You will get a clear action plan to fix your broken document extraction pipeline
Top Rated
Top Rated
Project details
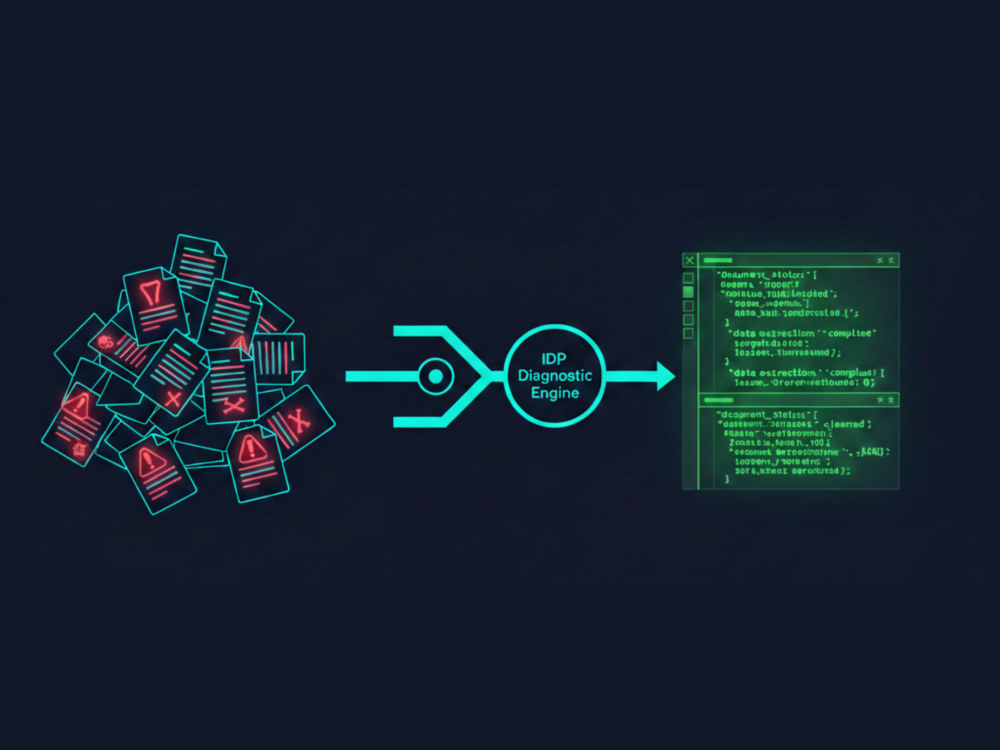
Most document extraction pipelines fail not because of bad tools, but because of misdiagnosed problems. Layout drift, inconsistent headers, merged cells, and edge cases all look the same from the outside but require completely different fixes.
I review your current pipeline, identify the exact failure points, and deliver a written action plan with implementation steps — so you know precisely what needs to be fixed and how, before spending money on development.
Top Rated Plus | 100% Job Success | 2 years building production IDP systems
I review your current pipeline, identify the exact failure points, and deliver a written action plan with implementation steps — so you know precisely what needs to be fixed and how, before spending money on development.
Top Rated Plus | 100% Job Success | 2 years building production IDP systems
AI Development Type
Software MaintenanceAI Development Language
PythonWhat's included $250
These options are included with the project scope.
$250
- Delivery Time 3 days
- Number of Revisions 1
- Model Documentation
Frequently asked questions
5 reviews
(5)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
DP
Dan P.
Jun 19, 2026
Help develop a script that automates converting lab analysis results into output reports for clients
Subhajit built a Python script that automates converting our lab analysis results into structured client reports. Our documents come in varying formats and he handled the extraction logic cleanly across all of them. The output has been consistent and reliable, it's saved our team a significant amount of manual work. Clear communication and good technical judgement throughout.
DP
Dan P.
Jun 19, 2026
Python Developer for OpenAI API Integration in Document Extraction Workflow
We asked Subhajit to evaluate and prototype OpenAI API integration for our existing PDF document extraction workflow. He built a working proof of concept, tested it against our real documents, and gave us a clear technical recommendation on whether to proceed. His understanding of extraction pipelines and specifically when an LLM adds value versus when it doesn't was exactly what we needed to make the decision. Thorough, honest, and well-documented work.
DP
Dan P.
Jan 16, 2025
Software development - Create a front-end for our data extraction tool
I've worked with Subjahit on multiple projects, and he always delivers great results. His communication is clear, he takes feedback well, and he consistently finds effective solutions. It's been a pleasure working with him.
DP
Dan P.
