You will get DrugBank Data Processing & Knowledge Graph with Neo4j
Top Rated
Project details
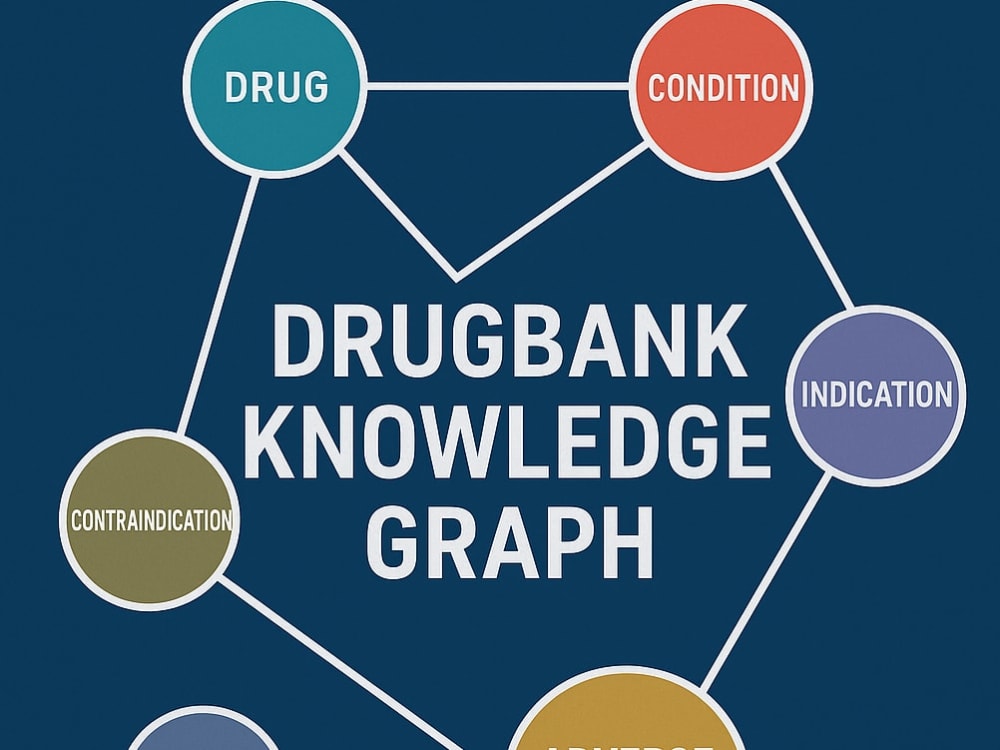
You will get a DrugBank Data Processing & Knowledge Graph System built with Neo4j and Cypher queries. This project focuses on transforming DrugBank dataset into a structured biomedical graph, making all drug-related knowledge easily accessible and queryable.
The system will integrate drugs, conditions, adverse effects, contraindications, indications, chemical entities, evidence, and cross-entity relationships into one connected knowledge graph. Key relationships include:
Drug -[...]-> ChemicalEntity
Drug -[...]-> Condition
Drug -[...]-> Indication
Drug -[...]-> AdverseEffect
Drug -[...]-> Contraindication
Drug -[.....]-> Drug
Indication -[...]-> Condition
AdverseEffect -[...]-> Condition
Contraindication -[...]-> Condition etc.
With Neo4j as the backend and Cypher queries powering exploration, you can analyze drugs from multiple perspectives: find indications, check contraindications, identify safer alternatives, explore side effects, or review supporting evidence.
The system will integrate drugs, conditions, adverse effects, contraindications, indications, chemical entities, evidence, and cross-entity relationships into one connected knowledge graph. Key relationships include:
Drug -[...]-> ChemicalEntity
Drug -[...]-> Condition
Drug -[...]-> Indication
Drug -[...]-> AdverseEffect
Drug -[...]-> Contraindication
Drug -[.....]-> Drug
Indication -[...]-> Condition
AdverseEffect -[...]-> Condition
Contraindication -[...]-> Condition etc.
