You will get a custom NLP model for text classification and sentiment analysis
Project details
Do you have thousands of customer reviews, social media posts, or documents, but no way to make sense of them? I will build a highly accurate Natural Language Processing (NLP) model to classify your text and extract actionable insights.
As a Computer Science researcher with deep expertise in machine learning, I specialize in solving tough data problems—especially when datasets are noisy, highly imbalanced, or lack resources.
What I offer:
• Sentiment Analysis: Understand if customer feedback is positive, negative, or neutral.
• Text Classification: Automatically categorize support tickets, emails, or articles.
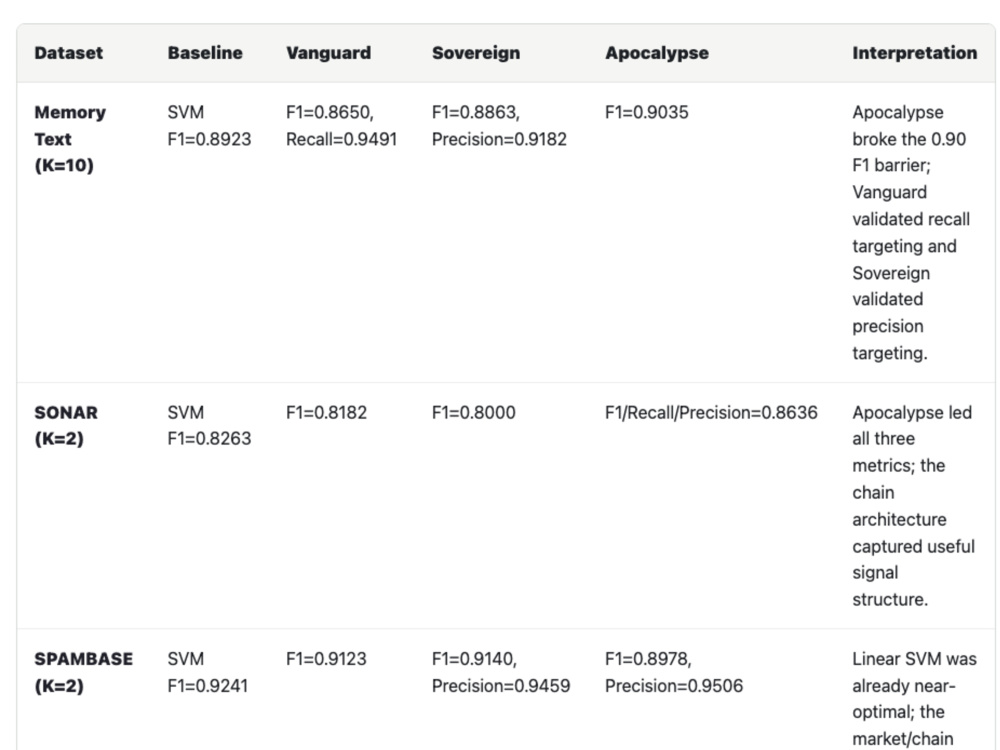
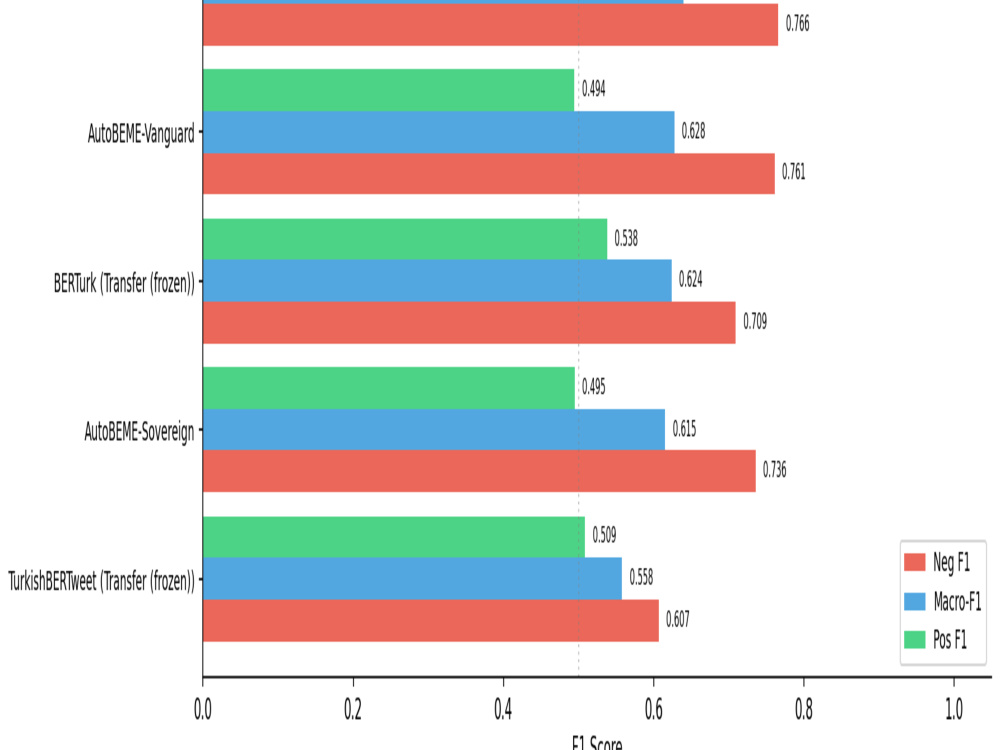
• Advanced Data Handling: I don't just run basic scripts. I use advanced techniques (like SMOTE, multi-agent ensemble learning, and custom BERT fine-tuning) to ensure high F1-scores even when data is messy.
