You will get Advanced Website Data Collection & Automation (Python, Playwright, Scrapy)

Project details
You will get a fast, secure, and fully automated data collection solution built with Python, Playwright, and Scrapy. I specialize in creating reliable systems that handle both static and dynamic websites with smart proxy rotation, CAPTCHA handling, and cloud deployment options. With years of experience in automation and scalable workflows, I ensure clean, structured data output tailored to your exact needs — ready for analytics, dashboards, or integrations. Every project is custom-built for performance, accuracy, and long-term reliability.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$30
|
Standard
$75
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 3 days | 5 days |
Number of Pages Mined/Scraped | 50 | 150 | 298 |
Number of Sources Mined/Scraped | 1 | 1 | 2 |
Number of Revisions | 2 | 2 | 4 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$20Frequently asked questions
About Harsh
Web Scraping & Data Automation Engineer
Hazaribagh, India - 2:32 am local time
I’m a Full-Stack Data Extraction & Automation Engineer specializing in web scraping, data pipelines, and enterprise-grade automation systems. My mission is simple — transform complex, unstructured web data into clean, reliable, and actionable intelligence that drives decisions.
I design production-ready scraping and automation systems that handle everything — from extraction and processing to delivery and monitoring. Every build is scalable, reliable, and fully documented, ensuring long-term usability and performance.
🧠 Technical Expertise
🔹 Scraping & Crawling
Scrapy · Playwright · Requests · Selenium — high-performance crawlers for static and dynamic websites
🔹 Deployment & Infrastructure
Dockerized pipelines | AWS & basic GCP hosting | PostgreSQL databases | ScrapeOps monitoring
🔹 Anti-Bot & CAPTCHA Handling
Bright Data / Smartproxy | 2Captcha API | Advanced handling for Cloudflare, Datadome, and other anti-bot systems
🔹 AI-Enhanced Data Processing
GPT-5 + Pandas for data cleaning, enrichment, and transformation | Zencoder AI for text classification
🔹 Workflow Automation
n8n.io orchestration | Scheduled scrapers | Automated delivery to APIs, dashboards, or databases
🔹 Version Control
