You will get RAG System Setup for Your Knowledge Base (Semantic Search + LLM)
Project details
I build RAG systems that let your users ask questions about your documents and get accurate AI answers with source citations.
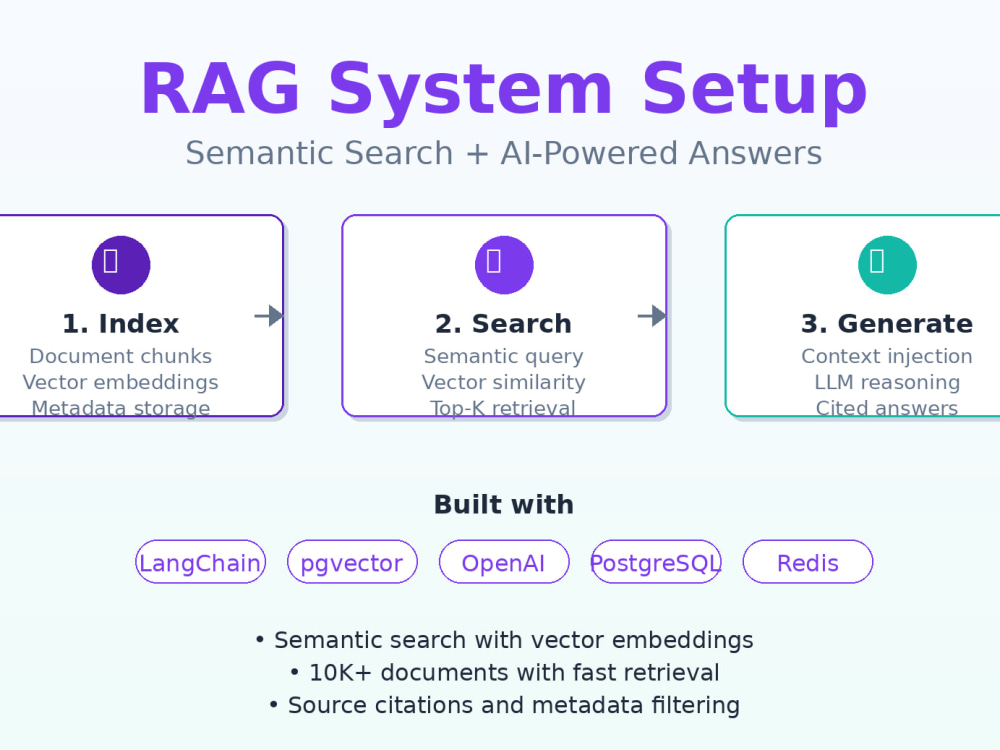
Your documents get chunked, embedded, and stored in a vector database (PostgreSQL + pgvector). When someone asks a question, the system finds the most relevant chunks using semantic search, then feeds them to an LLM to generate an answer — with citations pointing back to the original sources.
This isn't keyword search. It understands meaning — "how do I reset my password" matches "account recovery steps" even if those exact words aren't in your docs.
I've built RAG systems handling 10,000+ documents with sub-500ms search times. The implementation includes smart chunking (so context doesn't get lost), metadata filtering (search by date/category/source), and proper error handling when documents can't answer the question.
Works with your existing Python backend or as a standalone API. You get the vector database setup, document processing pipeline, search API, and LLM integration — all production-ready.
Delivery: 6-7 days with complete source code and deployment guide.
Your documents get chunked, embedded, and stored in a vector database (PostgreSQL + pgvector). When someone asks a question, the system finds the most relevant chunks using semantic search, then feeds them to an LLM to generate an answer — with citations pointing back to the original sources.
This isn't keyword search. It understands meaning — "how do I reset my password" matches "account recovery steps" even if those exact words aren't in your docs.
I've built RAG systems handling 10,000+ documents with sub-500ms search times. The implementation includes smart chunking (so context doesn't get lost), metadata filtering (search by date/category/source), and proper error handling when documents can't answer the question.
Works with your existing Python backend or as a standalone API. You get the vector database setup, document processing pipeline, search API, and LLM integration — all production-ready.
