You will get an ETL for your Data Warehouse by an experienced data engineer
Project details
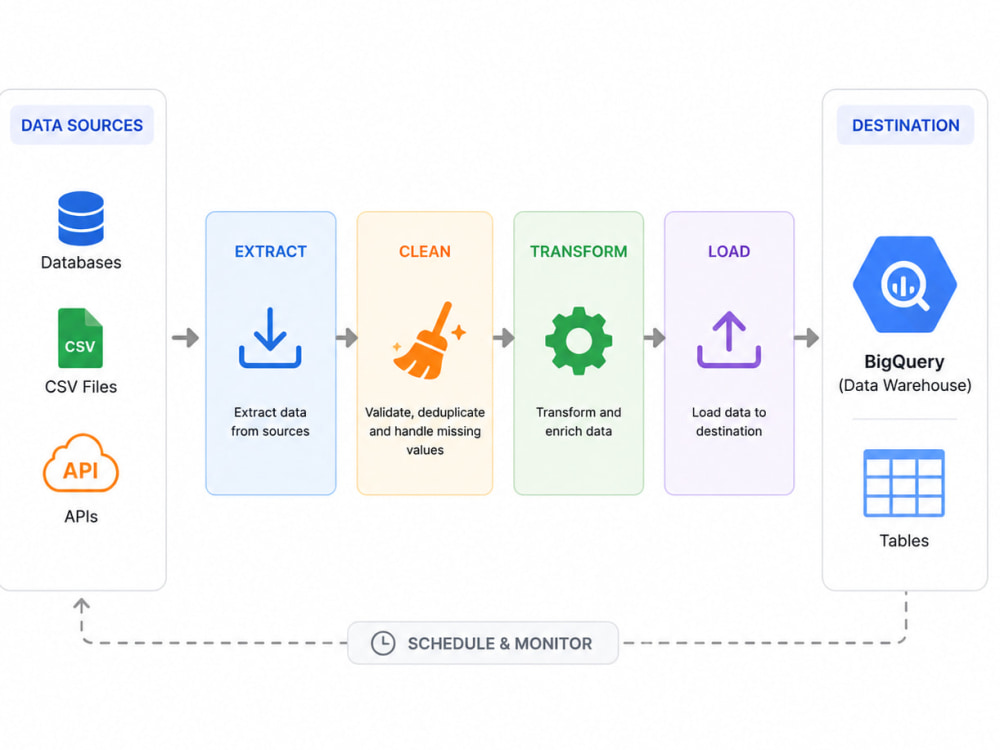
I’m a Data Engineer with 4+ years of experience building modern data platforms, ETL/ELT pipelines, and analytics workflows for startups and real-world production environments. I specialize in designing scalable data pipelines, automating data workflows, and building reliable data lakes and data warehouses using modern cloud technologies.
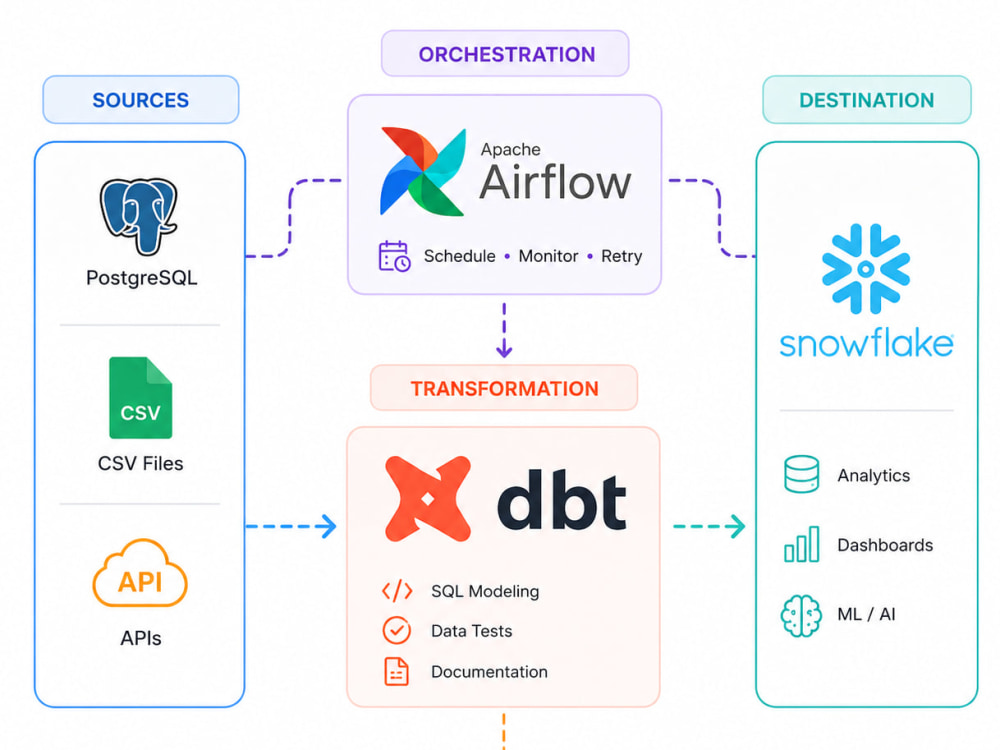
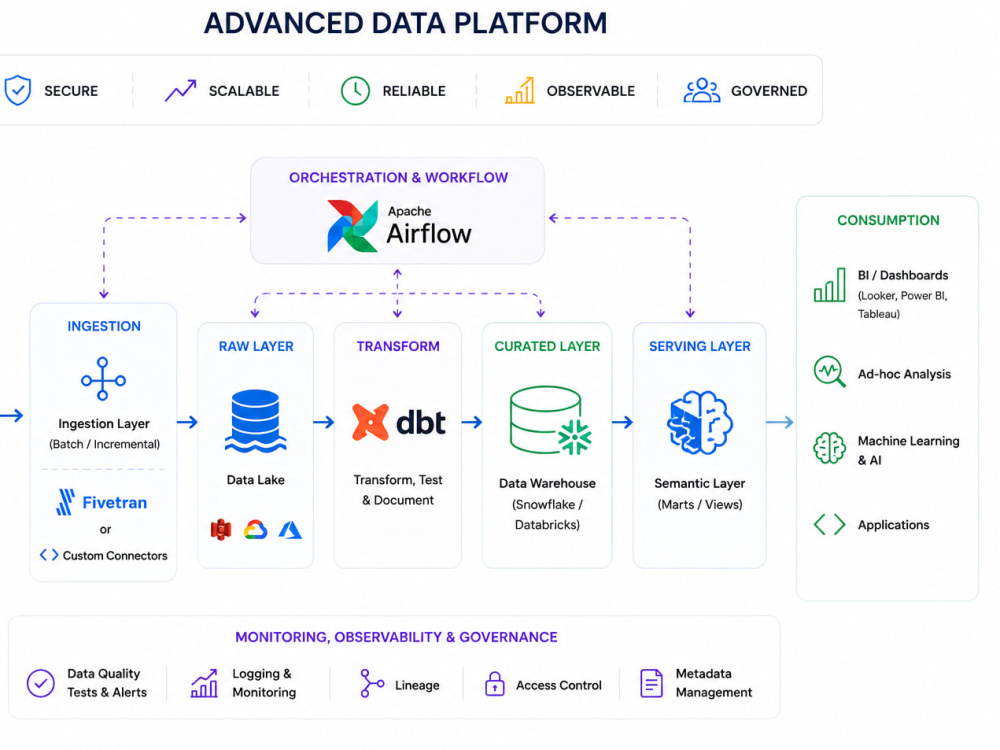
My experience includes working with tools such as Snowflake, Databricks, Apache Airflow, dbt, Spark, and SQL-based ecosystems across production data platforms.
✔ ETL / ELT Pipeline Development
✔ Data Warehouse & Data Lake Architecture
✔ Workflow Orchestration with Airflow
✔ Data Transformation with dbt
✔ Distributed Processing with Spark
✔ Cloud Data Platforms: Snowflake & Databricks
✔ SQL Optimization & Data Modeling
✔ API & Database Integration
✔ Python for Data Engineering & Automation
Databases:
• PostgreSQL
• MySQL
• SQL Server
• Oracle
I’ve worked in startup environments where speed, scalability, and ownership matter. My experience includes designing production-grade data workflows, supporting analytics teams, and helping businesses centralize and transform data efficiently.
My experience includes working with tools such as Snowflake, Databricks, Apache Airflow, dbt, Spark, and SQL-based ecosystems across production data platforms.
