You will get AI Document Extraction: Parse PDFs, Invoices & Forms with OCR
Project details
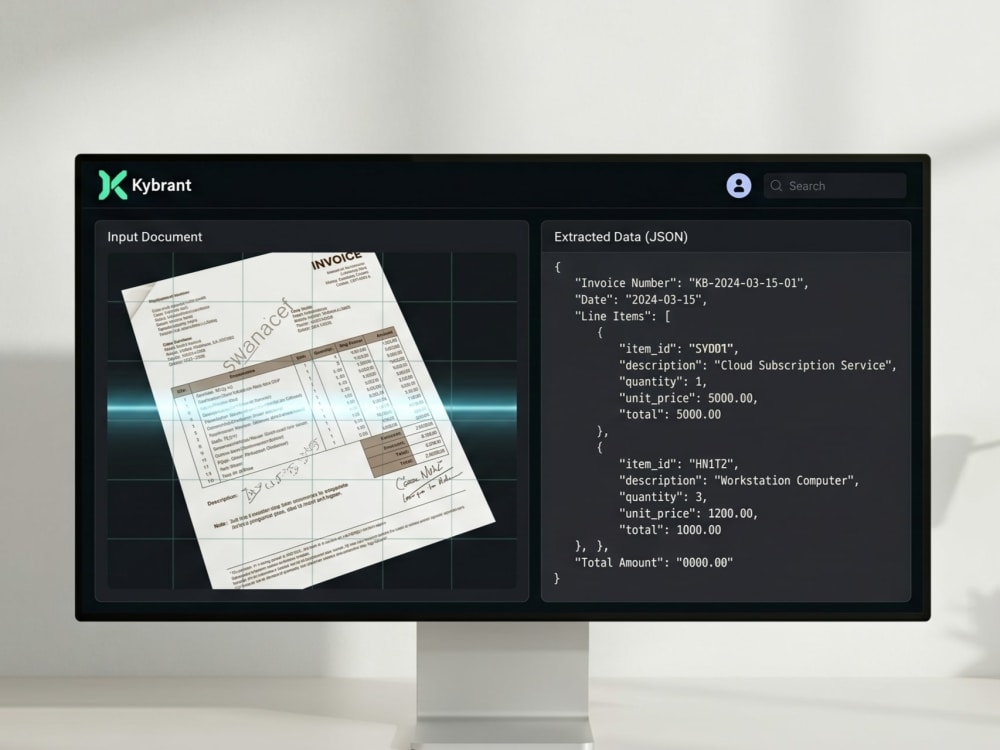
You will get a production‑ready document extraction pipeline that turns unstructured PDFs, scanned forms, and images into clean, structured data — powered by computer vision and language models.
I'm an AI Engineer who built OCR‑backed financial automation for a FinTech ERP from scratch. My pipelines don't just read text; they classify documents, extract key fields, validate data, and plug directly into your workflows.
What sets this apart:
• Hybrid intelligence — computer vision (OpenCV, Tesseract) combined with LLM post‑processing (LangChain) to handle poor scans, handwriting, and complex layouts.
• Beyond extraction — built‑in validation rules, anomaly detection, and confidence scoring so you know exactly when to review.
• Secure and scalable — encrypted storage, zero‑trust principles, and a clean API/webhook for seamless integration.
• Multi‑format support — PDFs, JPEG, PNG, TIFF, invoices, receipts, forms, ID cards, and more.
• Production‑ready — delivered with source code, tests, deployment scripts, documentation, and a live handoff.
Every pipeline is battle‑tested on real‑world document chaos and built to scale.
I'm an AI Engineer who built OCR‑backed financial automation for a FinTech ERP from scratch. My pipelines don't just read text; they classify documents, extract key fields, validate data, and plug directly into your workflows.
What sets this apart:
• Hybrid intelligence — computer vision (OpenCV, Tesseract) combined with LLM post‑processing (LangChain) to handle poor scans, handwriting, and complex layouts.
• Beyond extraction — built‑in validation rules, anomaly detection, and confidence scoring so you know exactly when to review.
• Secure and scalable — encrypted storage, zero‑trust principles, and a clean API/webhook for seamless integration.
