You will get Custom Web Scraper with Python & Playwright
Rising Talent
Rising Talent
Project details
You will get a custom web scraper built with Python and Playwright that reliably extracts the data you need — delivered clean, structured, and ready to use.
I've built production scrapers that pull from 7+ sources simultaneously, handle deduplication, pagination, and dynamic content, and store results directly into Supabase or export as CSV/JSON. My scrapers run live on real projects, not just demos.
What makes my work different: I focus on data accuracy and reliability. I handle anti-bot measures, implement retry logic, and test across multiple scenarios before delivery. You get working code with clear documentation, not just a script that breaks on the first edge case.
Whether you need a one-time data extraction or a scheduled recurring scraper, I'll build it clean and modular so it's easy to maintain or extend later.
I've built production scrapers that pull from 7+ sources simultaneously, handle deduplication, pagination, and dynamic content, and store results directly into Supabase or export as CSV/JSON. My scrapers run live on real projects, not just demos.
What makes my work different: I focus on data accuracy and reliability. I handle anti-bot measures, implement retry logic, and test across multiple scenarios before delivery. You get working code with clear documentation, not just a script that breaks on the first edge case.
Whether you need a one-time data extraction or a scheduled recurring scraper, I'll build it clean and modular so it's easy to maintain or extend later.
Programming Languages
JavaScript, PythonCoding Expertise
Performance OptimizationWhat's included
| Service Tiers |
Starter
$75
|
Standard
$150
|
Advanced
$250
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Pages Mined/Scraped | 1 | 10 | 50 |
Number of Sources Mined/Scraped | 1 | 1 | 3 |
Install Script | |||
Test Script | - | ||
Task Automation | - | - |
Frequently asked questions
About TSUNG YU
AI Automation & Data Engineer | Python | n8n | Web Scraping
Dacun, Taiwan - 5:56 pm local time
Currently operating:
