Data, Machine Learning, and Marketplace Optimization at Upwork (Part 1: User Level Growth)
%20(1)%20(1)%20(1)%20(1)%20(1)%20(1)%20(1)%20(1).png)
How We Use Data and ML to Optimize Conversion and Help Users Grow
This is PART 1 of a four-part series and provides an overview of the challenges we faced and the solutions we built to support user conversion. The other installments are:
.png)
.png)
This article is structured as follows:
1) Motivation: the business impact of core user conversion.
2) Core client conversion: how we use data and machine learning to optimize the client funnel.
3) Core freelancer conversion: how we optimize the freelancer side of the funnel.
The Business Impact of Core User Conversion
A typical funnel that Upwork users go through is illustrated below.
- Visitors come to our site through various landing pages
- They sign up if they like what they see
- In the start phase of the funnel, our client users engage their first freelancer, and our freelancer users sign up for their first project
- In the grow phase, freelancers take on more work and clients engage more freelancers to build their team
We can see that value generation is achieved with every conversion step. The impact is especially high when we succeed in making core users, i.e., when we move users from their start phase to grow phase, we generate an additional 25X in value. In our business, this small group of core users that make up only ~20% of the population, actually generate ~80% of our revenues.
In delivering business impact, the data science team can help solve the core problem of identifying the behavior patterns that characterize core users and formulating machine learning and optimization solutions to encourage these behaviors.

Part 1.1: How we use Data and ML to improve core client conversion through each phase of the funnel
The illustrated funnel presents an overview of some of the latest efforts we’ve pursued and the conversion metrics we hope to move on the client-side of our funnel.

Sign-up
For a potential client to explore a services marketplace like Upwork, the main motivation is staffing. We assume the client comes with the intent to hire, and she will sign up if Upwork seems to have the right freelancers that can get her project done.
Based on this assumption, we built applications for client signup conversion as shown below:

Generally, we can formulate this as a problem of understanding user intent and finding results relevant to this intent. While the notion of relevance is nuanced in the services marketplace context, this can be mapped to the core problem of search that is well-studied in Information Retrieval literature.
One common strategy is to conceive it as a listwise rank optimization problem (listwise learning-to-rank) and to solve it using boosted trees (LambdaMART). For this to work effectively, we need to have data/labels that distinguish results in terms of fine-grained relevance levels (e.g. very relevant, relevant, somewhat relevant, not relevant).
Alternatively, we can also solve it as a click-through-rate prediction (CTR) problem, for which there exist many known solutions based on classification (predict click vs. non-click) or regression (predict the actual click rate). We refer to solutions of this type as one-sided matching to emphasize here, we “only” need to optimize for the visiting user.
The solution to this problem has evolved over the years: First, we started with a ranking formula, which consists of many components including text relevance (TFIDF Similarity) and hardcoded heuristics for demotion (graylist) and promotion (based on freelancer rate, ratings, worked hours). This was hard to maintain and is not built to learn and improve based on user feedback.
Now, our solution is implemented as a two-pass approach:
- First, we apply a recall-oriented formula that combines text relevance with a query-independent model (all predictions are computed offline and written into the index) to quickly generate candidates
- Then we rerank top-k candidates using more advanced features (query- and user-specific signals derived from realtime data streams) to improve precision.
As an example of query-specific features, we use the word embeddings-based similarity between the query and the freelancer profile. For building the first pass model, we use logistic regression to solve for CTR. The second-pass reranking is based on LambaMART and deployed using the SOLR Reranking feature. As for relevance labels, we leverage different click types (clicked results vs. clicked results with dwell-time > 20s vs. clicked to sign up).
As a result of this work, we see significant improvements in:
- Ease of maintenance
- Visitor engagement (CTR, bounce rate, registration rate), and
- Core business success metrics (number and lifetime value of registrations)
Interested to learn more? Please contact our team members working on these efforts:
- Artem Moskvin, Ivan Portyanko, Yongtao Ma: Machine learning based-ranking for search and browsing on Upwork’s visitor sites.
Start
The process of hire conversion that we aim to support in the start phase ranges from posting a job to finding, comparing and engaging freelancers, to increase the likelihood the freelancers will get the job done.
We built three applications to help encourage clients to start hiring:
- Assisted job post creation
- Freelancer search, recommendation and proposal ranking
- A holistic client modeling effort called Client Hiring States
Assisted Job Post Creation
Posting a meaningful and compelling job that freelancers can find and would want to submit a proposal for is a non-trivial task in a complex marketplace like Upwork.
We found the biggest challenges include
- How to identify the job category (Upwork supports an ever-expanding list of hundreds of job categories also called services), and
- How to understand the tradeoff between cost and expertise level requirement and ultimately, how to set the budget for the jobs.
To help address these considerations, we rolled out applications shown below:

