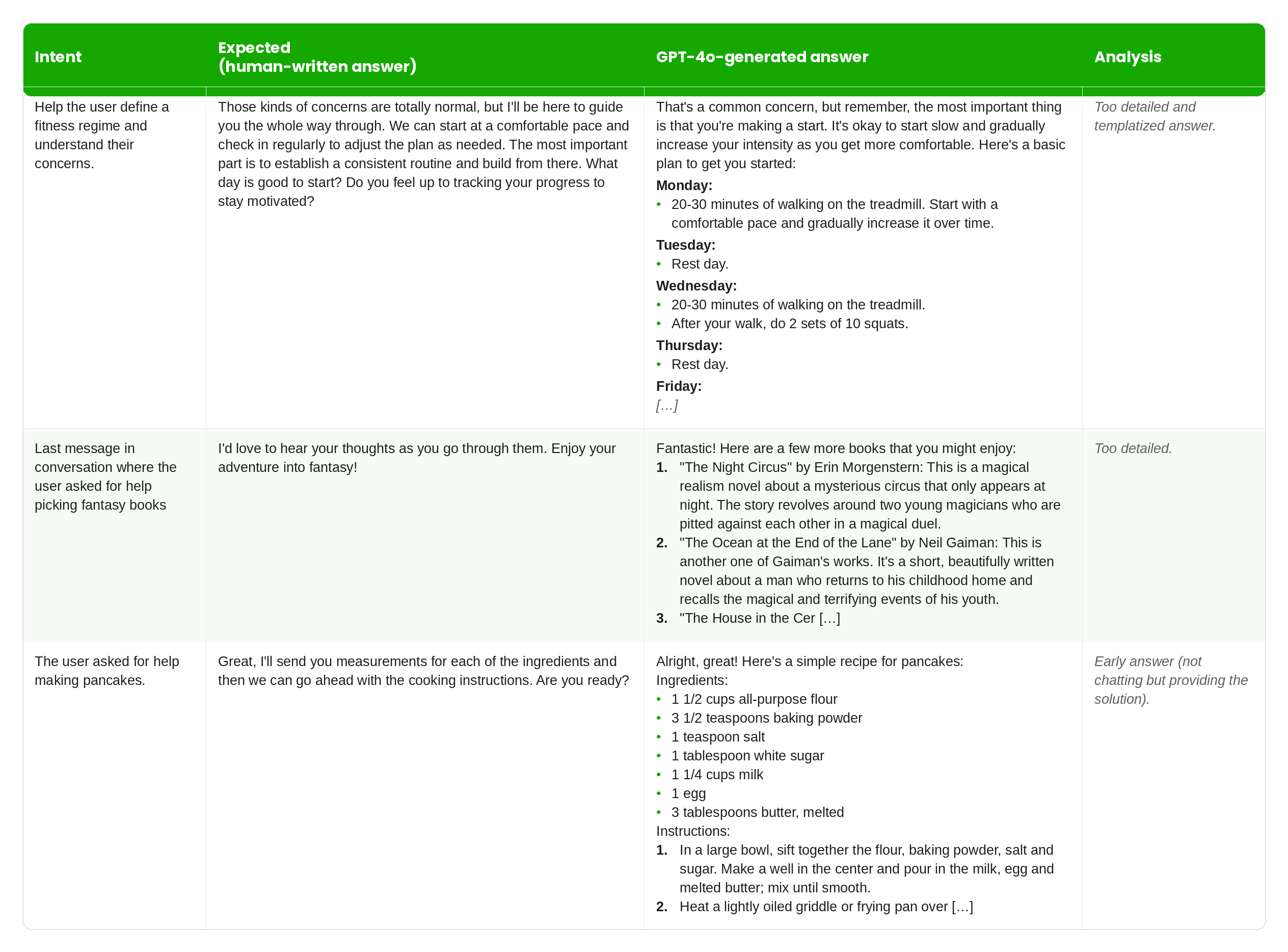
For our dataset, we hired professional writers through the Upwork Marketplace. They were instructed to write multi-turn conversations on various topics considered “general knowledge” between a “regular user” and an “expert.” We explicitly defined these topics to be goal-driven. For example, the conversations were built around tasks like explaining cooking recipes, providing basic mathematics tutoring, or helping users plan trips as a travel agent. Writers were also explicitly instructed to write users with certain personalities, like “annoyed” or “happy.”
