You will get Clean ETL Pipeline from CSV/XML/JSON to SQLite with Documentation


Project details
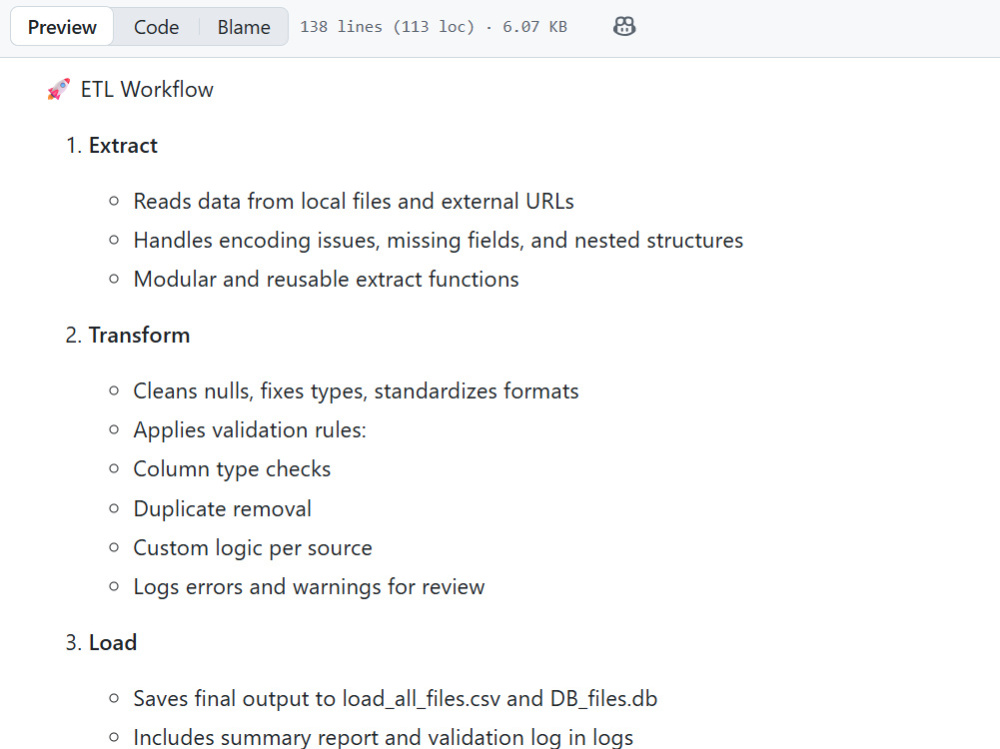
This project offers a complete, modular ETL pipeline that extracts, validates, transforms, and merges data from multiple sources including CSV, JSON, XML, and public APIs. Built using Python, Pandas, and SQLite, the workflow is fully documented and designed for reliability, scalability, and traceability. Each step—from extraction to export—is logged and validated to ensure clean, structured, and analysis-ready data. I specialize in building ETL systems that are easy to maintain, with clear logic, and professional documentation including README, LICENSE, requirements.txt, and logs. Whether you're preparing data for dashboards, reports, or machine learning models, this project ensures your data is consistent, complete, and ready for use. Ideal for clients who value transparency, technical rigor, and clean deliverables.
Data Tool
pandasWhat's included
| Service Tiers |
Starter
$50
|
Standard
$100
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 3 days | 5 days |
Number of Revisions | 1 | 2 | 3 |
Number of Sources Mined/Scraped | 1 | 2 | 4 |
Frequently asked questions
About Fatma
Data Engineer ETL Pipelines: CSV/XML/JSON/API, SQLite, Clean , Documen
Qina, Egypt - 2:49 am local time
My workflows include column-level checks, derived field creation, and structured loading into .csv and .db formats. I document every step with professional English comments, README, LICENSE, and logging for full traceability.
My latest project showcases multi-format integration with schema integrity, error handling, and client-ready presentation. I focus on clarity, reliability, and delivering solutions that earn trust.
Steps for completing your project
After purchasing the project, send requirements so Fatma can start the project.
Delivery time starts when Fatma receives requirements from you.
Fatma works on your project following the steps below.
Revisions may occur after the delivery date.
Receive and Review Source Dat
Client provides CSV, JSON, XML files or API details. I inspect structure, encoding, and completeness.
Extract Data from All Sources
I use modular Python functions to read and normalize data from each source, handling nested fields and missing values.