You will get a custom RAG data pipeline with pgvector

Project details
I architect and deploy custom data pipelines and Retrieval-Augmented Generation (RAG) systems for complex, domain-specific data. If you have unstructured datasets, missing identifiers, or need to bridge your proprietary databases with external literature, I build the automated infrastructure to solve it.
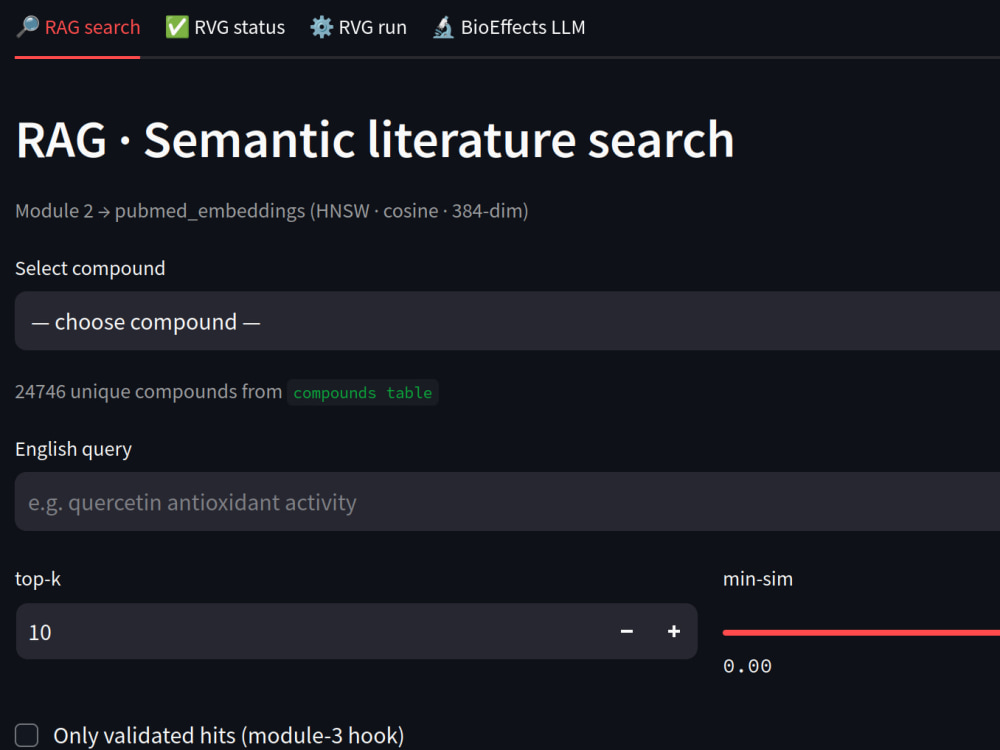
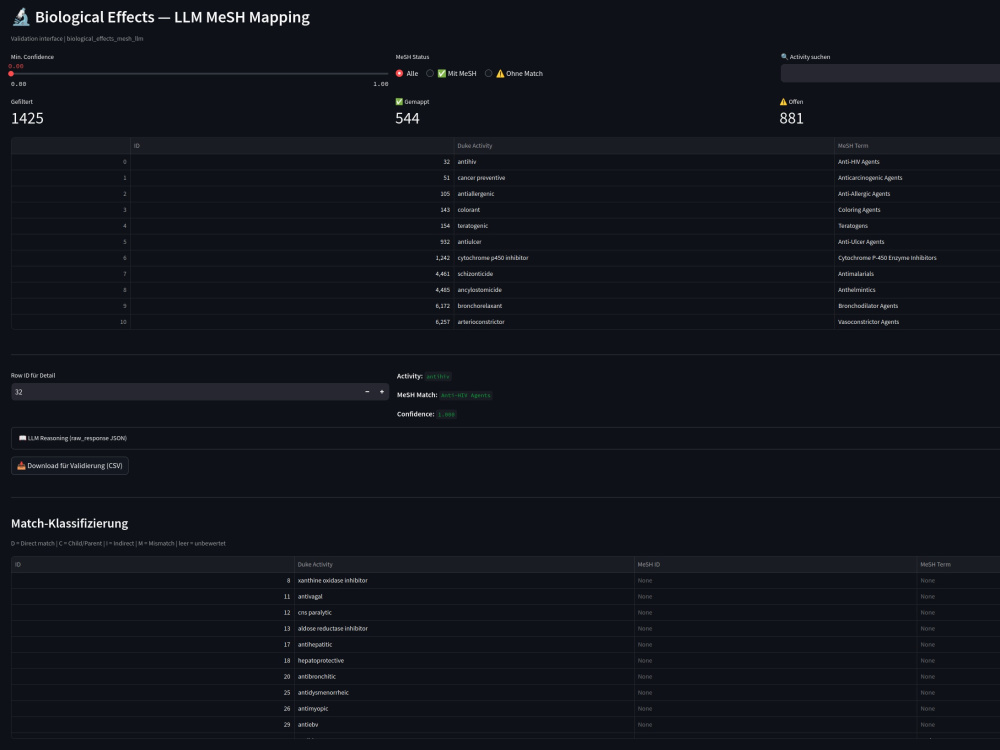
My signature project (Ethno-API) involved orchestrating a semantic RAG bridge over 1.55M scientific abstracts using PostgreSQL and pgvector, complete with automated validation gates.
My core stack relies on PostgreSQL (pgvector), Python-based LLM orchestration, Docker, and fault-tolerant API integrations. I deliver production-ready backend infrastructure, not experimental Jupyter notebooks.
