Find the Best Artificial Intelligence Jobs
Check out a sample of the 2,361 Artificial Intelligence jobs posted on Upwork
E-commerce AI Chat Expert
Fixed-price
Experience level
We are seeking an expert to develop and implement AI chat solutions for our e-commerce platform. We already have the project done. Sto…
AI Automation Specialist for Internal Operations & Workflows
Hours needed
Duration
Experience level
We’re looking for an experienced AI Automation Developer to help us streamline and automate core operational processes. While our team…
Need an AI/automation specialist for a workflow review
Fixed-price
Experience level
I've built out an AI/automation workflow (n8n + AI agents) and want a second pair of expert eyes on it before I move forward — mainly l…
Business Software Development and AI Solutions
Hours needed
Duration
Experience level
We are seeking a skilled freelancer to assist with various business software development projects, software integrations, and AI soluti…
n8n Expert | AI Automation Workflow Developer
Fixed-price
Experience level
We're looking for an experienced n8n Expert and AI Automation Workflow Developer to build and optimize intelligent automation workflows…
Ai Automation for marketing agency
Fixed-price
Experience level
Hi! We're a digital marketing agency looking to fold AI automation into the way we operate, and we'd like to speak with you about it.…
Junior AI Product Engineer
Hours needed
Duration
Experience level
We are an early-stage startup seeking a Junior AI Product Engineer to join our team. The role involves developing AI products using Pyt…
AI-Driven Storytelling Platform Development
Hours needed
Duration
Experience level
We are building an AI-driven platform for personalized children's storytelling. The project involves developing a web and mobile applic…
Fractional Partner / Senior Consultant to Design and Launch Global AI‑Driven Consulting Firm
Hours needed
Duration
Experience level
Overview I’m building a global, remote consulting firm that helps small, mid‑market, and selected enterprise clients use AI and data to…
£100 Paid 2-hour University Research Study for Freelancers Using AI for Collaborative Work
Fixed-price
Experience level
We are inviting experienced freelance knowledge workers to take part in a collaborative online research workshop conducted by researche…
can earn $35–$60/hr.
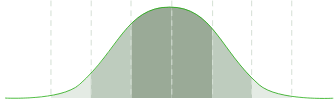
$35$60
Median hourly rates (USD)
How to Become a Freelance Artificial Intelligence Engineer
Advances in technology allow specialists to understand, build and deliver solutions designed to make life—and business—much easier including artificial intelligence.
If you possess computer programming skills and have a high comfort level developing algorithms, data analysis, neural networks, robotics, or natural language processing, you may have what it takes to become a freelance artificial intelligence engineer on Upwork.
What does a freelance artificial intelligence engineer do?
Freelance artificial intelligence engineers handle the development and programming of algorithm networks that operate like the human brain in order to complete repetitive and complex tasks. Artificial intelligence solutions are incorporated into business and consumer-oriented solutions using machine learning. The result is increased automation, streamlined operations, and greater accuracy.
Data scientists specializing in building artificial intelligence solutions must be familiar with building algorithms, computer programming, statistical analysis, infrastructure development, and API development. These skills allow freelance AI engineers to be deployed in any industry for virtually any company developing AI solutions.
What skills do I need to become a freelance artificial intelligence engineer?
The skills to seek career opportunities as a freelance artificial intelligence engineer are similar to any other technology discipline. Freelancers specializing in artificial intelligence and machine learning algorithms can work on a number of projects requiring a deep understanding of data analytics, data mining, data modeling, and various software frameworks.
Common skills an ideal candidate responding to a freelance artificial intelligence engineer job description should possess include:
- Programming skills. AI engineers should be well-versed in several computer programming languages, Python, Java, and C++.
- Technical skills: In addition to programming skills, knowing the fundamentals of the field of AI and machine learning will make any data engineer a huge asset to the team.
- Mathematical skills. To design and build different AI models, freelance engineers should have knowledge of statistics, linear algebra, and probability.
- Big data skills. Deploying artificial intelligence solutions requires a large volume of data. With this in mind, freelance AI engineers should be familiar with big data technologies such as Apache Spark, Hadoop, and Cassandra.
- Problem-solving skills. Solving problems, decision-making, and anticipating problems and their solutions before they appear, is an essential skill freelance machine learning engineers must have.
- Database skills. Building and deploying algorithmic networks associated with artificial intelligence solutions requires extensive knowledge of databases. With large amounts of data and utilizing that data across applications in real-time, configuring databases that support these solutions is a must when deploying successful AI solutions.
What are the core freelance artificial intelligence engineer job responsibilities?
Clients require the freelance artificial intelligence engineers they hire to handle a number of duties within the field of AI. While specific duties may vary from client to client and project to project and range from programming to data analysis.
The core responsibilities artificial intelligence engineers must possess include:
- Collaborate with cross-functional teams throughout the organization to understand current environments and identify opportunities to employ AI solutions
- Lead brainstorming session with AI team to find solutions to existing operational problems
- Engage senior management, product managers, programmers, and other stakeholders to determine requirements for AI-based solutions
- Research the competitive landscape and establish benchmarks for all future AI-based projects
- Document progress and distribute regular reports to senior management on AI-based projects
- Train staff in using relevant programming tools to support AI-related projects.
Should I get a degree or certification to become a freelance artificial intelligence engineer?
In addition to developing your skills and gaining experience through employer and client work, it is necessary to obtain a degree and/or professional certification to help your Upwork profile stand out. While some freelance AI engineers may engage in client work without a formal education, the discipline is so specialized that a degree is necessary in order to maximize opportunities as a freelancer.
Some examples of popular degrees or certifications that are helpful to become a freelance artificial intelligence engineer include:
- An associate, bachelor’s degree, or master’s degree in computer science, engineering, data science, mathematics, statistics, physics or an equivalent in a related field of study from an accredited college or university
- IBM Applied AI Professional Certificate—offered by IBM through Coursera
- Machine Learning by Stanford University—offered by Stanford through Coursera
Jumpstart your freelance artificial intelligence engineer career on Upwork and start looking for your first job. Eager to learn more about freelance artificial intelligence engineer jobs on Upwork? Check out these additional resources:
Upwork is not affiliated with and does not sponsor or endorse any of the tools or services discussed in this section. These tools and services are provided only as potential options, and each reader and company should take the time needed to adequately analyse and determine the tools or services that would best fit their specific needs and situation.
Your next job starts right here
Set up a free profile to showcase your skills, experience and desired pay rate to clients. You choose the payment method that's best for you to easily get paid for your work.
Find workGives you security and peace of mind