Clean, modular codebases | Git/GitHub versioning | Complete documentation and logs
🏗️ What I Deliver
✅ Custom Scrapers & Crawlers – scalable, anti-block systems that handle millions of records
✅ Full Data Pipelines – automated ETL workflows with retries and monitoring
✅ Automation Workflows – data delivery to APIs, dashboards, or reports
✅ Cloud Deployment – containerized, production-ready solutions
✅ Structured Data Outputs – CSV, JSON, Excel, PostgreSQL, or direct API
⚡ Why Clients Work With Me
Enterprise Mindset: Every project is engineered for uptime, scalability, and clean maintainability.
Rapid MVP Delivery: Working prototypes in 3–5 days for most projects.
Transparent Pricing: Simple, milestone-based pricing.
Future-Proof Builds: Modular code, monitoring, and logging included.
Constant Learning: 20+ hours/week refining scraping, AI parsing, and cloud techniques.
💼 Typical Projects
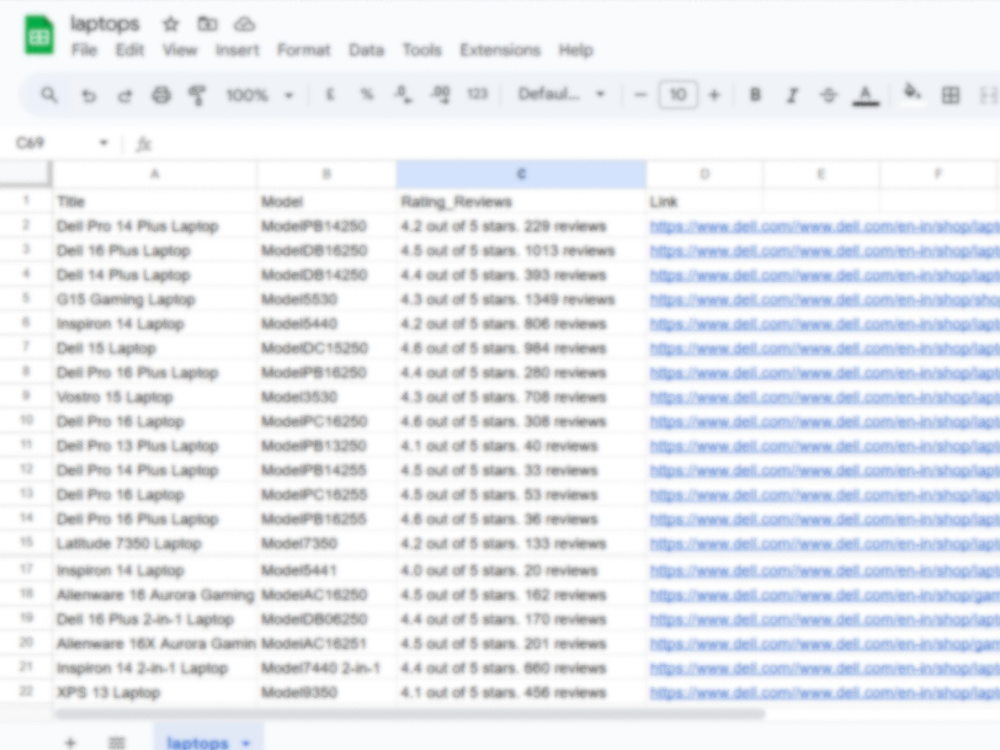
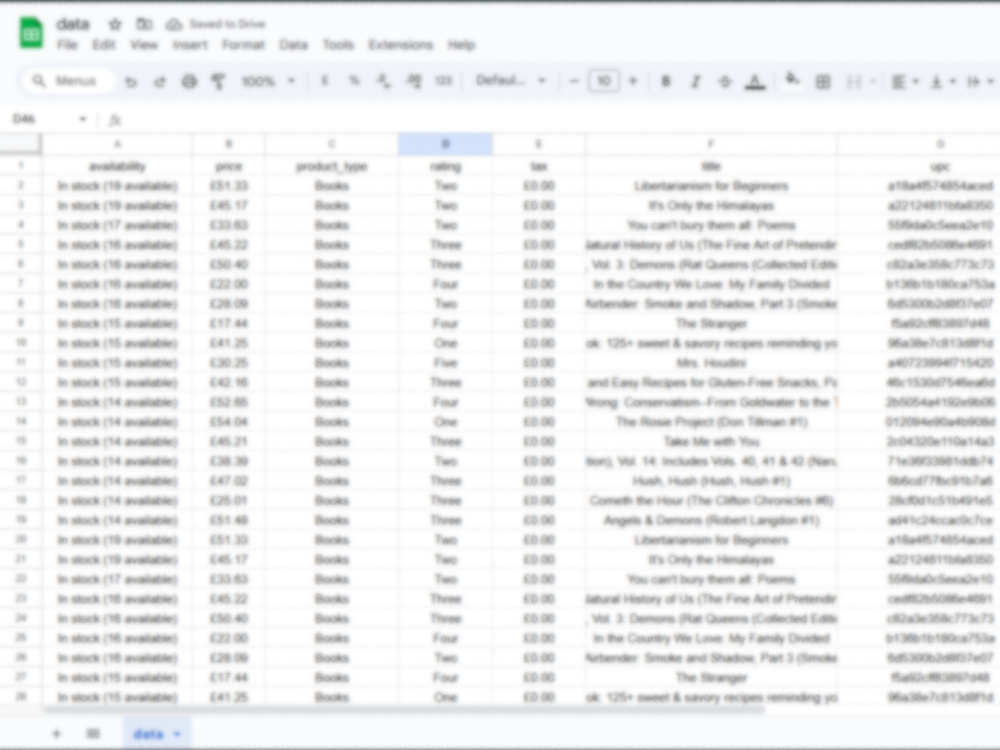
📊 E-commerce Intelligence — product data, pricing, stock tracking
🏢 Lead Generation — extracting business data from directories & portals
💬 Social Insights — Reddit/Twitter/forum data collection (where permitted)
📈 Price & Inventory Monitoring — real-time competitor updates
📑 Market Research Datasets — structured feeds for analysts and firms
🔄 End-to-End Automation — full ETL pipelines with n8n.io orchestration
🤝 Let’s Work Together
I build scrapers that last — stable, intelligent, and automated.
Send me your target site and requirements, and I’ll provide a free feasibility report that includes:
Technical approach
Potential challenges (logins, CAPTCHAs, IP rotation)
Data schema proposal
Timeline & cost estimate
Tech Stack:
Python · Scrapy · Playwright · Requests · n8n · Pandas · GPT-5 · PostgreSQL · Docker · AWS · GCP · Bright Data · Smartproxy · 2Captcha · ScrapeOps · Git/GitHub · YAML · Bash · Linux · Networking & Security Basics
Steps for completing your project
After purchasing the project, send requirements so Harsh can start the project.
Delivery time starts when Harsh receives requirements from you.
Harsh works on your project following the steps below.
Revisions may occur after the delivery date.
Project Execution & Progress Updates
I’ll set up the run test extractions, and share sample data for your review before full automation.