You will get 90-Minute LLM Agent Trace Triage (Cut Cost/Latency Without Code Access)


Project details
Send me one or two real execution traces from your LLM agent (logs/transcripts). I’ll identify exactly where you’re burning tokens, time, and tool calls, and give you a prioritized fix list you can implement immediately—no repo access required.
This is designed for teams who are overpaying on every run due to context bloat, tool loops, retries, poor routing, or avoidable recompute.
What you get (deliverables)
-Top 10 waste drivers found in your trace (token + latency + tool overhead)
-Prioritized fix plan (highest ROI first) with concrete changes to prompts/tool contracts/routing
-Guardrails pack: stop conditions, max tool calls, retry policy, and loop prevention rules
-Quick impact estimate (expected % improvement ranges based on trace patterns)
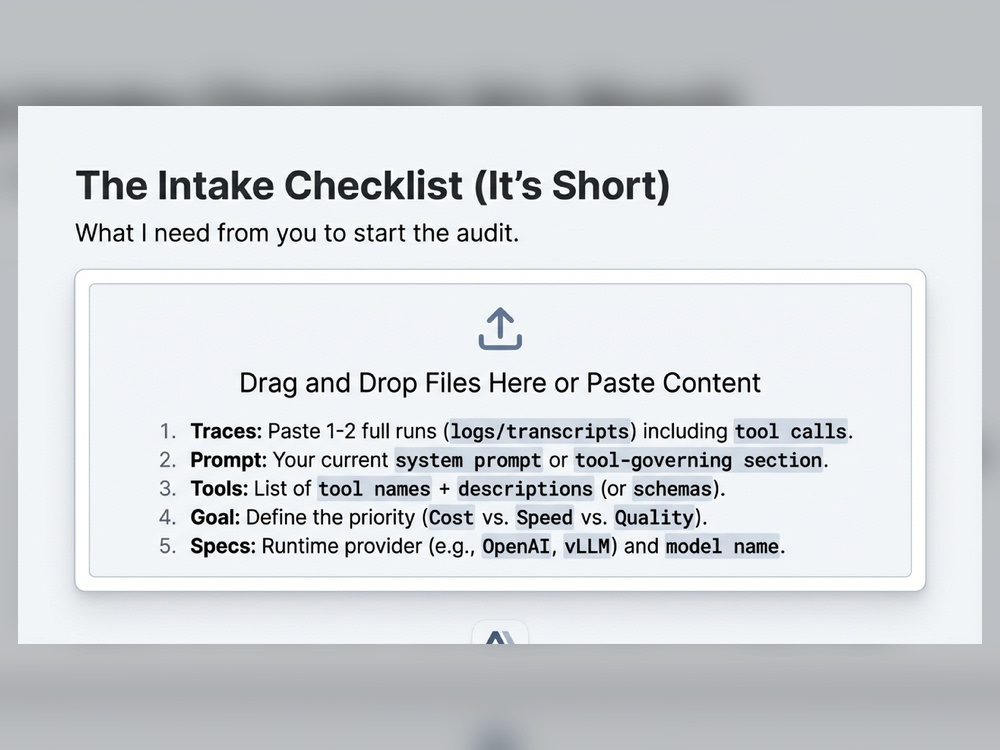
What I need from you (intake)
-Paste 1–2 full traces (or upload logs) of a typical run, including tool calls and outputs if possible
-Your system prompt (or the part that governs tool use)
-Tool list: names + short descriptions (or schemas if you have them)
-What matters most: cost, TTFT, E2E time, tool reliability, or quality
-Your runtime/provider (OpenAI, Anthropic, vLLM, SGLang, etc.) and model name
This is designed for teams who are overpaying on every run due to context bloat, tool loops, retries, poor routing, or avoidable recompute.
What you get (deliverables)
-Top 10 waste drivers found in your trace (token + latency + tool overhead)
-Prioritized fix plan (highest ROI first) with concrete changes to prompts/tool contracts/routing
-Guardrails pack: stop conditions, max tool calls, retry policy, and loop prevention rules
-Quick impact estimate (expected % improvement ranges based on trace patterns)
What I need from you (intake)
-Paste 1–2 full traces (or upload logs) of a typical run, including tool calls and outputs if possible
-Your system prompt (or the part that governs tool use)
-Tool list: names + short descriptions (or schemas if you have them)
-What matters most: cost, TTFT, E2E time, tool reliability, or quality
-Your runtime/provider (OpenAI, Anthropic, vLLM, SGLang, etc.) and model name
AI Development Type
Recommendation System, Software MaintenanceAI Tools
Azure Machine Learning, PyTorch, TensorFlowAI Development Language
PythonWhat's included $199
These options are included with the project scope.
$199
- Delivery Time 1 day
Optional add-ons
You can add these on the next page.
Second Trace Review
(+ 1 Day)
+$149Frequently asked questions
About Sean
Senior AI Advisor | LLM Agent Cost/Latency Optimization | Loop Fixes
Continental, United States - 3:43 pm local time
I help organizations use AI and automation to eliminate manual work, simplify operations, and ship practical tools that people actually adopt. I have 18+ years in enterprise IT leadership (Fortune 4), so I bring real-world execution discipline: reliability, security, governance, vendor constraints, and change management—without slowing things down.
What I do:
-AI automation & agents: end-to-end workflow automation, AI assistants, agentic workflows with logging/guardrails/human review.
-AI MVP builds: working MVPs and internal tools integrated with your stack; lightweight backends, dashboards, rapid iterations.
-Systems & SOPs: simple SOPs, checklists, handoffs, escalation paths to reduce chaos.
-IT strategy & vendor optimization: infrastructure modernization, cost control, vendor/licensing strategy, contract consolidation.
-GTM support: offer packaging, pricing, messaging, and simple sales/ops systems.
Why work with me:
-18+ years leading critical IT systems and teams, including 24x7 operations.
-$1M+ cost savings delivered through vendor strategy and negotiation.
-Comfortable bridging strategy and execution: define the plan, then build the thing.
-Clear communication, tight scope control, predictable delivery.
If you have a workflow that’s messy, expensive, or slow—or an AI product you want to get into users’ hands—send me the context and I’ll recommend the fastest path to a working result.
Steps for completing your project
After purchasing the project, send requirements so Sean can start the project.
Delivery time starts when Sean receives requirements from you.
Sean works on your project following the steps below.
Revisions may occur after the delivery date.
Share 1–2 traces, system prompt, tool list, goals, and model/provider.
I review your traces to identify token bloat, tool loops, latency hot spots, and routing issues. I confirm success criteria (cost vs speed vs quality) and establish a baseline from your run data.
I analyze where tokens/time are wasted and why it’s happening.
I map the execution path step-by-step, flag redundant context, repeated tool calls, bad retries, prompt/tool contract issues, and avoidable recompute. Output is a prioritized list of issues with evidence from the trace.