You will get Survey Data Cleaning, Statistical Analysis (SPSS/Python) & Report
Project details
You collected the data. Now you need it clean, analyzed, and presented in a way your committee, funder, or supervisor will actually trust.
This service takes your raw survey dataset — whether it came from KoboToolbox, Google Forms, SurveyCTO, or Excel — and delivers a complete statistical report ready to paste directly into your thesis, working paper, or programme report.
What you get:
• Full data cleaning in Python or SPSS — duplicates removed, missing values handled, variable labels applied
• Descriptive statistics: frequencies, means, and cross-tabulations for your key variables
• Hypothesis tests appropriate to your data and research questions (chi-square, t-tests, Mann-Whitney, ANOVA, as needed)
• A written report with clearly labelled tables and charts, formatted for your document
• Output files delivered in Word and PDF
Built for NGO programme officers who need clean numbers for their donor reports, scholars preparing their findings chapter, and working paper authors who want analysis they can defend.
Turnaround: 7 days from receipt of your dataset and questionnaire.
This service takes your raw survey dataset — whether it came from KoboToolbox, Google Forms, SurveyCTO, or Excel — and delivers a complete statistical report ready to paste directly into your thesis, working paper, or programme report.
What you get:
• Full data cleaning in Python or SPSS — duplicates removed, missing values handled, variable labels applied
• Descriptive statistics: frequencies, means, and cross-tabulations for your key variables
• Hypothesis tests appropriate to your data and research questions (chi-square, t-tests, Mann-Whitney, ANOVA, as needed)
• A written report with clearly labelled tables and charts, formatted for your document
• Output files delivered in Word and PDF
Built for NGO programme officers who need clean numbers for their donor reports, scholars preparing their findings chapter, and working paper authors who want analysis they can defend.
Turnaround: 7 days from receipt of your dataset and questionnaire.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$120
|
Standard
$320
|
Advanced
$550
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Pages Mined/Scraped | 5 | 10 | 15 |
Number of Sources Mined/Scraped | 10 | 20 | 30 |
Optional add-ons
You can add these on the next page.
Raw code (Python/SPSS syntax) + documentation
(+ 1 Day)
+$50About John
Python Research Data Analyst | Econometrics, Regression, M&E, SPSS
Nairobi, Kenya - 2:03 am local time
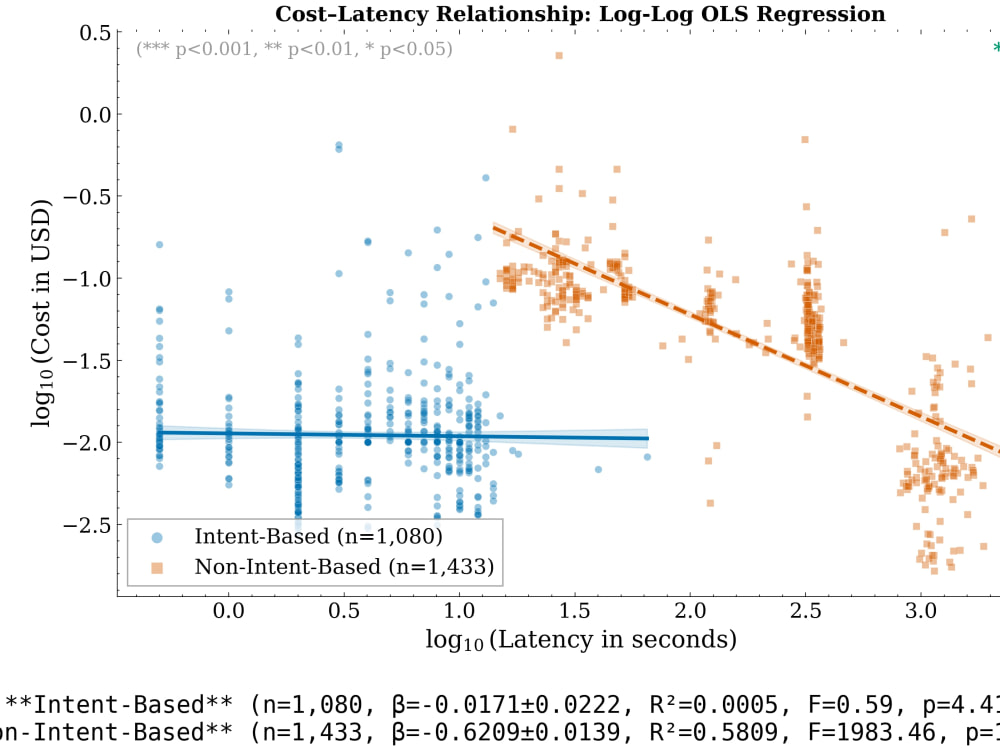
Over the past seven years, I have analyzed datasets ranging from a few hundred household survey records up to 2,520 controlled experimental observations from on-chain smart contract studies. I work daily in pandas, numpy, scipy, statsmodels, scikit-learn, and matplotlib, and I still use SPSS when a client prefers the output format their funder is used to. The methods I reach for most are OLS regression with fixed effects, Mann-Whitney U and Kruskal-Wallis H tests, mixed-effects models, k-means clustering, principal component analysis, and Monte Carlo Shapley value estimation when I need to attribute variance fairly across predictors.
What I think makes me different is that I write up the results properly. A clean dataset and a tidy notebook are not the deliverables. The deliverable is a short report that tells you what the numbers actually mean, what assumptions I made, where the model is weak, and what you should do next. I have done this for academics affiliated with the University of Zurich, for a UK-based compliance consultancy, and for the public health office I currently lead M&E for in Nyeri County, Kenya.
If you are a PhD student or working paper author who needs Python support, an NGO sitting on survey data you have not had time to analyze, or a Web3 team trying to make sense of an experimental on-chain study, send me the brief and a sample of the data. I will reply within a few hours and tell you honestly whether I am the right person for the job.
Typical engagements: short studies from 300 to 1,500 USD, full analysis pipelines from 1,500 to 5,000 USD, and ongoing M&E retainers from 1,200 USD per month.
Steps for completing your project
After purchasing the project, send requirements so John can start the project.
Delivery time starts when John receives requirements from you.
John works on your project following the steps below.
Revisions may occur after the delivery date.
Provide Dataset
You share your dataset (Excel, CSV, SPSS, or Stata) and your questionnaire or codebook, along with the questions your analysis needs to answer.
Dataset Cleaning
I clean the data and send you a brief data quality summary — what was found and fixed — plus any questions before analysis begins.