✓ 19 live n8n workflows
✓ 46,000+ executions
✓ 0.3% failure rate
✓ 24/7 VPS deployment
I help businesses automate data collection, monitoring, and decision-making using Python, n8n, and AI-powered workflows.
Recent work includes:
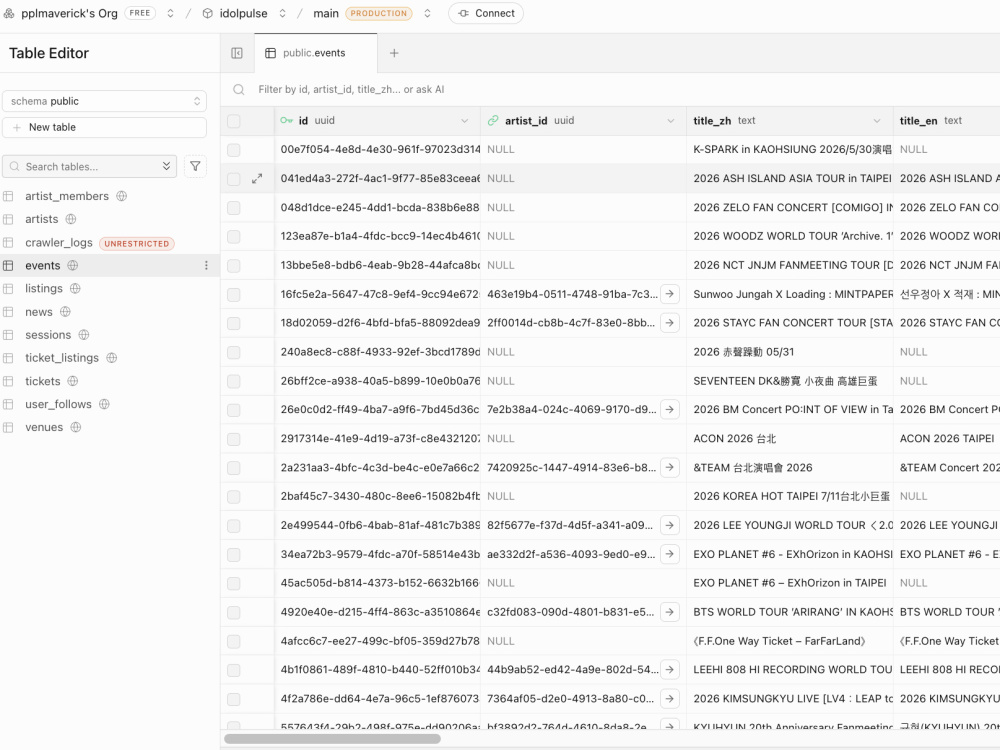
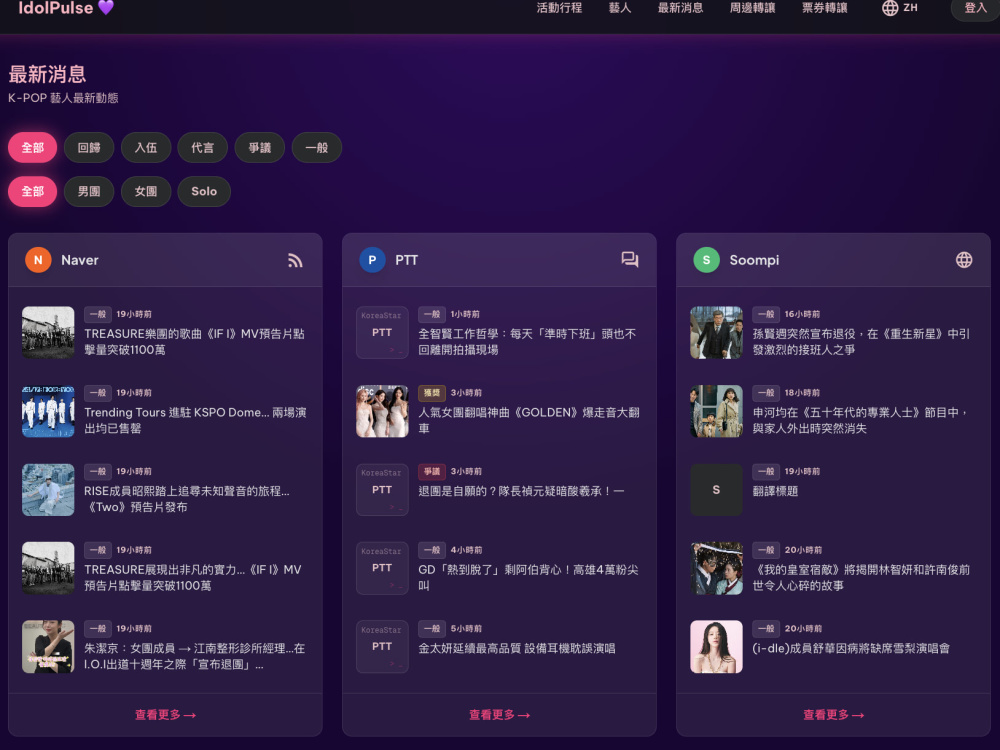
A multi-source event intelligence platform aggregating data from 8 sources (ticketing sites, PTT, Naver, Soompi) into structured pipelines and real-time alerts
A crypto trading automation suite covering smart money tracking, funding rate alerts, spread monitoring, and pre-listing detection with Telegram notifications
AI-powered workflows using OpenAI, Claude, and Gemini for content analysis, classification, summarization, and automated reporting
Common use cases:
Monitor competitors and market trends automatically
Aggregate information from multiple sources into a single dashboard
Receive instant alerts when important events occur
Generate AI-powered reports without manual work
Build internal tools that save hours every week
What I can build for you:
Web scrapers for e-commerce, news, events, or research data (Python, Playwright, BeautifulSoup)
Automation workflows connecting APIs, databases, and messaging platforms (n8n + Python)
Data pipelines with structured output to Supabase, Google Sheets, or your database
AI integrations for summarization, classification, and automated reporting
Web3 integrations and smart contract deployment (Solidity, EVM chains)
I deliver clean, documented solutions that are easy to maintain and continue generating value long after the project is completed.
Steps for completing your project
After purchasing the project, send requirements so TSUNG YU can start the project.
Delivery time starts when TSUNG YU receives requirements from you.
TSUNG YU works on your project following the steps below.
Revisions may occur after the delivery date.
Analyze target website
Review the target URL, identify data structure, and confirm output format with client
Build and test scraper
Develop the scraper with error handling, pagination, and anti-bot measures. Run tests to verify data accuracy