• Multi‑format support — PDFs, JPEG, PNG, TIFF, invoices, receipts, forms, ID cards, and more.
• Production‑ready — delivered with source code, tests, deployment scripts, documentation, and a live handoff.
Every pipeline is battle‑tested on real‑world document chaos and built to scale.
AI Algorithms
Convolutional Neural Network, Large Language Model, Transformer Model, YOLOAI Applications
AI-Enhanced Classification, Anomaly Detection, Image Analysis, Image Processing, Image Recognition, Image Upscaling, Natural Language Understanding, Object Detection, Text RecognitionAI Development Language
PythonAI Tools
Hugging Face, PyTorchAI Models
BERT, ChatGPT, GPT-4What's included
| Service Tiers |
Starter
$49
|
Standard
$299
|
Advanced
$499
|
|---|---|---|---|
| Delivery Time | 7 days | 14 days | 21 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | - | ||
Detailed Code Comments | - | ||
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | |
Model Documentation | - | ||
Model Monitoring | - | - | |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | - | ||
Source Code |
Frequently asked questions
About Soumasnigdha
AI Engineer
Bengaluru, India - 3:41 am local time
Architecting Intelligence | Engineering Reliability
I am an AI Engineer specializing in building autonomous, AI‑native FinTech systems—transforming complex financial logic into reliable, production‑grade platforms where artificial intelligence serves as a core utility. My expertise lies in bridging agentic AI, product engineering, and high‑fidelity user experiences to deliver enterprise solutions from zero to one.
Core Competencies:
- Intelligent Backend Systems: I architect high‑concurrency, asynchronous APIs using FastAPI and Pydantic. I standardize service layers and refactor complex financial workflows—such as automated reconciliation and multi‑tenant procurement—into modular, observable architectures with structured logging and error interception.
- Agentic AI & Predictive Analytics: I design autonomous agentic workflows that orchestrate LLMs (LangChain), RAG with vector search (pgvector), and computer vision (OCR) for intelligent document parsing, real‑time analytics, and conversational BI. I apply advanced prompt engineering and generative AI to deliver a forensic‑level financial intelligence engine, enabling 10x Autonomous Finance.
- High‑Fidelity Frontends: I craft premium, responsive user experiences using React, TypeScript, and Vite. I leverage Framer Motion, Radix UI, and Tailwind CSS with glassmorphic aesthetics to simplify complex financial interactions and make enterprise data intuitive.
- Cloud & Infrastructure: I manage scalable, secure data layers with PostgreSQL and Supabase, enforcing Row‑Level Security and RBAC for bank‑grade isolation. I deploy multi‑service, zero‑trust environments on GCP/AWS via Docker, CI/CD (GitHub Actions), and automated secret management.
Technical Arsenal:
- Languages & Logic: Python (FastAPI, Pydantic, Asyncio), TypeScript (React, Vite)
- AI & Science: LLM Orchestration (LangChain), RAG (pgvector), OCR, Agentic AI, Prompt Engineering, Time‑Series, Pandas, NumPy, Statistics
- Styling & UI: Tailwind CSS, Framer Motion (Advanced Animations), Glassmorphism, Radix UI, CSS‑in‑JS
- Infra & Reliability: GCP/AWS, PostgreSQL (Supabase RLS/RBAC), Docker, CI/CD (GitHub Actions), Zero‑Trust Secret Management, Structured Logging, System Metrics, Code Refactoring
Why I Build:
I believe AI should not be a siloed experiment but a seamless, reliable layer within the user experience. Whether architecting agentic workflows for financial decision‑making or polishing a frontend design system, I build for consistency, security, and scalable intelligence—turning bold product visions into enterprise‑grade reality.
Steps for completing your project
After purchasing the project, send requirements so Soumasnigdha can start the project.
Delivery time starts when Soumasnigdha receives requirements from you.
Soumasnigdha works on your project following the steps below.
Revisions may occur after the delivery date.
Document Audit & Field Mapping
I’ll review your document samples and define a precise extraction schema. We’ll agree on the fields, validation rules, and confidence thresholds.
OCR & Vision Pipeline Setup
I’ll build the document preprocessing pipeline (deskew, denoise, layout analysis) and configure the OCR engine for text and table extraction.