You will get a hybrid AI retrieval system with full admin observability
Project details
Most RAG systems are built the same way: connect a PDF to an LLM, wrap it in a chat interface, call it done. That approach works for demos. It does not work when retrieval quality actually matters.
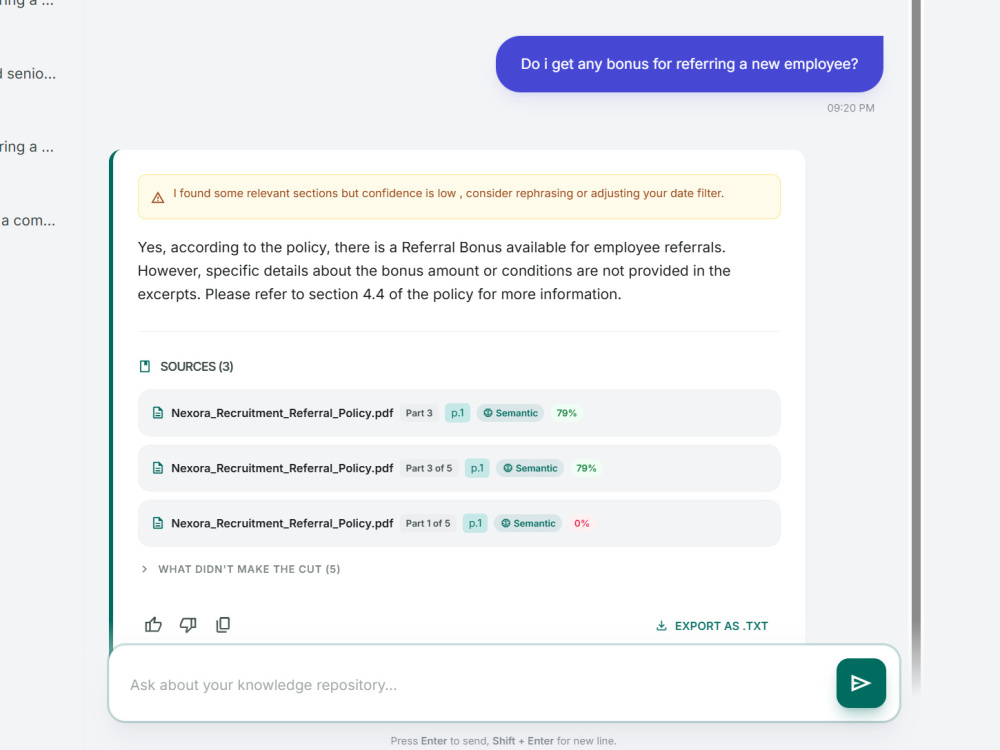
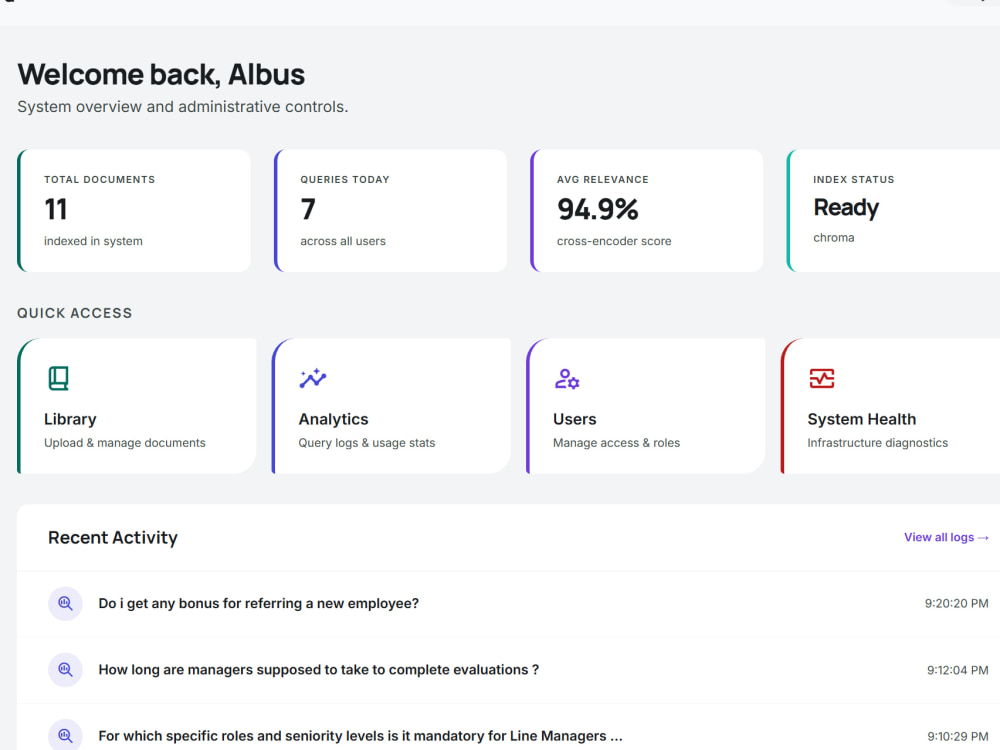
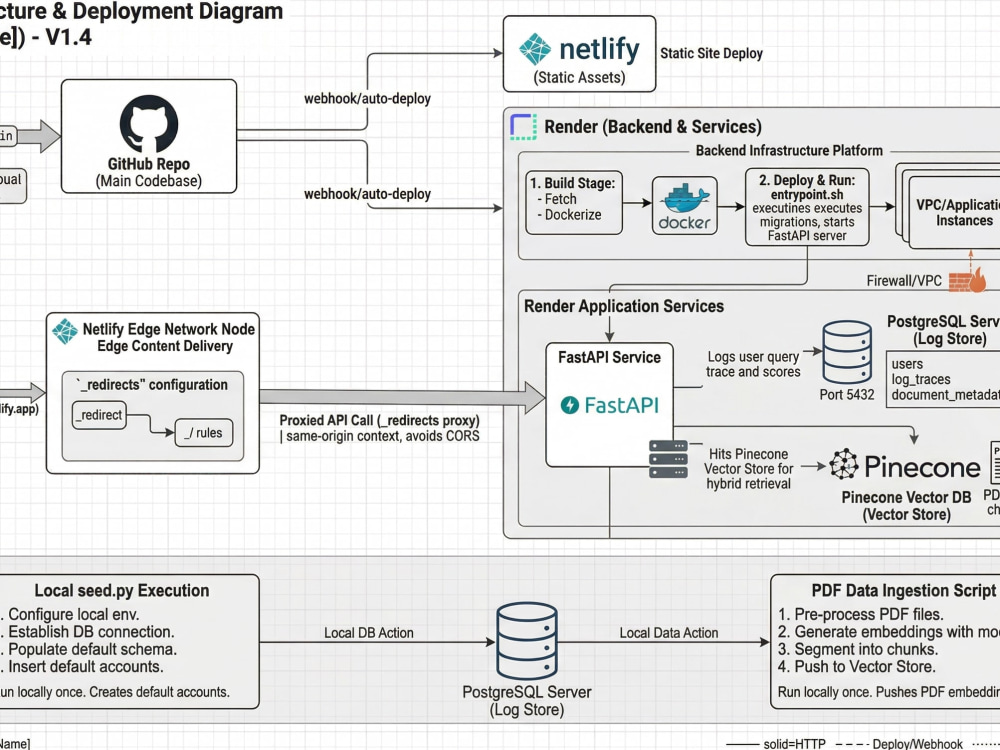
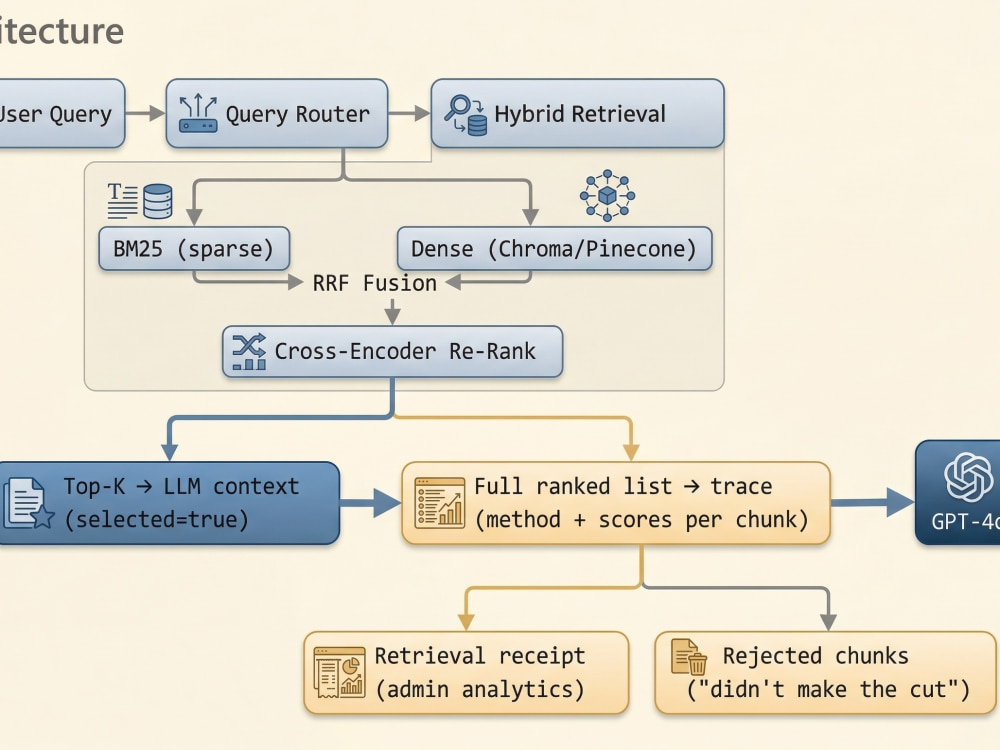
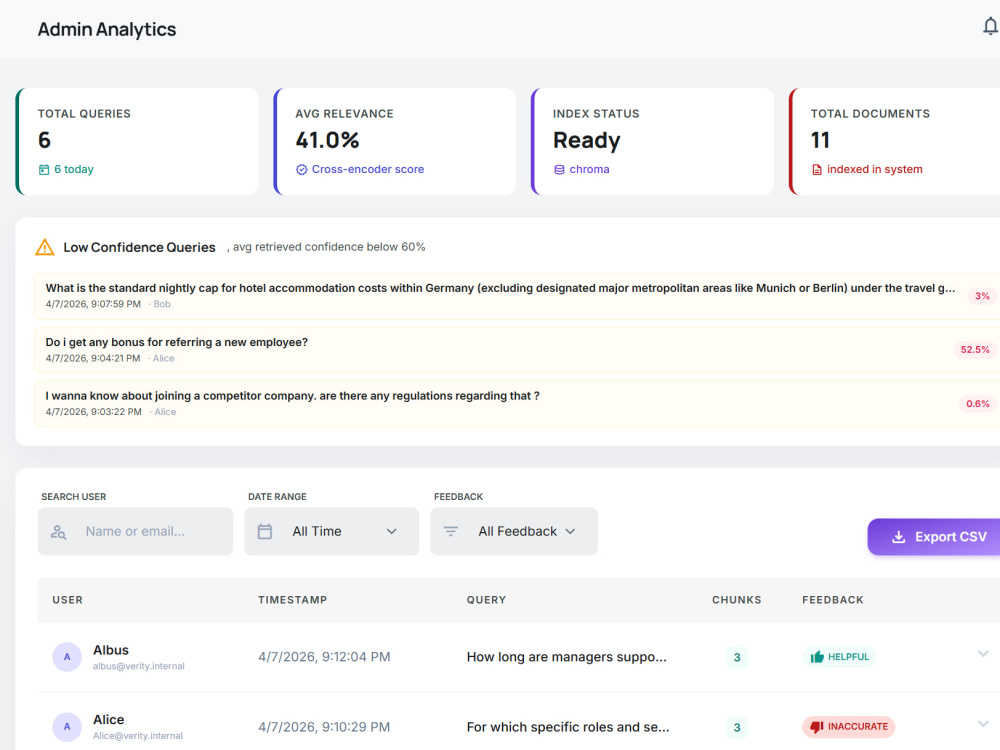
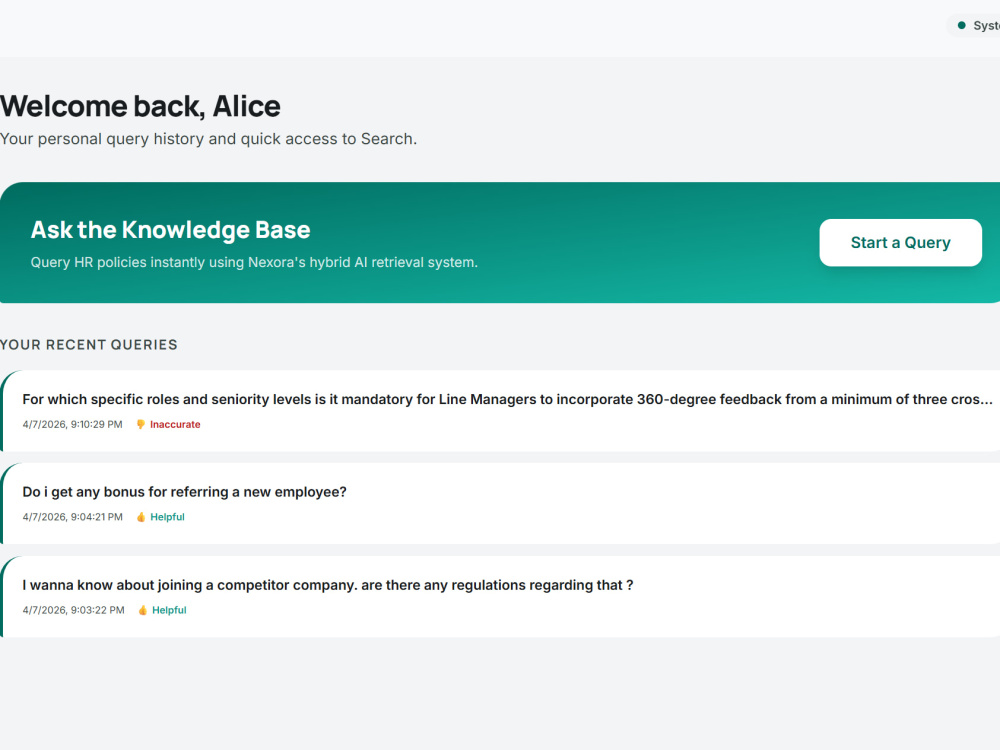
I build retrieval systems where the architecture is a deliberate choice, not the default path. Verity, the system behind this project, uses hybrid BM25 plus dense vector retrieval with Reciprocal Rank Fusion, cross-encoder re-ranking, and confidence-scored source attribution. Every query returns ranked, cited chunks with a measurable relevance score. Low-confidence results are flagged rather than silently served. Admins get full observability: per-document retrieval performance, query logs, user feedback, and index health monitoring.