For solving the latter problem, i.e., calculate and show budget ranges for the desired expertise level, we leverage the vast amount of historical data about job posts, projects, and price.
However, possibly due to the lack of guidance, we found historically, clients struggle with expertise level assessments for their job post. As an example, we found that for all jobs where clients mention “machine learning expert” in their text, only ~40% of them have “Expert-level” as a requirement. The rest are posted as “Entry-level” or “Intermediate-level” jobs.
So we cannot rely exclusively on the level requirement specified by our clients but need to find an alternative way to determine the expertise level needed for each project.
We assume what matters most is the freelancer(s) the client ended up engaging for the project. So we use the expertise level of the engaged freelancers as the basis for price range calculation. But with this, we only shifted the problem to the one of inferring the expertise level of the freelancers.
(We will discuss our technical solutions to modeling various aspects of our freelancers including expertise level and reputation based on client satisfaction in the section on core freelancer conversion.)
The problem of job category prediction is solved within our bigger-scope effort of understanding queries and texts, which we will discuss next.
Freelancer Search, Recommendation and Proposal Ranking
How can we expose freelancers that have the highest chance to be engaged by the client? This exposure is achieved through both client- and freelancer-facing touchpoints as shown below.

One of the core problems in search is text and query understanding. We are taking a hybrid approach, combining state-of-the-art latent representations of semantics (fastText, BERT) with our internal efforts of constructing Upwork’s Ontology, which is targeted to become the de-facto reference for explicit knowledge representation in the online world of work. Using the ontology, we can map strings to things (ontology concepts) that are clients, freelancers, agencies, occupations, deliverables, skills, etc. As shown below, we first apply the step of entity linking using Wikipedia to understand text inputs (search queries, profiles, posts) in terms of Wikipedia entities. Zooming into this step, we can further distinguish between the tasks of (1) acquiring entity-information using Wikipedia Miner, (2) pruning entities that are not related to the world of work, (3) and applying the common steps of mention detection, link generation and entity disambiguation to link text to Wikipedia entities (based on a reimplementation of X-Lisa). Using mappings between the Upwork’s Ontology and Wikipedia, which we computed automatically and partially verified manually, things recognized from texts are finally represented as concepts of Upwork’s Ontology. A challenge we faced is query categorization. For example, if the query is about Mobile Development, the goal is to infer the list of top-k categories that should include Mobile Development and other related categories. We found that both unsupervised (Word2Vec) and supervised word embeddings (fastText) perform poorly with tail queries due to their reliance on and the lack of training data. The accuracy for the entire query set largely improved when we combine fastText’s outputs with the results of our Semantic Service, which infers category information based on linked entities.
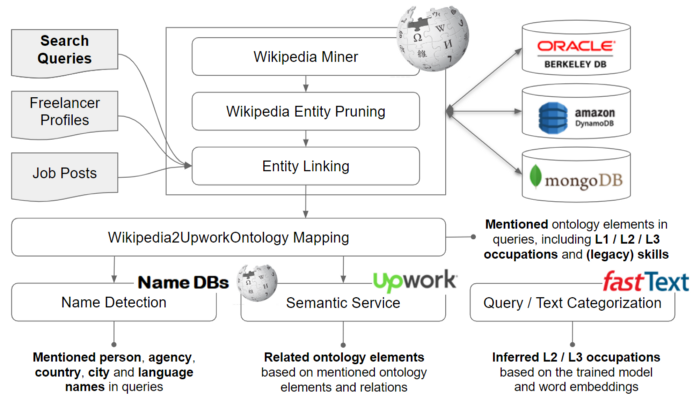
Understanding queries in terms of entities and categories enables tailored ontology-based search strategies, e.g. dedicated matchers and rankers for name, location, and skill. For example, we spent a considerable amount of effort to implement skill-based matching. Given a job, the task is to extract key terms and skill requirements to find and rank freelancers that (1) have matching skills, (2) their skills are “vetted” by clients on Upwork, and (3) clearly present and explain matches to our clients. The screenshots below show an example of skill-based matching in action. The solution to this is a culmination of a long line of work that started with key term extraction for job posts via entity linking. Then, we learned to infer categories and skills from job posts. The most interesting challenge was to vet/validate and quantify freelancer skill strength based on their proposal and work history. We solved it as a probabilistic generative modeling problem à la TrueSkill 2, where every job is considered as “a competition” with the clients being the judges. As illustrated below, the skill representation of a freelancer profile includes (1) asserted skills the freelancer claims to have, (2) skills inferred from their profile, (3) and skills validated through their work history. We incorporate all of these into a semantic search module that was implemented as an extension of SOLR, our off-the-shelf search backend. The result is “things, not strings”: instead of presenting freelancers that were textual matches to the job post, we significantly increased client’s engagement and invites as they see freelancers, who are “proven” be qualified based on implicit competition-related signals.


