You will get a Custom AI assistant using RAG, OpenAI and vector database
Rising Talent

Rising Talent
Project details
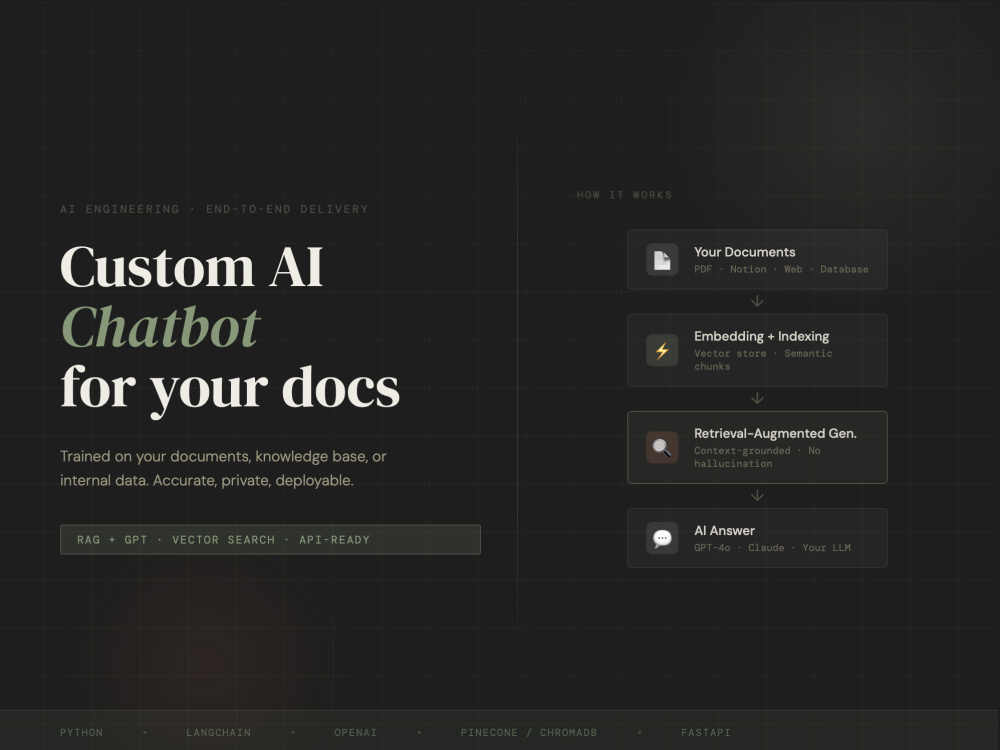
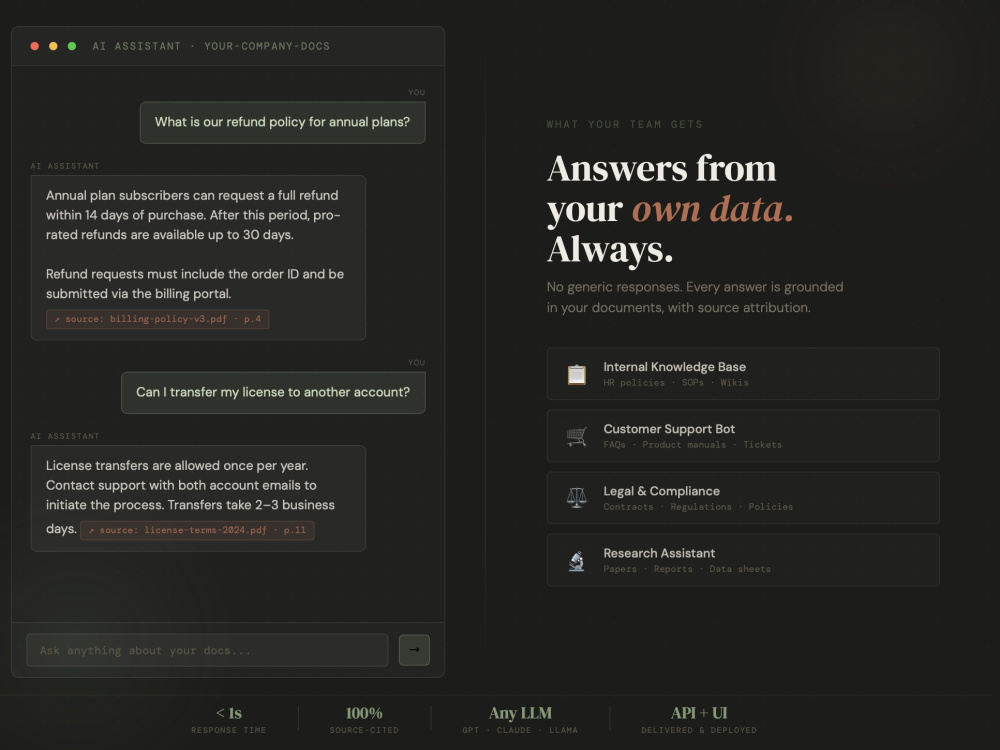
I will build a custom AI chatbot that answers questions using your own documents, knowledge base, or data sources.
