You will get big data ETL and Machine Learning using Spark
Project details
Hi there,
Thanks for your interest in big data-related service. I am an IBM and John Hopkins University, USA certified Data Scientist with 5+ years of enterprise-level experience in data science, AWS, and Hadoop. Here, I will help you with your Apache spark problems.
Tasks performed, inter alia:
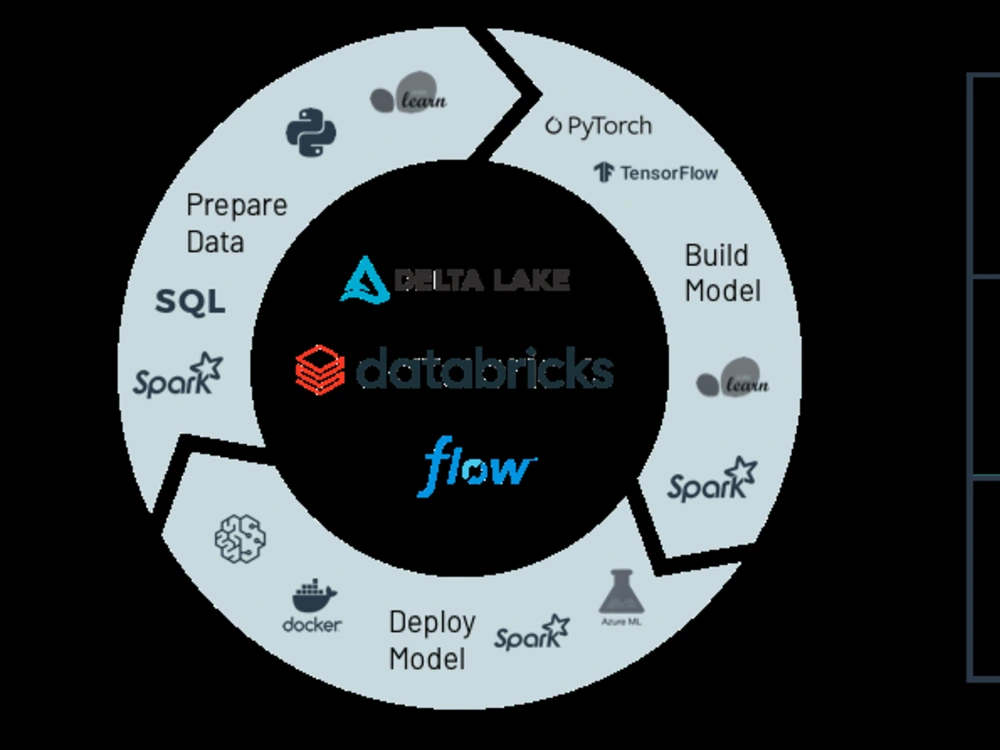
· ETL Jobs in Apache Spark by utilizing the Dataframes/RDDs in Pyspark
· Transformations and Actions on data in Pyspark
· ETL/Transformation using Spark SQL and Hive SQL
· Data Analysis using Pyspark,
· Data Processing pipelines for Machine Learning and BI
· Scalable ML using Spark MLlib
· Scale up existing Pandas/Scikit-Learn machine learning code.
· Set up Spark environment on AWS, Databricks
Tools used, among other things:
· Spark
· Python
· Databricks
· AWS
· Pandas
· Hadoop
· Hive
NOTE: KINDLY CONTACT ME BEFORE PLACING ORDER
'Quality is my identity'
I look forward to working with you.
Thanks for your interest in big data-related service. I am an IBM and John Hopkins University, USA certified Data Scientist with 5+ years of enterprise-level experience in data science, AWS, and Hadoop. Here, I will help you with your Apache spark problems.
Tasks performed, inter alia:
· ETL Jobs in Apache Spark by utilizing the Dataframes/RDDs in Pyspark
· Transformations and Actions on data in Pyspark
· ETL/Transformation using Spark SQL and Hive SQL
· Data Analysis using Pyspark,
· Data Processing pipelines for Machine Learning and BI
· Scalable ML using Spark MLlib
· Scale up existing Pandas/Scikit-Learn machine learning code.
· Set up Spark environment on AWS, Databricks
Tools used, among other things:
· Spark
· Python
· Databricks
· AWS
· Pandas
· Hadoop
· Hive
NOTE: KINDLY CONTACT ME BEFORE PLACING ORDER
'Quality is my identity'
I look forward to working with you.
What's included $50
These options are included with the project scope.
$50
- Delivery Time 4 days
- Number of Revisions 2
- Number of Model Variations 2
- Number of Scenarios 2
- Number of Graphs/Charts 3
- Model Validation/Testing
- Source Code
About Manohar
AWS Machine Learning Developer- Python/Spark
Bengaluru, India - 5:37 am local time
Here are my key achievements in data science so far :
• Derived actionable insights from massive data sets using statistical analysis, SQL queries, MS- Excel, and Tableau, reducing cost by 15%.
• Heralded a significant change in supply chain management, enabled the sales department to exceed the target for three consecutive months (by 13%, 9%, and 10% respectively).
• Accomplished 90%+ recall using autoencoders, streamlined auditing, and fraud examining the process in terms of time, scale, and effort.
• Effectuated an Inbound Marketing Conversion Rate of 29% after targeting and retargeting, enlarged and consolidated Customer Life Time Value.
• Contributed meaningful improvement in existing machine learning models through carefully directed research, increased performance by 40%.
Steps for completing your project
After purchasing the project, send requirements so Manohar can start the project.
Delivery time starts when Manohar receives requirements from you.
Manohar works on your project following the steps below.
Revisions may occur after the delivery date.
Collecting data
Data required will be collected from you.
Cleaning
Cleaning the data