You will get Data entry, Data Cleaning & Preprocessing for Accurate Business Insights
Project details
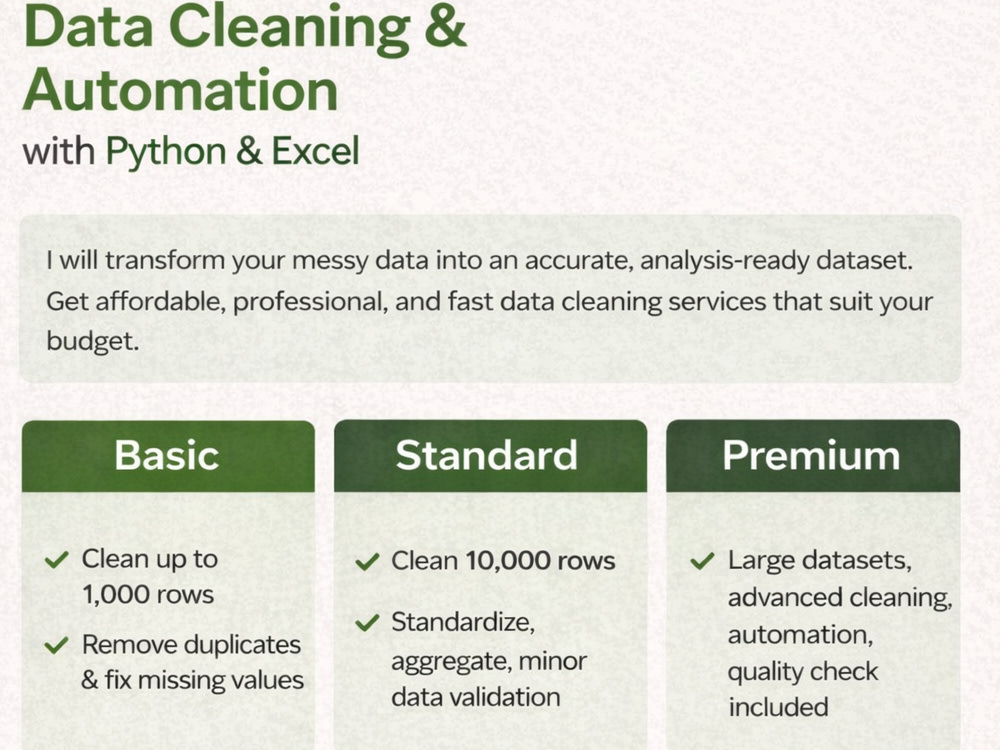
I will clean, preprocess, and structure your messy data into an accurate, analysis-ready dataset using Python and Excel. This service includes removing duplicates, handling missing values, fixing formatting issues, standardizing columns, and validating data quality.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$20
|
Standard
$50
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 3 days | 5 days |
Number of Revisions | Unlimited | Unlimited | Unlimited |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$10 - $50
Additional Page Mined/Scraped
(+ 2 Days)
+$10
Additional Source Mined/Scraped
(+ 2 Days)
+$10About Abdullateef
Data Engineer | Databricks Data Engineer | Big Data
Oyo, Nigeria - 11:41 am local time
One of my core strengths is building streaming ETL pipelines using Spark Structured Streaming, where I detect anomalies and suspicious patterns in financial data as they happen, not hours later in batch processing.
What I do best:
1. Real-time data streaming pipelines (Databricks / Spark Structured Streaming)
2. Fraud detection systems using rule based anomaly detection
3. Data cleaning & transformation at scale (PySpark)
4. Handling missing, invalid, and inconsistent financial data
5. Building data warehouse-ready datasets (Delta Lake / SQL layers)
6. Designing robust ETL pipelines (bronze → silver → gold architecture)
Recent work highlights:
1. Built a real-time fraud detection pipeline on Databricks
2. Processed streaming transaction data with low latency anomaly detection
3. Reconstructed missing financial fields using business logic (Quantity, Total Spent, Price Per Unit relationships)
4. Designed a dual-layer system separating clean and suspicious transactions for auditing and analytics
Tools & Technologies:
Databricks, PySpark, Spark Structured Streaming, Delta Lake, SQL, Python, Data Warehousing, ETL Pipelines. I focus on building production-style, scalable, and maintainable data systems that can support real business decision-making especially in finance, analytics, and transactional systems.
If you need a Data Engineer who can go beyond batch ETL and build real-time intelligent data pipelines, I can help.
Steps for completing your project
After purchasing the project, send requirements so Abdullateef can start the project.
Delivery time starts when Abdullateef receives requirements from you.
Abdullateef works on your project following the steps below.
Revisions may occur after the delivery date.
Review Dataset & Requirements
I examine your dataset, identify issues, and confirm cleaning goals.
Clean & Preprocess Data
Remove duplicates, fix missing values, standardize formats, and validate data.