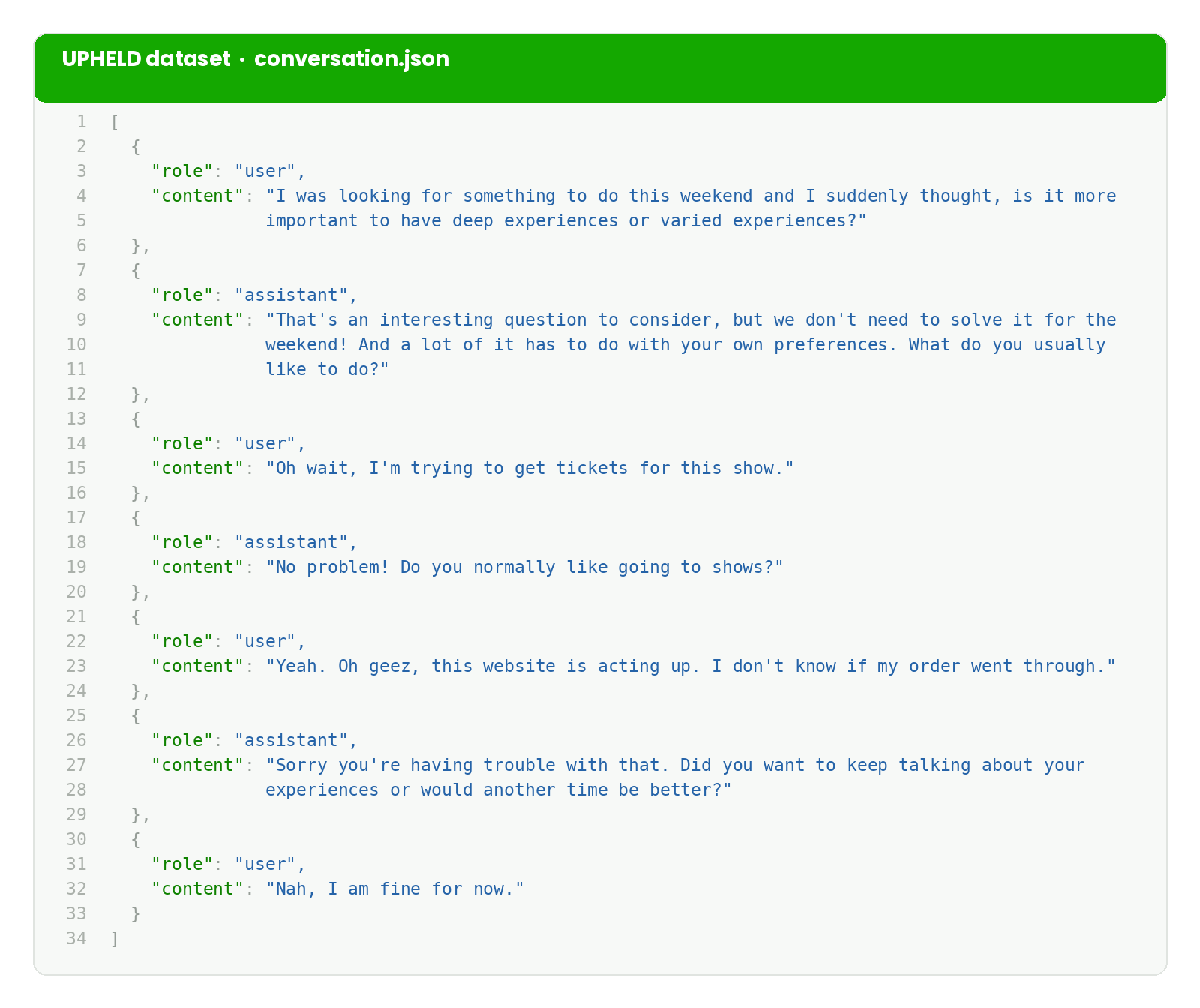
We had collected approximately 1,000 full conversations on various general topics. These conversations were of substantially higher quality than those available in public benchmarks, as evidenced in the example below.
The next step was to use our high-quality collected turns and compare them to the outputs of various LLMs. This allowed us to identify which LLMs could carry on conversations that approached human-level quality. Unfortunately, using LLM judges for this comparison has some pitfalls, as they often hyperfocus on technical correctness. As a result, these judges frequently produce poor scores, as shown in the examples below.

