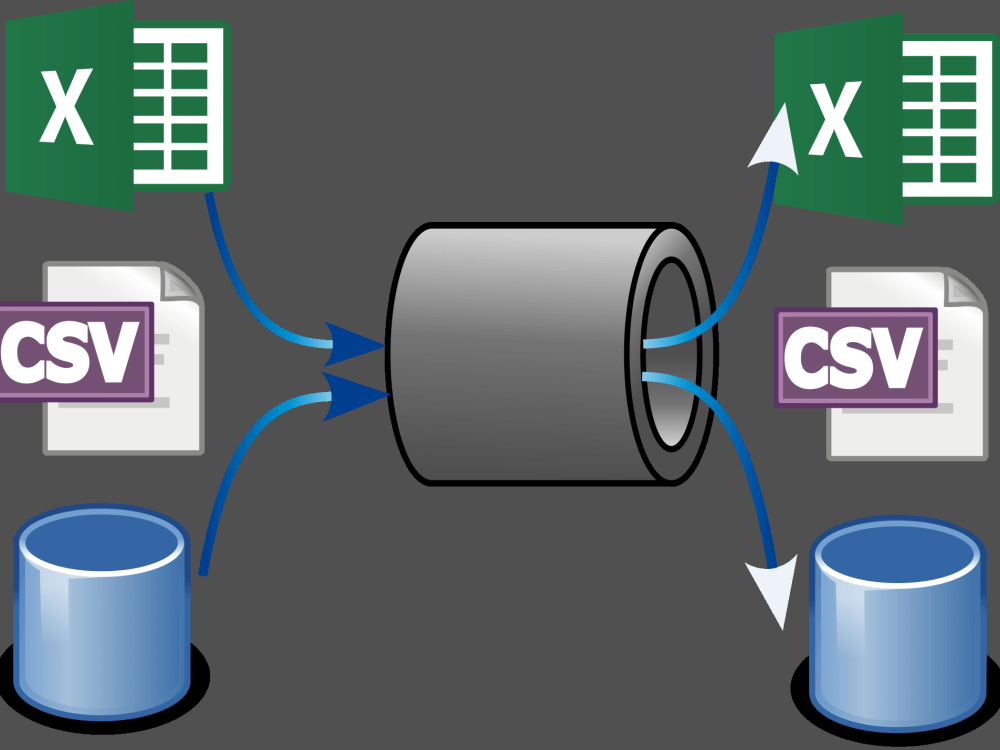
You will get a customized data pipeline that retrieves, cleans and stores data
Rising Talent
Rising Talent
Project details
You will get a data pipeline as a single multi-platform capable JAR file using a local version of Apache Spark. You can run this on any machine using a Java Virtual Machine (JVM). You will also get the source code, so you can adapt it to your needs. The pipeline by default runs on a single machine but can be adapted to run on multiple machines (preferrably a Kubernetes cluster) to scale with data sizes.
Data Tool
SQLWhat's included
| Service Tiers |
Starter
$200
|
Standard
$350
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Sources Mined/Scraped | 1 | 3 | 5 |
Number of Revisions | 3 | 4 | 5 |
Optional add-ons
You can add these on the next page.
Additional Source Mined/Scraped
(+ 2 Days)
+$100
Additional Revision
+$100About Martin
Data Engineering & Science, Machine Learning, Algorithm Development
Mintraching, Germany - 12:34 am local time
* I'm experienced with various big data tools (especially Spark)
* I can set up the required infrastructure on-premise or in the cloud
* I develop prediction models on top of the data and various optimization algorithms (in discrete and continuous spaces) to find the best solutions for your business
Steps for completing your project
After purchasing the project, send requirements so Martin can start the project.
Delivery time starts when Martin receives requirements from you.
Martin works on your project following the steps below.
Revisions may occur after the delivery date.
Discuss details
The pipeline can be configured and tweaked in various ways. These details will be clarified up-front.
Implement pipeline