With Neo4j as the backend and Cypher queries powering exploration, you can analyze drugs from multiple perspectives: find indications, check contraindications, identify safer alternatives, explore side effects, or review supporting evidence.
AI Algorithms
Large Language ModelAI Applications
AI Chatbot, Conversational AIAI Development Language
PythonAI Models
ChatGPTWhat's included $1,500
These options are included with the project scope.
$1,500
- Delivery Time 7 days
- Number of Revisions 1
- Database Integration
- Source Code
14 reviews
(13)
(1)
(0)
(0)
(0)
This project doesn't have any reviews.
SS
Selda S.
Oct 10, 2025
AI System Development Using GraphRag and LightRag for MS Teams
Sujan was a pleasure to work with and did a great job of the work requested.
CC
Christian C.
May 11, 2025
GraphRAG (Knowledge Graph) Language Education
HO
Henry O.
Jan 14, 2025
We are looking for AI Engineer to help us with our project
XC
Xaiver C.
Mar 11, 2024
ElectronJS / VueJS Expert
DS
Dominik S.
Nov 27, 2023
update vue3 project to node18, update electron, update capacitor
About Sujan
RAG| GraphRAG | Neo4j |Ontology |Azure| Langchain | LangGraph| FastAPI
100%
Job Success
Narayangonj, Bangladesh - 1:33 am local time
I specialize in developing RAG and AI Agent systems with 15+ years of full-stack experience using LangChain, LangGraph, FastAPI, and vector databases (Qdrant, Pinecone, FAISS etc). For data ingestion, I build end-to-end pipelines supporting multi-format sources (PDF, DOCX, CSV, Excel, websites), structured cleaning with spaCy, Textacy & CleanText, web scraping via Playwright, BeautifulSoup & Jina Reader, Overlap Late Chunking for retrieval accuracy, and Microsoft Graph API integration for SharePoint/OneDrive across Microsoft 365.I also build real-time Voice AI agents using Pipecat with full STT → LLM → TTS streaming pipelines.
My retrieval expertise covers Re-ranking (Cohere, FlashRank, Jina), dense/sparse/hybrid search, RAG Fusion, Semantic Caching, contextual compression, custom output parsers, LLM Token tracing, and RAGAS-based evaluation.
I am a 𝐍𝐞𝐨𝟒𝐣 𝐂𝐞𝐫𝐭𝐢𝐟𝐢𝐞𝐝 𝐏𝐫𝐨𝐟𝐞𝐬𝐬𝐢𝐨𝐧𝐚𝐥 specializing in Graph RAG, graph data modeling, Cypher queries, and domain ontology alignment. For graph ingestion, I have developed knowledge graph pipelines using GraphTransformers and NLP libraries for entity & relation extraction, aligned with domain-specific ontologies. For graph retrieval, I have implemented Graph Traversal, vector search, Think-On-Graph (ToG) reasoning, and Cypher Agents (generation, validation, correction, execution) leveraging LLMs for answers.
Front End experience with TypeScript, Vue.js Composition API, Quasar Framework. I have a sharp eye for detail and quality and have experience of Software Reengineering. I am a self motivated individual who is both deadline focused and thorough in my approach to work.
-------------------𝐏𝐫𝐨𝐯𝐞𝐧 𝐄𝐱𝐩𝐞𝐫𝐭𝐢𝐬𝐞 𝐢𝐧 𝐋𝐋𝐌 𝐀𝐩𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭-------------------
𝐀𝐝𝐯𝐚𝐧𝐜𝐞𝐝 𝐑𝐀𝐆 & 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥 𝐒𝐲𝐬𝐭𝐞𝐦𝐬
• Implemented RAG with multiple data formats (PDF, DOCX, CSV, Excel, TXT, websites etc.)