May 13, 2024
Write a python script that extracts table data from PDF files into formatted excel tables
Fantastic contractor and a pleasure to work with.
SK
Sambit K.
Apr 23, 2024
Python Developer for Trading Project
Subhajit's professionalism, meticulous attention to detail, and expert handling of our project were apparent from the outset. The results delivered were truly exceptional. Communication was consistently seamless, and Subhajit was always receptive to feedback, making adjustments promptly when required. I wholeheartedly recommend Subhajit to anyone in search of premium freelance services.
About Subhajit
AI Document Processing | Data Extraction & Automation | OCR, IDP, RAG
100%
Job Success
Durham, United Kingdom - 9:20 pm local time
I build an auditable document-processing layer that converts real, messy, unstructured data into structured data and makes your RAG system actually work. My longest engagement ran two years on retainer — a water consultancy processing lab reports across 10+ changing layout variations, where I cut manual data entry by 75%. Based in the UK.
Most clients find me after something that was partly working stops working. The extraction script handled 80% of documents fine, then broke on the rest and the team can't explain why. That's the failure mode I'm specifically set up to prevent.
────────────────────────────────────────
HOW I WORK
My job is to know the failure modes before we write the first line of code.
I start with the simplest approach and iterate from there. Over-engineering is the most common failure mode in document processing — reaching for LLMs when regex would do, or building custom infrastructure when a single API call would do.
My pipeline development follows the same sequence every time:
1. Define the schema first
If I can't describe what clean output looks like, extraction will always be unreliable. Pydantic schema before touching any document.
2. Establish a regex baseline
A deterministic check tells me exactly where the hard cases are before introducing any probabilistic tool.
3. Introduce LLMs incrementally
Start with the simplest prompt possible. Iterate against real documents. If a simpler rule-based approach gets you 90% of the way, I'll say so — and we'll skip the LLM.
4. Apply layout detection last
Only where variation genuinely requires it.
This sequence keeps pipelines predictable, testable, debuggable, and maintainable. The system that breaks on document 47 with no explanation is the most common complaint I hear from clients who've tried other solutions first.
────────────────────────────────────────
WHAT CLIENTS SAY
"Thanks to Subhajit's work, we are saving countless hours having to manually enter results into our own template."
"Subhajit's professionalism, meticulous attention to detail, and expert handling of our project were apparent from the outset."
"He always delivers great results. His communication is clear, he takes feedback well, and he consistently finds effective solutions."
────────────────────────────────────────
WHAT I DO
IDP Diagnostic & Action Plan — fixed price
If your document pipeline is failing or underperforming, I audit your current approach, identify failure points, and deliver a written action plan with execution steps. Implementation is optional and available on request.
Document Extraction Pipeline
I build systems that extract structured data from PDFs, invoices, lab reports, contracts, and email attachments. They handle layout variation and format drift — the things that break simpler solutions in production.
System Integration & Ongoing Support
I connect extraction pipelines to downstream systems: Excel, databases, APIs, and internal tools. Retainer support is available as your document types evolve.
────────────────────────────────────────
RESULTS
- Cut manual data entry by 75% for a water consultancy processing lab reports across 10+ changing layout variations
- Maintained and expanded over a two-year retainer — the system became central to the client's daily operations
- Extended the pipeline to process email attachments directly, removing a manual download-and-upload step
────────────────────────────────────────
TECHNICAL STACK
Document Processing: pdfplumber, PyMuPDF
LLMs & Extraction: OpenAI API (GPT-4o-mini)
Validation & Structure: Pydantic, JSON schema
Backend & APIs: FastAPI, REST API design
Databases: PostgreSQL
Version Control: Git, GitHub
────────────────────────────────────────
LET'S START SMALL
Start with a Diagnostic Session. Fixed price: $250.
You share your documents and describe the problem. I review your current approach, identify the exact failure points, and deliver a written action plan with implementation steps.
No long commitment. If you choose to proceed, we scope the full pipeline together. If not, you still have a concrete plan you can share with anyone.
Send me a message with a brief description of your document problem. I'll tell you within 24 hours whether I can help and how.
Steps for completing your project
After purchasing the project, send requirements so Subhajit can start the project.
Delivery time starts when Subhajit receives requirements from you.
Subhajit works on your project following the steps below.
Revisions may occur after the delivery date.
I review your sample documents and current pipeline approach
I analyse your documents and current pipeline approach, identifying patterns, edge cases, and failure modes.
I identify failure points and root causes
I pinpoint the exact root causes — layout drift, boundary-detection issues, schema mismatches, or extraction-logic gaps.