The chatbot uses modern LLM technology (GPT or similar models) combined with Retrieval-Augmented Generation (RAG), allowing it to search your files and provide accurate, contextual answers.
This solution is ideal for:
• Customer support chatbots
• Internal knowledge assistants
• Research and document search
• Product or documentation support
Depending on the package, the chatbot can include:
• document ingestion (PDFs, text, websites)
• vector search and semantic retrieval
• prompt optimization
• API integration
• deployment guidance
You will receive clean Python code, setup instructions, and documentation so the system can be easily maintained or extended.
If you're unsure about the best architecture or tools, I can also help define the optimal setup for your use case.
The chatbot uses modern LLM technology (GPT or similar models) combined with Retrieval-Augmented Generation (RAG), allowing it to search your files and provide accurate, contextual answers.
This solution is ideal for:
• Customer support chatbots
• Internal knowledge assistants
• Research and document search
• Product or documentation support
Depending on the package, the chatbot can include:
• document ingestion (PDFs, text, websites)
• vector search and semantic retrieval
• prompt optimization
• API integration
• deployment guidance
You will receive clean Python code, setup instructions, and documentation so the system can be easily maintained or extended.
If you're unsure about the best architecture or tools, I can also help define the optimal setup for your use case.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Recurrent Neural Network, Transformer ModelAI Applications
AI Chatbot, Conversational AI, Natural Language Generation, Natural Language UnderstandingAI Development Language
PythonAI Tools
Gradio, Hugging Face, PyTorch, Streamlit, TensorFlowAI Models
BERT, ChatGPT, GPT-3, GPT-4What's included
| Service Tiers |
Starter
$180
|
Standard
$380
|
Advanced
$750
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 8 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | - | ||
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | |
Model Documentation | - | ||
Model Monitoring | - | - | - |
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | - | ||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | - | - | - |
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$60 - $90
Additional Revision
+$50Frequently asked questions
About Lorena
Data Scientist | ML, NLP & Production-Ready AI Systems
Belo Horizonte, Brazil - 6:12 am local time
PROBLEMS I SOLVE:
→ "We have tons of customer feedback but no way to analyze it"
✓ Sentiment analysis pipelines using transformer models (multilingual)
→ "Our forecasts are unreliable"
✓ Time-series models achieving 96%+ R² and single-digit MAPE
→ "We need to automate insights from text data"
✓ LLM-powered applications (RAG, chatbots, document analysis)
→ "Our model needs to scale beyond local testing"
✓ AWS deployment (SageMaker, Lambda, Glue) + Docker
WHAT MAKES ME DIFFERENT:
Most data scientists stop at the model. I deliver complete solutions:
✓ Clean, documented code (production-ready)
✓ Interactive dashboards and simulators (Streamlit/Plotly)
✓ Cloud deployment with monitoring
✓ Clear business impact metrics
RECENT PROJECTS:
- Warehouse capacity forecasting for pharma (J&J LATAM): MAE 1.79, 84% predictions within 2 units
- NLP sentiment analysis: end-to-end pipeline from EDA to AWS production
- Sales forecasting improving baseline accuracy by 18%
CORE STACK:
Python • SQL • PyTorch • Scikit-learn • Hugging Face • OpenAI/Anthropic • LangChain • AWS • Streamlit • Docker
Currently Data Scientist at a consulting firm working with J&J LATAM | Previously BMW Financial Services Canada
English (fluent) + Portuguese (native)
Let's turn your data challenge into a solution.
Steps for completing your project
After purchasing the project, send requirements so Lorena can start the project.
Delivery time starts when Lorena receives requirements from you.
Lorena works on your project following the steps below.
Revisions may occur after the delivery date.
Review requirements and understand your use case
Prepare documents, embeddings, and retrieval pipeline