On the visitor site, we were entirely focused on the client and optimize for signup conversion. But now, to help the client hire, we want to find freelancers that match their job requirements, and we also want them to be interested in the job. Known search and recommendation techniques are effective for building one-sided solutions but to support this, they have to be extended to solve the problem of two-sided matching. Beyond the client and job requirements, a good match takes into account the freelancers’ interest so that the client’s job invites are well received, the freelancers she interviews are highly engaging and the ones she hires, are able to get the work done at her satisfaction. A machine learning architecture proposed for and applied to this problem at Upwork is based on building separate models for preferences of both the client and freelancer sides and constructing a two-level model for ranking. Besides model architecture, we find the keys to improvement lie in the extraction of user preferences and the matching and feature encoding of pairwise preferences.
From Hiring to Execution and Mid-job Intervention
A successful start should go beyond hiring. Our aim is to extend the support to successful job execution. Towards that end, we pursue a holistic client modeling effort called Client Hiring States:
- Job quality and client intent: using job applications as a signal of freelancer interest and interview as a signal of the client intent, we built classification models to infer whether the client cares to write an attractive job post, and is ready to hire.
- Fill: given the client, the job post and the applicant pool, we are building a model to predict the probability that the job will be filled and their magnitude of change if we were to add a specific type of applicants to the pool
- Churn: given the hired freelancer and mid-job interactions, we predict the risk of client churn using known signals of low satisfaction and churn as the model target (hire but no spend, spend but no feedback).
Given these insights into our client, we implement targeted policies (high touch support and intervention) to directly increase the chance of fill and mitigate the risk of churn.
Interested to learn more? Please contact our team members working on these efforts:
- Eva Mok, George Barelas, Lei Zhang, Quang Hieu Vu, Siddharth Kumar, Spyros Kapnissis, Thanh Tran: Text and query understanding — how we use knowledge graph, entity linking and semantic text labeling at Upwork.
- Eva Mok, George Barelas, Lei Zhang, Quang Hieu Vu, Silvestre Losada, Thanh Tran: Semantic search — category- and skill-based matching over SOLR.
- Pablo Celayes, Sibo Lu: Client modeling — how we capture our clients’ hiring states and help them hire.
Grow
We help our clients to grow by sending them recommendations to extend their bench with freelancers that suit various job functions (cross-sell) and job levels (up-sell). Example recommendations are shown in the emails below.
For freelancer similarity computation, we use standard text embeddings (Word2Vec, Doc2Vec) for the textual part and also, leverage the user click log and the rich graph-structured context we can derive from that to learn object embeddings. We found this is an advancement over traditional collaborative filtering based “similar items” such as “user who bought this also bought”, where a single user behavior (e.g. purchase) forms the basis of the similarity. With this approach of learning object embeddings using neural networks, we learn a distributed representation for objects (e.g. freelancers, application, skill, etc.) to capture similarity from different views. For the application of freelancer recommendation, the similarity between two freelancers A and B is based on:
- A and B were clicked, viewed or saved in the same session.
- A and B were clicked, viewed or saved for the same search query.
- A and B were hired for jobs that required the same skill.
The click log we are using for (1+2) is basically sequence data so we apply Deepwalk as the method for learning embeddings. For (3), we found LINE to be more effective given the data is a densely connected network.
We also developed a model for a given client, predicts their next jobs and the skills required for these jobs. We formulate skill prediction as a probabilistic inference problem: what’s the probability a client will post a job with a skill X (future_skill), given she previously posted a job with the skill Y (past_skill)? While we might not know this for a particular client, we can learn from the behavior of other clients and make an informed guess via Bayesian inference:
P(future_skill | past_skill) = P(past_skill | future_skill) * P(future_skill) / P(past_skill),
where the likelihood P(past_skill | future_skill) and priors P(future_skill)/P(past_skill) are estimated from the data based on all historical jobs and their skills.