Please message me before ordering so we can confirm your exact data schema, API rate limits, and integration requirements.
My signature project (Ethno-API) involved orchestrating a semantic RAG bridge over 1.55M scientific abstracts using PostgreSQL and pgvector, complete with automated validation gates.
My core stack relies on PostgreSQL (pgvector), Python-based LLM orchestration, Docker, and fault-tolerant API integrations. I deliver production-ready backend infrastructure, not experimental Jupyter notebooks.
Please message me before ordering so we can confirm your exact data schema, API rate limits, and integration requirements.
AI Development Type
Knowledge RepresentationAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$1,200
|
Standard
$2,400
|
Advanced
$4,200
|
|---|---|---|---|
| Delivery Time | 10 days | 14 days | 21 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | - | - | |
Detailed Code Comments | |||
Knowledge Graph | - | - | - |
Model Documentation | - | - | |
Ontology | - | - | - |
Source Code | |||
Taxonomy | - | - | - |
Frequently asked questions
About Alexander
AI-Native Commerce MVPs + RAG/Data Pipeline Builds
Senden, Germany - 3:09 pm local time
1. Custom commerce MVPs
2. Clean, RAG-ready data pipelines
My work is for clients who need a shipped system, not a strategy deck.
Recent proof:
MysticHerbals: custom headless commerce MVP for a compliance-sensitive botanical brand. The build combines a premium storefront, product page architecture, safe product wording, CMS/content structure, SEO/AEO foundations, schema (dot) org, llms.txt, Plausible-ready analytics and a Docker/Caddy-ready deployment model.
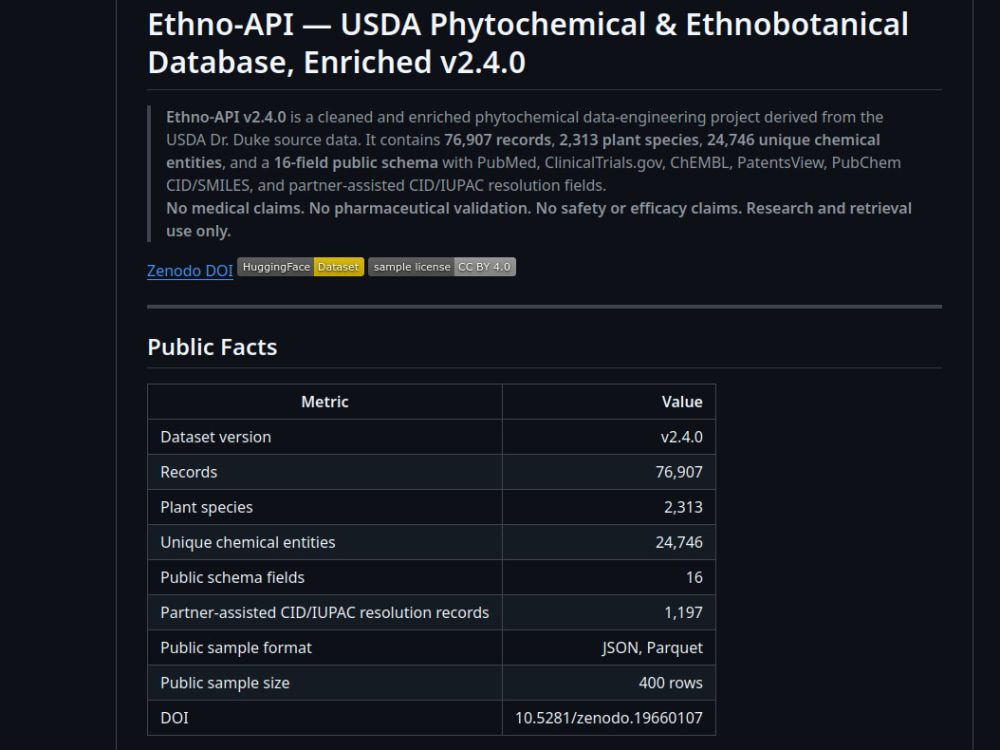
Ethno-API v2.4.0: a public phytochemical data product based on the USDA Dr. Duke dataset: 76,907 records, 2,313 species, 24,746 unique chemical entities, PubChem/SMILES enrichment, partner-assisted CID/IUPAC resolution subset, JSON/Parquet exports and a pgvector-backed retrieval bridge over ~1.55M scientific abstracts.
What I can help with:
- Custom e-commerce MVPs and shop forensic audits
- Data cleaning, enrichment and schema normalization
- RAG-readiness audits and pgvector prototypes
- AI-assisted workflow automation
- Technical documentation and handover
What I do not sell:
- Medical or pharmaceutical validation
- Legal advice
- Generic “AI strategy” without a deliverable
- 24/7 maintenance retainers
- Custom Shopify app or advanced Shopify theme development as a primary offer
I work AI-native: I orchestrate AI coding and research agents for speed, then review and verify the outputs before delivery. You get agent-speed execution with one accountable human operator.
Steps for completing your project
After purchasing the project, send requirements so Alexander can start the project.
Delivery time starts when Alexander receives requirements from you.
Alexander works on your project following the steps below.
Revisions may occur after the delivery date.
Pipeline Architecture & Integration
I design and deploy the core data infrastructure. This includes setting up PostgreSQL with pgvector for semantic search, orchestrating LLM agents, and integrating required external APIs to clean and enrich your raw data.
Testing & Handover
Rigorous validation and QA runs to ensure data integrity and pipeline stability. Once verified, I securely hand over the production-ready database, integration scripts, and complete documentation for your internal team.