You will get Custom Document extraction model using state of the art NLP.
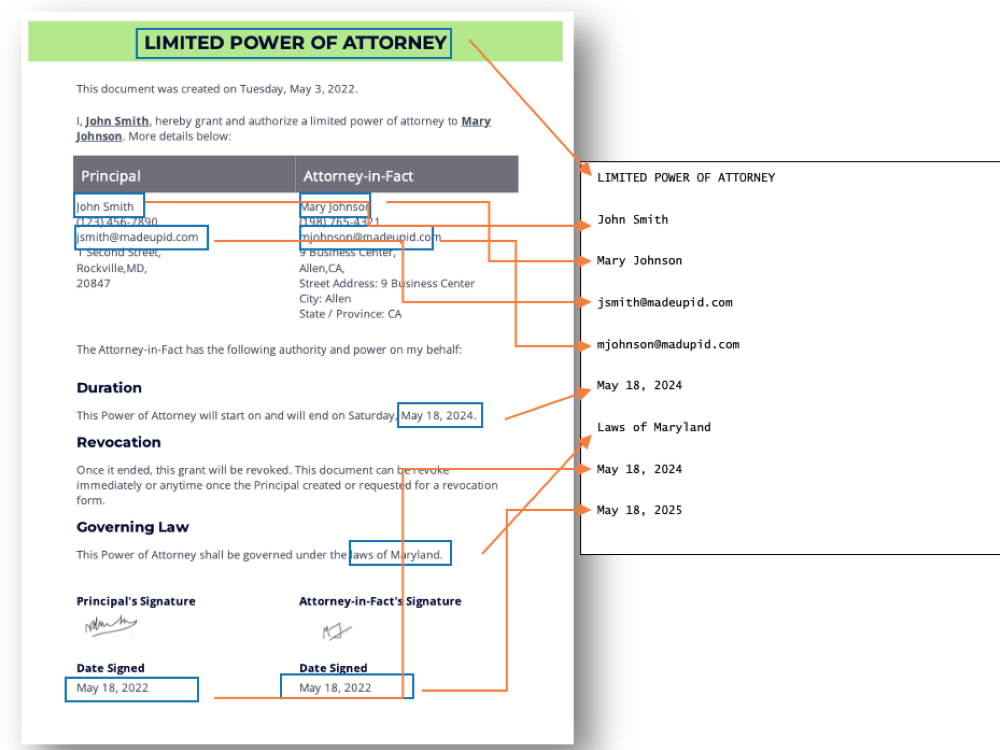
Project details
I will create a custom OCR model for your use case. I have experience working as a Machine learning Engineer in OCR at a Y Combinator-backed startup that serves multiple insurance companies with up to 50,000 requests served daily.
Machine Learning Tools
deeplearn.js, Python Scikit-Learn, PyTorch, Tesseract OCR, Vertex AIWhat's included
| Service Tiers |
Starter
$120
|
Standard
$350
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 6 days | 14 days | 30 days |
Number of Revisions | 1 | 2 | 4 |
Model Validation/Testing | |||
Model Documentation | |||
Data Source Connectivity | - | ||
Source Code | - | - |
About Divyanshu
AI Engineer & Data Science Leader | Production LLM/RAG Systems
Gurgaon, India - 1:56 am local time
→ LLM-powered applications with custom context assembly and RAG
→ Agentic AI systems with multi-step reasoning
→ Automated content and data pipelines (NLP summarization, classification, generation)
→ Production ML infrastructure with CI/CD across AWS, GCP, and Cloudflare
→ End-to-end MVPs — from architecture to deployment3+ years of professional experience across AI startups. I work iteratively, communicate clearly, and ship production-grade systems.
Steps for completing your project
After purchasing the project, send requirements so Divyanshu can start the project.
Delivery time starts when Divyanshu receives requirements from you.
Divyanshu works on your project following the steps below.
Revisions may occur after the delivery date.
Analysis of Documents
This step involves me assessing the documents and expected responses. Also, assessing the viability of the project. Your domain knowledge would be required or I will research that on my own as well.
Requirement specifications
We will discuss the compute resources, and the quality of the OCR backend in terms of open-source or highly scalable third-party OCR techniques.