Interested to know more? Please contact our team members working on these efforts:
- Lei Zhang: Learning embeddings for freelancers, jobs and other objects in the world of labor.
- Artem Moskvin, Yongtao Ma: Complementarity vs. substitutability of services and skills in labor marketplaces.
Part 1.2: Use Data and ML to Improve Core Freelancer Conversion
An overview of our efforts in core freelancer conversion is shown here.
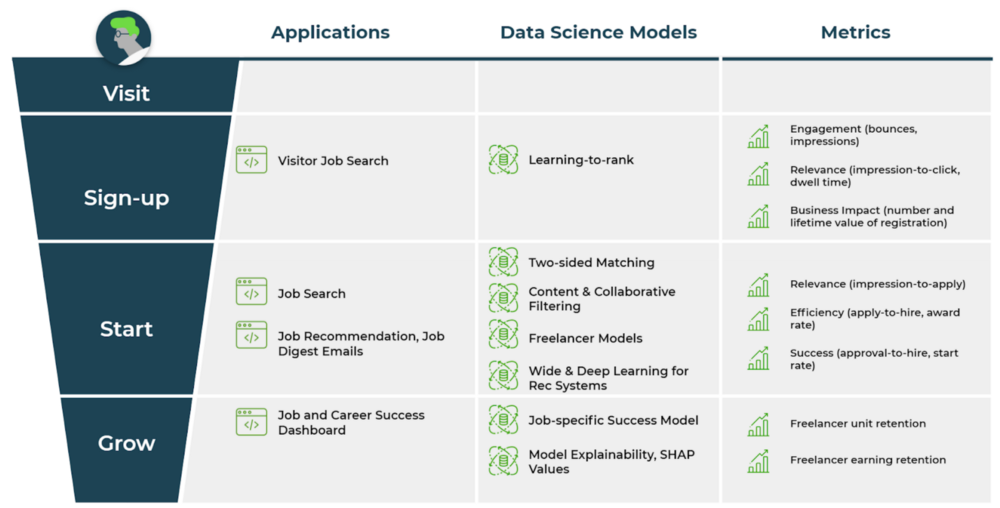
Sign-up
Similar to the sign-up conversion on the client-side, we face a one-sided match problem where the goal is to present the right jobs for our visiting freelancers. We assume for a freelancer to signup, she wants to see that Upwork provides a wide range of options for flexible work, from low-commitment moonlighting to full-time and long-term remote options with earnings that are comparable to the traditional alternative.
Our first solution, Visitor Job Search (shown below), was built to take only two main factors into account: text relevance and recency. A simple rank formula was designed and manually tuned around these factors. The latest iteration of this solution is based on a two-pass learning-to-rank based approach. Candidates are selected with a quick query-independent first pass, which is re-ranked by a query-dependent second pass based on a more advanced model with richer features.
Main features used are related to recency, location, and quality (description length, opening budget). Quite interesting and effective is one type of features that intuitively, captures the price difference the client expects to pay compared to similar jobs with the same skill requirements. Jobs that pay more than skill-based averages are found to be more attractive to freelancers. As query-specific features, we use distance features such as the semantic similarity between query and result title. For learning the model, we derived different levels of relevance using skipped results, clicked results, and various actions performed on the clicked results, e.g. clicked results for which we observed the sign-up action have the highest level of relevance. We found this offline optimization based on NCDG help to obtain results that are in line with the online business metrics we aim to move: with machine learning ranking, visitors were more engaged (higher total number of impressions and clicks) and the daily registration rate largely improved.

Start
Analogous to the client funnel, the central theme for all the applications below is two-sided matching. We want the jobs and their clients to be attractive and relevant to the freelancer’s interest. On the other hand, the freelancer’s ability should also match the job's requirements so that the client would accept their application, make a hire and be satisfied with job deliveries.

