You will get Enterprise-Grade LLM API Caching Layer (Python)
Project details
The Problem:
When building Generative AI applications (like RAG or Agentic Workflows), redundant LLM API calls to models like GPT-4 or Claude become a massive bottleneck. They cause slow response times (high latency), trigger API rate limits, and rapidly inflate token costs.
The Solution:
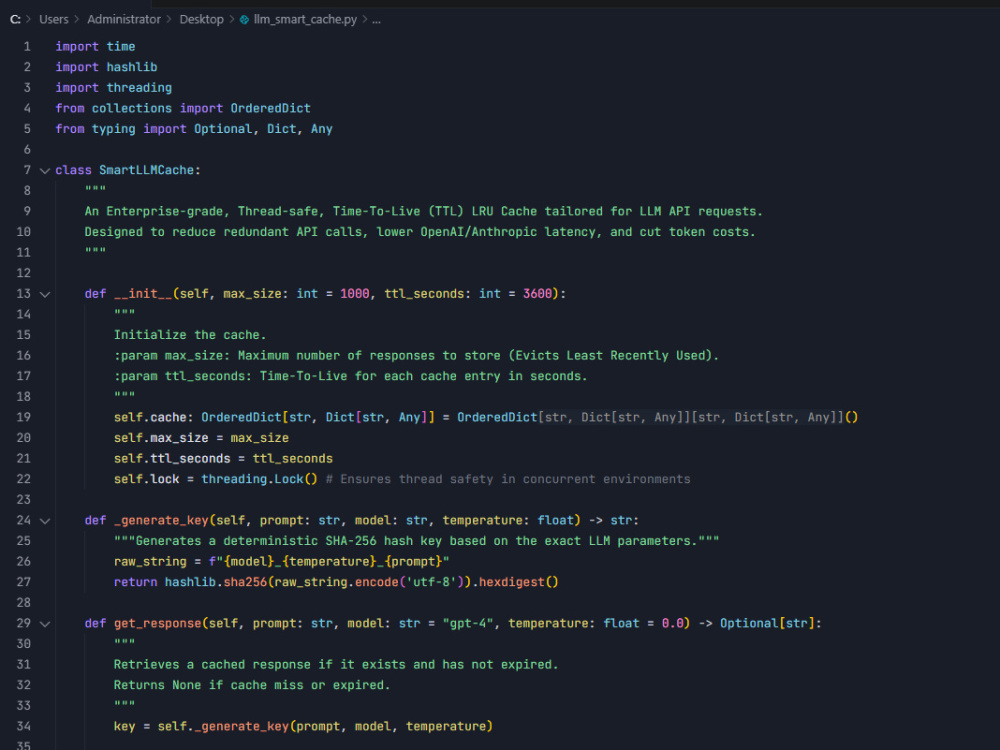
I engineered a highly optimized, Thread-Safe LRU (Least Recently Used) Caching Layer in pure Python.
Key Architectural Features:
O(1) LRU Eviction: Utilizes collections.OrderedDict to ensure optimal memory management, automatically evicting the oldest data.
Thread-Safety for Concurrency: Implemented threading.Lock() to prevent race conditions.
Time-To-Live (TTL) Expiration: Ensures that cached responses remain fresh.
SHA-256 Prompt Hashing: Deterministically hashes massive prompts to ensure exact parameter matching.
Business Impact:
Implementing this transparent caching layer typically reduces repetitive API costs by over 30% and drops response latency from seconds to milliseconds.
When building Generative AI applications (like RAG or Agentic Workflows), redundant LLM API calls to models like GPT-4 or Claude become a massive bottleneck. They cause slow response times (high latency), trigger API rate limits, and rapidly inflate token costs.
The Solution:
I engineered a highly optimized, Thread-Safe LRU (Least Recently Used) Caching Layer in pure Python.
Key Architectural Features:
O(1) LRU Eviction: Utilizes collections.OrderedDict to ensure optimal memory management, automatically evicting the oldest data.
Thread-Safety for Concurrency: Implemented threading.Lock() to prevent race conditions.
Time-To-Live (TTL) Expiration: Ensures that cached responses remain fresh.
SHA-256 Prompt Hashing: Deterministically hashes massive prompts to ensure exact parameter matching.
Business Impact:
Implementing this transparent caching layer typically reduces repetitive API costs by over 30% and drops response latency from seconds to milliseconds.
AI Algorithms
Large Language Model, Transformer ModelAI Applications
AI Chatbot, Conversational AI, Natural Language Generation, Natural Language UnderstandingAI Development Language
PythonAI Models
ChatGPT, GPT-3What's included
| Service Tiers |
Starter
$30
|
Standard
$80
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 1 day | 2 days | 4 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | - | ||
Batch Normalization | - | - | - |
Database Integration | - | - | |
Detailed Code Comments | |||
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | |||
Model Monitoring | - | - | - |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | - | - |
Setup File | - | ||
Source Code |
Frequently asked questions
About Yanzu
Generative AI Engineer | RAG Systems & Custom LLM Agents
Xuchang, China - 11:00 pm local time
Senior AI/ML Engineer | RAG, Custom LLMs & Python Backend Expert
Overview:
I build AI systems that don't just compute—they understand.
I am a Senior Machine Learning Engineer with over 7 years of Python backend experience. I specialize in taking state-of-the-art ML, Deep Learning, and Generative AI concepts and turning them into seamless, powerful software solutions.
Recently, I've been heavily focused on solving the "hallucination" and "context" problems in modern AI.
What I bring to the table:
RAG Architecture: I have hands-on experience building enterprise-grade Knowledge Base systems using RAG, allowing LLMs to interact flawlessly with your proprietary data.
Advanced AI Integration: I seamlessly weave complex neural networks and AI logic into streamlined backend workflows, ensuring zero compromise on system performance.
From Concept to Production: My 7 years of engineering background means I know how to deploy models securely and efficiently. I don't leave you with a fragile Jupyter Notebook; I deliver production-tier code.
I deeply value collaborative, transparent communication within a team. Whether you need to optimize a bloated data pipeline or build an AI sidekick with persistent memory, I have the technical depth to make it happen.
If you are looking for an engineer who blends deep technical rigor with creative AI problem-solving, let's talk.
Steps for completing your project
After purchasing the project, send requirements so Yanzu can start the project.
Delivery time starts when Yanzu receives requirements from you.
Yanzu works on your project following the steps below.
Revisions may occur after the delivery date.
Review & Script Delivery
I will review your stack and deliver the core LRU caching script tailored to your use case.
Integration (Standard/Advanced)
I will securely integrate the caching layer into your existing Python application and run tests.