I have 6+ years in Information Retrieval and NLP, including production search systems in big German companies and a 34% relevance improvement on a 10,000-document legal corpus. My work has been published at NAACL, ECIR, and RANLP. I build systems that can be reasoned about, evaluated, and improved, not black boxes that happen to answer questions.
If you need a retrieval system that is engineered rather than assembled, this project is the right fit.
I build retrieval systems where the architecture is a deliberate choice, not the default path. Verity, the system behind this project, uses hybrid BM25 plus dense vector retrieval with Reciprocal Rank Fusion, cross-encoder re-ranking, and confidence-scored source attribution. Every query returns ranked, cited chunks with a measurable relevance score. Low-confidence results are flagged rather than silently served. Admins get full observability: per-document retrieval performance, query logs, user feedback, and index health monitoring.
I have 6+ years in Information Retrieval and NLP, including production search systems in big German companies and a 34% relevance improvement on a 10,000-document legal corpus. My work has been published at NAACL, ECIR, and RANLP. I build systems that can be reasoned about, evaluated, and improved, not black boxes that happen to answer questions.
If you need a retrieval system that is engineered rather than assembled, this project is the right fit.
Machine Learning Tools
Python, PyTorch, SQLWhat's included
| Service Tiers |
Starter
$500
|
Standard
$1,000
|
Advanced
$1,500
|
|---|---|---|---|
| Delivery Time | 18 days | 18 days | 30 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 3 | 10 |
Number of Scenarios | 2 | 3 | 5 |
Number of Graphs/Charts | 2 | 5 | 10 |
Model Validation/Testing | - | ||
Model Documentation | - | ||
Data Source Connectivity | |||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$500 - $1,000
Additional Revision
+$200
Additional Model Variation
(+ 2 Days)
+$20Frequently asked questions
About Umer
Senior AI and Software Developer
Karachi, Pakistan - 8:39 pm local time
On the AI side: Information Retrieval, RAG pipelines, LLM evaluation, and LLM security. I have built search systems that moved relevance metrics by 34% in production, designed enterprise RAG assistants for clients like Siemens, and published 8 research papers at NAACL, ECIR, and RANLP.
On the software side: system design, backend engineering, web platforms, REST APIs, and database-driven applications. I have led teams and delivered at scale.
What I take on:
AI systems: search, RAG, LLM pipelines, guardrails, evaluation
Software architecture and full-stack delivery
Web and backend platforms with or without AI components
I own projects from architecture to delivery. If that is what you need, let us talk.
Steps for completing your project
After purchasing the project, send requirements so Umer can start the project.
Delivery time starts when Umer receives requirements from you.
Umer works on your project following the steps below.
Revisions may occur after the delivery date.
Discovery and Architecture Design
Review your documents and use case, finalise retrieval strategy, chunking approach, and system architecture. Deliver a short design summary before build begins.
Retrieval Pipeline and Backend
Build the hybrid BM25 + dense retrieval layer, cross-encoder re-ranking, confidence scoring, and FastAPI backend with document ingestion and JWT auth.