For computing recommendations, we explored different known techniques and ended up with a hybrid of content-based and collaborative filtering. Using the explicit client ratings provided by the freelancers at the job completion time, we construct a matrix with the freelancer as user and client as item. Then, we run matrix factorization to obtain the latent user and item vectors. With the dot product of these vectors, we predict the rating for a given freelancer and client pair. However, we found that for both the client and freelancer funnels, the predicted ratings are useful but not the most crucial signals for recommendations. Our recommendation problems are more complex and the targets are often not simply to predict what the freelancers like, but to encourage them to perform certain actions that have different utilities. To solve this type of problems, our standard approach is to formulate a linear target function, which encodes the utility for the desired actions. We derive the utility of individual actions using click log-based estimates of their attributed impact on the business target. For instance, given the target is hiring conversion, we derive the utility of the job application action based on the average number of applications it takes (among others) to observe a hire. For maximizing the user’s utility, ratings play a role, but there are much stronger content-based and two-sided match signals including semantic matching of job vs. freelancer profile and job vs. model of career interest (see freelancer models below).
Technique aside, what helped us to make the biggest leap is understanding the challenge in job start and breaking it down to the problems of building freelancer models to capture distinct aspects.
- Commitment/Availability: we build a model to predict the probability the freelancer would accept a job invite or offer.
- Interest: based on clicks, applications, and jobs in the past, we build models of the freelancer’s past interest and future career ambition.
- Skills and Expertise Level: given the freelancer’s skills, our goal is to vet them using clients as judges. To accomplish that, we conceive every job as a competition and client’s historical decisions (invite, interview, hire, reject) as signals for quantifying the freelancer’s expertise level in each of the skills required in these competitions (see TrueSkill 2 discussion above).
- Reputation: every freelancer has a Job Success Score, which, similar to the system of star rating on other platforms, is based on explicit feedback. As usual, explicit feedbacks are only reliable when combined with implicit feedback derived from user behaviors. Besides this, we are also solving the cold-start problem of predicting the reputation/quality score for new users.
- Value and Retention Impact: the holy grail in freelancer modeling is to predict the value a freelancer generate (earnings) and their success in retaining clients. While we found it is possible to have separate models that capture these aspects individually, it is difficult to combine them into a single target. Value generation is often short-term, which may come at the cost of long-term client retention.
Leveraging these freelancer insights, we generate features to predict and decompose job fitness into the dimensions of interest and expertise and promote freelancers with high commitment, a stellar reputation and greater value and/or retention impact.
The presented solution is “conventional”, relying a great deal on domain understanding, hand-crafted features, and models tailored to the business problem. We believe this modeling approach will remain to have merit due to the business need of keeping the model explainable, and decomposing the solution into intuitive levers for our users to understand and control, e.g. to sort recommendations by availability, expertise and reputation, However, we also explore the wide and deep approach for building recommender systems. Given the learnings and success we already had with using neural networks for object embeddings (see discussion above), it is easy to believe the deep part of this model will help us learn and derive features and representations that are superior to the ones we manually put together so far.
Interested to know more? Please contact our team members working on these efforts:
- Igor Korsunov, Ivan Portyanko, Yongtao Ma: Job search and recommendations at Upwork.
- Alexander Krainov, Amro Tork, Le Gu, Nimit Pattanasri, Thanh Tran: Freelancer modeling — how we model success factors and help freelancers become more successful on Upwork.
Grow
We help our freelancers grow by presenting a stable stream of job recommendations (earning opportunities) as well as providing advice for our freelancers to become more successful with specific jobs and their overall career on Upwork. The screenshots below show our Freelancer Job Success Dashboard that aims to provide that guidance (as of now, this dashboard is only available for our support team and we plan to release a simplified version for our freelancer users).


We can see the Freelancer Models discussed above are also being used to deliver insights for our freelancers to understand job and career success in terms of their skills, expertise level, quality and reputation from the platform and client viewpoints.
For computing job-specific success factors, we built a model to predict whether a freelancer will be hired for a given job. Leveraging recent techniques for model explainability, we break down how the model works for an individual prediction. With SHAP Values (SHapley Additive exPlanations), we can see how core features/factors impact the success for every job our freelancer apply to and derive job-specific recommendations and career advice based on these factors.
Interested to know more? Please contact our team members working on these efforts:
- Alexander Krainov, Le Gu, Nimit Pattanasri: Model explainability in action — using SHAP Values to generate job success recommendations for Upwork freelancers.



.jpeg)
%20(1).jpg)