Rather than focusing on facts, the UPHELD dataset focuses on conversational coherence and reasonableness. Because of this, we moved away from LLM-based labeling approaches and contracted professional human labelers to grade these conversations along these axes. UPHELD primarily focuses on three conversational metrics:
1. The ability of an LLM to keep the content of a conversation roughly the same as a human would;
2. The ability of an LLM to keep the style of a conversation roughly the same as a human would, and;
3. The general reasonableness of the LLM response.
Once all these elements were in place, we tasked our human labelers with judging the quality of LLM responses compared to the quality UPHELD’s human responses along the three axes mentioned above. We tested several widely available open-source models, several GPT family models, and a model we called which is a fine-tuned version of Llama-3.1 on the UPHELD dataset. In total, we collected 756 label sets spread across conversations, each labeled by up to five annotators. The total number of unique utterances were 4,777 averaging at 6.3 pairs of user-assistant turns. The dataset is available on our GitHub here.
Raising the standard for conversational AI
One striking way to validate that UPHELD can help developers build better LLMs is to train a model on the conversations in the UPHELD dataset and show that the resultant model is significantly improved. We did exactly that. In Figure 3, we see that Uma v0.5—our model trained on UPHELD data — performed at the same quality as the state of the art models, and significantly better than the base model it was trained upon, when human labelers judged its conversational quality. For Content and Style, Uma v0.5 nearly doubled the quality scores of the base models. This demonstrates that UPHELD contains a strong conversational quality signal that can be leveraged to improve LLM performance.
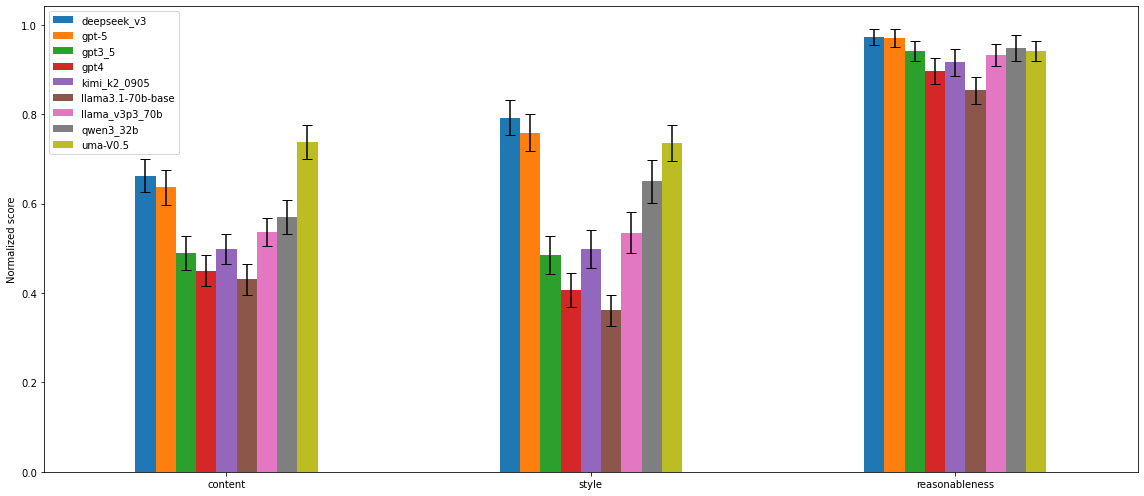
The dataset to support a new age of conversational LLMs
In 2026, companies are looking for more ways to derive value from their LLM deployments with real customers. That value depends on conversational agents that can interact with humans in a natural, fluid way, whereas most current conversational agents still have a distinctive “AI” tone that creates an unfortunate trust gap. UPHELD was created with the specific intention to close that gap, by introducing more “human-like” signals for judging LLM conversational agents.
Built on proprietary marketplace data, Uma is continuously refined to improve model intent, context, and professional nuance. Our investment in datasets like UPHELD reflects a broader focus on advancing custom LLM development to raise performance, reliability, and measurable user outcomes. We believe effective AI at work must be contextual, adaptive, and purpose-built and, by strengthening conversational evaluation within our own ecosystem, we’re raising the bar for human-centered AI that helps businesses and talent achieve better outcomes together.


.svg)
You might like




Join the world’s work marketplace

Find talent your way and get things done.
Find Talent