• Enhanced retrieval techniques using RAG Fusion with multiple re-rankers (Cohere, FlashRank, Jina)
• Applied optimization strategies like Prompt Caching, Semantic Caching with vector databases
• Context-aware chunking is implemented by "Overlap Late Chunking" to improve retrieval accuracy
• Conducted RAG evaluations using RAGAS for quality assessment and benchmarking
• Built structured web scraping and cleaning pipelines using Playwright, BeautifulSoup, Jina Reader, Textacy, CleanText, spaCy etc.
• Implemented dense, sparse, and hybrid search for advanced similarity search and optimal retrieval
• Implemented LLM Token Tracing for monitoring LLM cost per user
• Implemented custom output parsers for specialized formatting
• Integrated Microsoft Graph API to fetch and process data from SharePoint and OneDrive across Microsoft 365
𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐆𝐫𝐚𝐩𝐡 & 𝐆𝐫𝐚𝐩𝐡𝐑𝐀𝐆 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
• Built Neo4j GraphRAG system with Graph Traverse and vector search capabilities
• Created knowledge graphs aligned with domain-specific ontologies including bio-medical Ontology, using transformers, custom logic and detailed instruction-based prompts.
• Developed Cypher Agents with LangGraph for Cypher generation, validation, correction, and execution
• MS GraphRAG solutions with LanceDB and Parquet files, search and Indexing ,incremental indexing.
• Successfully migrated MS GraphRAG Parquet files to Neo4j (KG) database systems
𝐋𝐋𝐌 𝐀𝐠𝐞𝐧𝐭𝐬 & 𝐂𝐨𝐧𝐯𝐞𝐫𝐬𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐀𝐈
• Designed LangGraph Agent architectures for multi-step reasoning workflows
• Built multi-agent systems with specialized roles
• Applied advanced prompt engineering with few-shot learning and context window optimization
• Developed real-time Voice AI agents using Pipecat for low-latency conversational interactions
• Implemented streaming speech-to-text → LLM reasoning → text-to-speech pipelines
𝐅𝐮𝐥𝐥-𝐒𝐭𝐚𝐜𝐤 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭
• Backend Development: Python, FastAPI for scalable services
• Vector Database Integration: Qdrant, Faiss, LanceDB for efficient similarity search
• Hybrid Application Development: Cross-platform solutions with Quasar Framework
• Mobile Application Development: Expertise with Capacitor and Electron frameworks
𝐂𝐨𝐫𝐞 𝐓𝐞𝐜𝐡𝐧𝐨𝐥𝐨𝐠𝐢𝐞𝐬:
- 𝐀𝐈/𝐋𝐋𝐌: Langchain, LangGraph, LlamaIndex, OpenAI, Claude
- 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞𝐬: Neo4j, Qdrant, FAISS, LanceDB, Pinecone, Chroma
- 𝐕𝐨𝐢𝐜𝐞 𝐀𝐈: Pipecat, Real-time Voice Agents, STT/TTS streaming pipelines
- 𝐖𝐞𝐛 𝐂𝐫𝐚𝐰𝐥𝐢𝐧𝐠: FireCrawl, Jina, Puppeteer, Scrapy, Playwright, Beautiful Soup
- 𝐃𝐨𝐜𝐮𝐦𝐞𝐧𝐭 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠: Llama Parse, Document Loaders, spaCy, Textacy
Steps for completing your project
After purchasing the project, send requirements so Sujan can start the project.
Delivery time starts when Sujan receives requirements from you.
Sujan works on your project following the steps below.
Revisions may occur after the delivery date.
finalize drugbank table data or entities to be processed
Drugbank provide csv and api access to get data and we need to finalized which we will use and what need to be procesed in the graph.
Neo4j graph build
all data will be converted into Knowledge graph with related nodes and connect to each other with proper relations. sample cypher query will be provided to traverse the graph to check how its connected.