You will get a RAG memory system so your AI never forgets
Project details
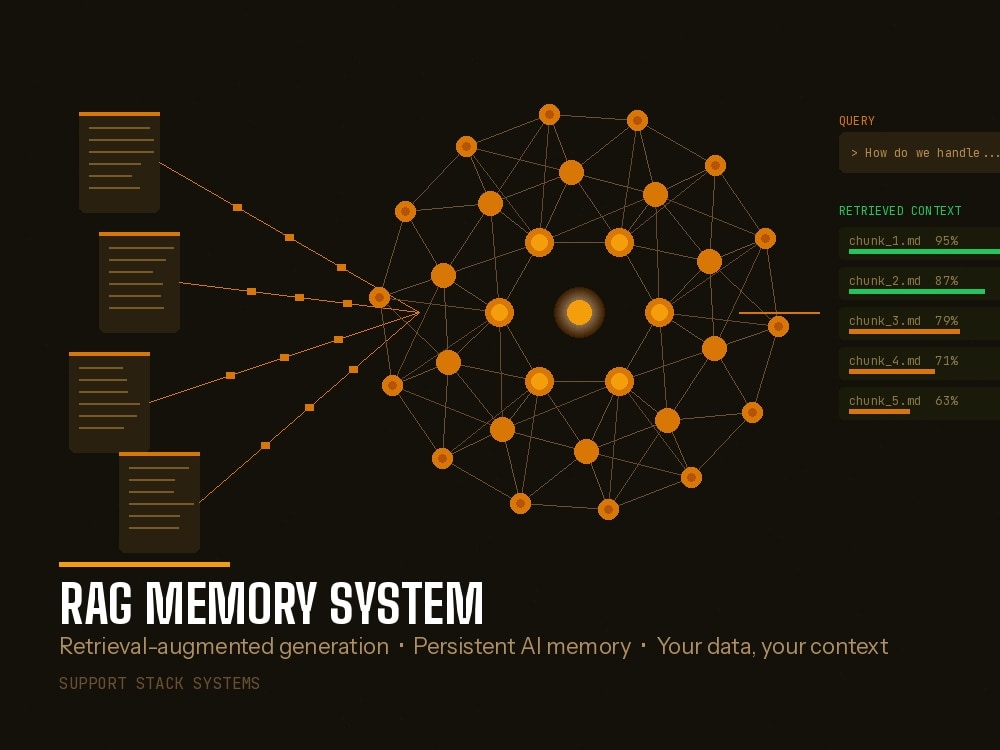
I will build a multi-layer memory infrastructure that gives your AI agents persistent context, long-term knowledge retrieval, and cross-session continuity. This is not a simple document search. It is a full memory stack: RAG retrieval with vector embeddings and semantic search, a pooled agent cache that saves API tokens by avoiding redundant reads, long-term session logging with structured notes, bidirectional sync between machines, and automatic enrichment with metadata tagging. The retrieval layer uses vector embeddings for semantic search so agents find relevant context by meaning, not just keywords. I built and operate this system live across 5 autonomous agents on a production VPS. Agents share a pooled cache with 54 tests passing and zero external dependencies. A streaming watcher re-indexes new memories within seconds. The RAG layer uses OpenAI text-embedding-3-small over a SQLite vector store with scoped retrieval per agent. Your AI systems get persistent memory that survives sessions, shares across agents, and retrieves what matters fast.
AI Algorithms
Large Language ModelAI Applications
AI ChatbotAI Development Language
PythonAI Tools
Azure OpenAI, Hugging Face, NVIDIA AI PlatformAI Models
ChatGPT, GPT-4, OpenAI CodexWhat's included
| Service Tiers |
Starter
$750
|
Standard
$3,000
|
Advanced
$8,000
|
|---|---|---|---|
| Delivery Time | 5 days | 14 days | 30 days |
Number of Revisions | 1 | 1 | 2 |
AI Model Integration | - | - | - |
Batch Normalization | - | - | - |
Database Integration | - | - | - |
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | - | - | - |
Model Monitoring | - | - | - |
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | - | - |
Setup File | - | - | - |
Source Code | - | - | - |
Frequently asked questions
About Sadie
Autonomous Agents Engineer | AI Infrastructure | Systems Admin
Shelburne, United States - 11:55 pm local time
My background combines systems administration, platform engineering, and hands-on IT operations. I have 16 years of IT experience, so I approach AI systems like production systems, not demos. I think about uptime, permissions, observability, failure modes, documentation, and handoff, not just prompts.
My work includes multi-agent runtime design, secure vaults, encrypted communications, agent memory pipelines, MCP server integrations, operator dashboards, billing and audit systems, and deployed SaaS tools. I also build practical workflow tools for day-to-day operations, including monitoring systems, notification tools, field workflow automation, and AI-supported reporting interfaces.
I can help with:
- autonomous agent architecture
- RAG and knowledge systems
- MCP server and tool integration
- secure AI infrastructure and credential handling
- systems administration for agent runtimes, Docker, and VPS environments
- workflow automation and operator dashboards
- production hardening, documentation, and handoff
If you need more than a chatbot and want an engineer who can make agent systems secure, reliable, and operational, I’m a strong fit.
Steps for completing your project
After purchasing the project, send requirements so Sadie can start the project.
Delivery time starts when Sadie receives requirements from you.
Sadie works on your project following the steps below.
Revisions may occur after the delivery date.
You share your data sources and describe what your
You share your data sources and describe what your AI needs to know and when.
I build the ingestion pipeline, vector index, memo
I build the ingestion pipeline, vector index, memory sync, and retrieval API.