You will get a scalable and reliable data pipeline (ETL) using Python, Azure or AWS
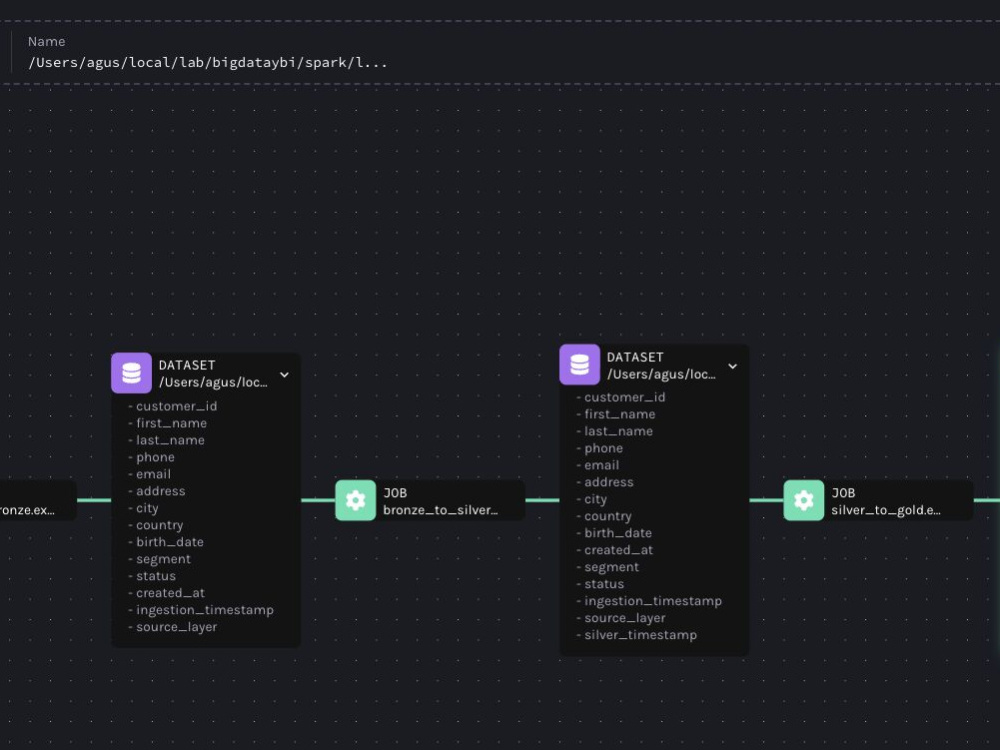
Project details
You will get a reliable and scalable data pipeline that transforms your raw data into clean, structured, and ready-to-use information.
With experience in banking and telecommunications, I specialize in building, fixing, and optimizing ETL pipelines in cloud environments like Azure and AWS. I understand how critical data quality, performance, and reliability are for decision-making.
What sets me apart:
✔ I focus on production-ready solutions, not just quick fixes
✔ I ensure data quality, consistency, and validation
✔ I design scalable architectures that grow with your business
✔ I communicate clearly and deliver on time
Whether you need to fix a broken pipeline, migrate your data to the cloud, or build a new solution from scratch, I will help you turn your data into a reliable asset.
The solution you receive will be clean, efficient, and tailored to your needs 🚀
With experience in banking and telecommunications, I specialize in building, fixing, and optimizing ETL pipelines in cloud environments like Azure and AWS. I understand how critical data quality, performance, and reliability are for decision-making.
What sets me apart:
✔ I focus on production-ready solutions, not just quick fixes
✔ I ensure data quality, consistency, and validation
✔ I design scalable architectures that grow with your business
✔ I communicate clearly and deliver on time
Whether you need to fix a broken pipeline, migrate your data to the cloud, or build a new solution from scratch, I will help you turn your data into a reliable asset.
The solution you receive will be clean, efficient, and tailored to your needs 🚀
Database Type
MySQL, Oracle, PostgreSQL, MongoDBWhat's included
| Service Tiers |
Starter
$30
|
Standard
$100
|
Advanced
$180
|
|---|---|---|---|
| Delivery Time | 2 days | 4 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Source Code | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$20 - $100
Additional Revision
+$100Frequently asked questions
About Alejandro
Data Engineer | ETL Pipelines | Azure, Databricks, SQL, PySpark
Lima, Peru - 6:04 pm local time
I’m a Data Engineer with experience in banking and telecommunications, working on large-scale data environments using Azure, Databricks, SQL, and PySpark.
Here’s how I can help you:
✔ Build scalable ETL/ELT pipelines from scratch
✔ Fix broken or slow data pipelines
✔ Improve data quality (validation, consistency, reliability)
✔ Design data models for analytics and BI
✔ Optimize queries and reduce processing time
In my previous roles, I have:
• Built data pipelines processing millions of records daily
• Detected and fixed critical data quality issues in production systems
• Developed analytical models used for strategic decision-making
• Automated data workflows to improve efficiency and reliability
Tech stack:
Azure (Data Factory, Data Lake), Databricks, PySpark, SQL, Airflow, Python, Power BI
I focus on delivering reliable, scalable, and production-ready solutions.
Let’s work together to turn your data into a real asset 🚀
Steps for completing your project
After purchasing the project, send requirements so Alejandro can start the project.
Delivery time starts when Alejandro receives requirements from you.
Alejandro works on your project following the steps below.
Revisions may occur after the delivery date.
Project details and data source
Please describe your use case, data sources, current setup, and main issue or goal