✔ ETL / ELT Pipeline Development
✔ Data Warehouse & Data Lake Architecture
✔ Workflow Orchestration with Airflow
✔ Data Transformation with dbt
✔ Distributed Processing with Spark
✔ Cloud Data Platforms: Snowflake & Databricks
✔ SQL Optimization & Data Modeling
✔ API & Database Integration
✔ Python for Data Engineering & Automation
Databases:
• PostgreSQL
• MySQL
• SQL Server
• Oracle
I’ve worked in startup environments where speed, scalability, and ownership matter. My experience includes designing production-grade data workflows, supporting analytics teams, and helping businesses centralize and transform data efficiently.
Database Type
PostgreSQLWhat's included
| Service Tiers |
Starter
$100
|
Standard
$180
|
Advanced
$700
|
|---|---|---|---|
| Delivery Time | 6 days | 12 days | 32 days |
Number of Revisions | 2 | 3 | 5 |
Source Code |
About Selene
Databricks Data Engineer | Python Spark ETL Pipelines
Valencia, Spain - 12:42 am local time
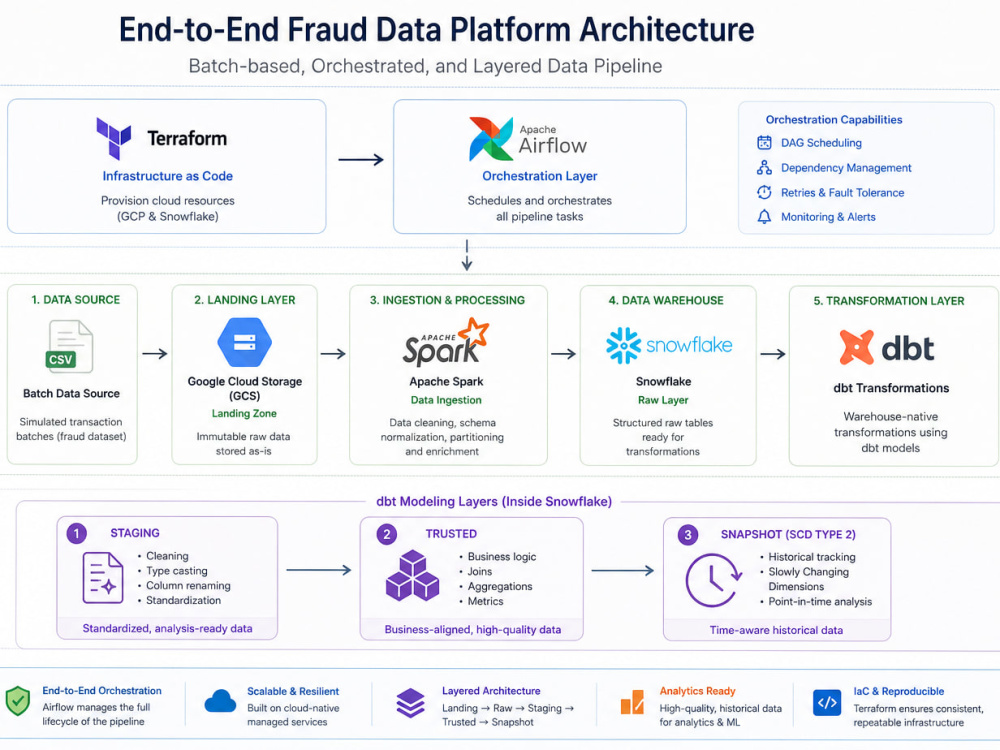
Experienced in developing end-to-end ETL and data processing workflows using PySpark, SQL, Databricks, Airflow, and Delta Lake, with a strong focus on reliability, performance optimization, and maintainability.
Core expertise includes:
• Distributed data processing with PySpark and Apache Spark
• ETL pipeline development and workflow orchestration
• Delta Lake, Unity Catalog, and data governance
• Data modeling, schema evolution, and incremental processing
• Data quality validation, testing, and pipeline reliability
• Performance optimization and production support
Platforms & Technologies:
• Databricks
• AWS (S3)
• Apache Spark, Airflow
• Delta Lake, Unity Catalog
• dbt, Snowflake
• Git, CI/CD workflows
In addition to production data engineering experience, I’ve built independent projects using modern analytics and AI stacks, including dbt, Snowflake, GCP, and retrieval-augmented generation (RAG) systems.
I enjoy building clean, scalable, and well-documented data systems that support analytics, BI, and downstream data applications.
Steps for completing your project
After purchasing the project, send requirements so Selene can start the project.
Delivery time starts when Selene receives requirements from you.
Selene works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements understanding
Here i'm going to design a draft of how the system will look so we you can take a look and we can desgin changes if needed
Implementation with mock data
Here i'm going to start implementing your soultion