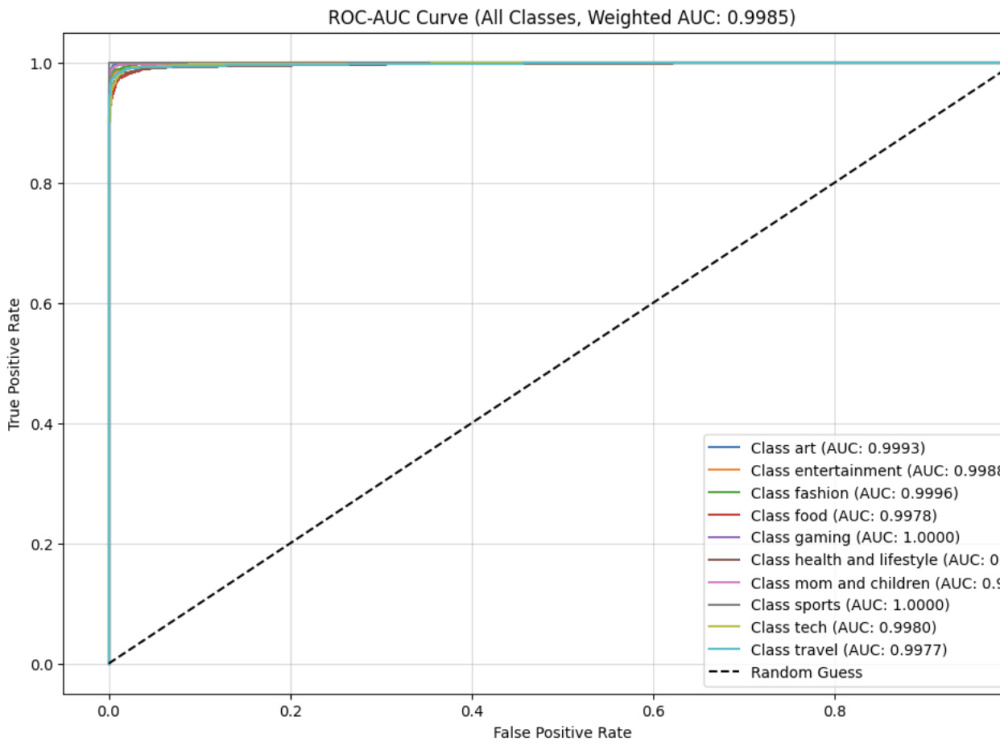
• Clear Reporting: You won't get a black-box model. I provide comprehensive evaluation metrics (Precision, Recall, Confusion Matrices) so you know exactly how it performs.
Whether you need quick zero-shot analysis or a custom-trained robust architecture, I deliver clean code and reliable results. Let’s turn your unstructured text into valuable data!
As a Computer Science researcher with deep expertise in machine learning, I specialize in solving tough data problems—especially when datasets are noisy, highly imbalanced, or lack resources.
What I offer:
• Sentiment Analysis: Understand if customer feedback is positive, negative, or neutral.
• Text Classification: Automatically categorize support tickets, emails, or articles.
• Advanced Data Handling: I don't just run basic scripts. I use advanced techniques (like SMOTE, multi-agent ensemble learning, and custom BERT fine-tuning) to ensure high F1-scores even when data is messy.
• Clear Reporting: You won't get a black-box model. I provide comprehensive evaluation metrics (Precision, Recall, Confusion Matrices) so you know exactly how it performs.
Whether you need quick zero-shot analysis or a custom-trained robust architecture, I deliver clean code and reliable results. Let’s turn your unstructured text into valuable data!
Machine Learning Tools
Azure Machine Learning, BERT, ChatGPT, fastText, GPT-3, Keras, NLTK, NumPy, pandas, Python, Python Scikit-Learn, PyTorch, R, scikit-learn, SciPy, SQL, TensorFlow, Word2vec, XGBoostWhat's included
| Service Tiers |
Starter
$100
|
Standard
$250
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 3 days | 7 days | 14 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 2 | 3 |
Number of Scenarios | 1 | 2 | 4 |
Number of Graphs/Charts | 2 | 4 | 6 |
Model Validation/Testing | - | ||
Model Documentation | - | ||
Data Source Connectivity | - | - | |
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$50 - $150
Additional Revision
+$40
Custom Data Cleaning & EDA
(+ 2 Days)
+$100Frequently asked questions
About Selman
Full-Stack AI Engineer | NLP, Next.js, Node.js
Istanbul, Turkey - 2:54 pm local time
Core Expertise:
- Applied AI & NLP: Text classification, sentiment analysis, recommender systems, and custom LLM/RAG pipelines (PyTorch, Hugging Face, Scikit-learn).
- Backend & API Architecture: Scalable microservices, REST/GraphQL APIs, and robust data pipelines (Node.js, NestJS, Python, PostgreSQL, MongoDB).
- Frontend & Mobile Integration: Building seamless, user-centric interfaces for complex AI features (Next.js, React, Flutter).
Whether you need a sophisticated enterprise question-answering assistant, a recommendation engine, or a full-stack platform built from the ground up, I deliver clean architecture and high-performance solutions. Let's build a smart, scalable product together.
Steps for completing your project
After purchasing the project, send requirements so Selman can start the project.
Delivery time starts when Selman receives requirements from you.
Selman works on your project following the steps below.
Revisions may occur after the delivery date.
Data Cleaning & Preprocessing
I will clean the text, remove noise (like HTML tags or special characters), and tokenize the data for the NLP model.
Exploratory Data Analysis (EDA)
I will analyze your dataset's distribution to check for imbalances and understand the word frequencies and patterns.