Delivery: 6-7 days with complete source code and deployment guide.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Transformer ModelAI Applications
AI Chatbot, AI Content Creation, Conversational AI, Natural Language Generation, Natural Language Understanding, Sentiment Analysis, Text RecognitionAI Development Language
PythonAI Tools
Azure OpenAI, GitHub Copilot, Hugging Face, Jasper AI, Microsoft 365 Copilot, Replit, Streamlit, Word2vecAI Models
BERT, ChatGPT, GPT-3, GPT-4, GPT-J, LLaMA, Midjourney AI, OpenAI Codex, WhisperWhat's included
| Service Tiers |
Starter
$300
|
Standard
$600
|
Advanced
$1,000
|
|---|---|---|---|
| Delivery Time | 5 days | 7 days | 10 days |
Number of Revisions | 2 | 4 | 8 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | |||
Detailed Code Comments | |||
Image Upscaling | - | - | |
MLOps | - | - | |
Model Deployment | - | ||
Model Documentation | |||
Model Monitoring | - | - | |
Model Testing & Optimization | - | ||
Model Tuning | - | - | |
Natural Language Processing | - | ||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | |||
Source Code |
Frequently asked questions
46 reviews
(38)
(1)
(3)
(3)
(1)
This project doesn't have any reviews.
MK
Mike K.
Aug 23, 2024
Moodle Website Version Upgrade
GG
Guillaume G.
Apr 12, 2024
Slack API Flask App
Shiva was excellent in this project. He pays attention to details, he is available and very skilled in Slack API integrations.
MW
Marcus W.
Feb 26, 2024
Air Table + Cloudflare pages backend integration
He was a great help, and was able to diagnose and resolve my issue within minutes, definitely recommend!
JH
Jordan H.
Jan 8, 2024
Wordpress automation for uploading files
Shiva was fast and helpful and polite, would recommend!
VN
Valentina N.
Nov 28, 2023
Learning managment sistem Developer.
About Shivalaya
Python Engineer | LLM Applications, RAG & Agentic Systems
Shimla, India - 8:17 pm local time
My main background is backend development. So when I add AI to a system, it comes with proper auth, database design, async processing, and cost control. I do not just call the OpenAI API and hope it works. I build the full layer around it so it holds up in real use.
What I work on:
LLM integration for backends. I set up multi-LLM systems that route between OpenAI, Claude, or Gemini based on the task, with fallback when one model is down. I also wrap every LLM call so each request is monitored. This tracks tokens, cost, and latency, so you know exactly what your AI is spending and where.
Cost and performance. This is where most AI features go wrong. They work fine in the demo, and then the bill keeps growing. I add caching so repeated questions do not hit the API again, rate limiting and retry logic to keep it stable, and prompt handling to keep token usage low. The aim is simple: keep the system fast and the cost predictable as usage grows.
RAG systems. I use vector databases like pgvector or Pinecone, and I handle the document processing, chunking, embeddings, and semantic search. The answers come from your own data, not generic responses.
AI agents with LangChain and LangGraph. These are workflows where the AI decides which tools to call and when. I set up the agent logic, tool calling, and error handling so it does not break on unexpected input.
Backend integration is where most people struggle. I have integrated LLMs into FastAPI and Django apps with auth, rate limiting, background jobs (Celery and Redis), proper testing, and database schemas that fit AI content. I keep the APIs clean so frontend teams can work with them easily.
Stack: Python, FastAPI, OpenAI API, Claude API, LangChain, LangGraph, PostgreSQL, pgvector, Redis, AWS
Recent projects:
- Recruitment platform with AI resume screening, handling 50K+ API calls per day
- Clinical AI system on AWS Bedrock, with careful data handling for a regulated healthcare setting
- Voice AI assistant with real-time speech processing (Whisper, OpenAI, ElevenLabs)
What I focus on is reliability. AI systems that do not fall apart when traffic grows or edge cases show up. Monitoring, cost tracking, caching, rate limits, retries, testing, and error handling. This is the backend work that makes AI features reliable, not just good in a demo.
Available for longer projects (3 to 6 months).
Steps for completing your project
After purchasing the project, send requirements so Shivalaya can start the project.
Delivery time starts when Shivalaya receives requirements from you.
Shivalaya works on your project following the steps below.
Revisions may occur after the delivery date.
Document Analysis & Database Setup
Review your document types and structure. Set up PostgreSQL with pgvector extension and configure vector indexing for optimal search performance.
Document Processing Pipeline
Build the pipeline that loads your documents, splits them into optimal chunks (preserving context), and generates vector embeddings using OpenAI's embedding model.