You will get a machine learning model to predict property prices from your data
Project details
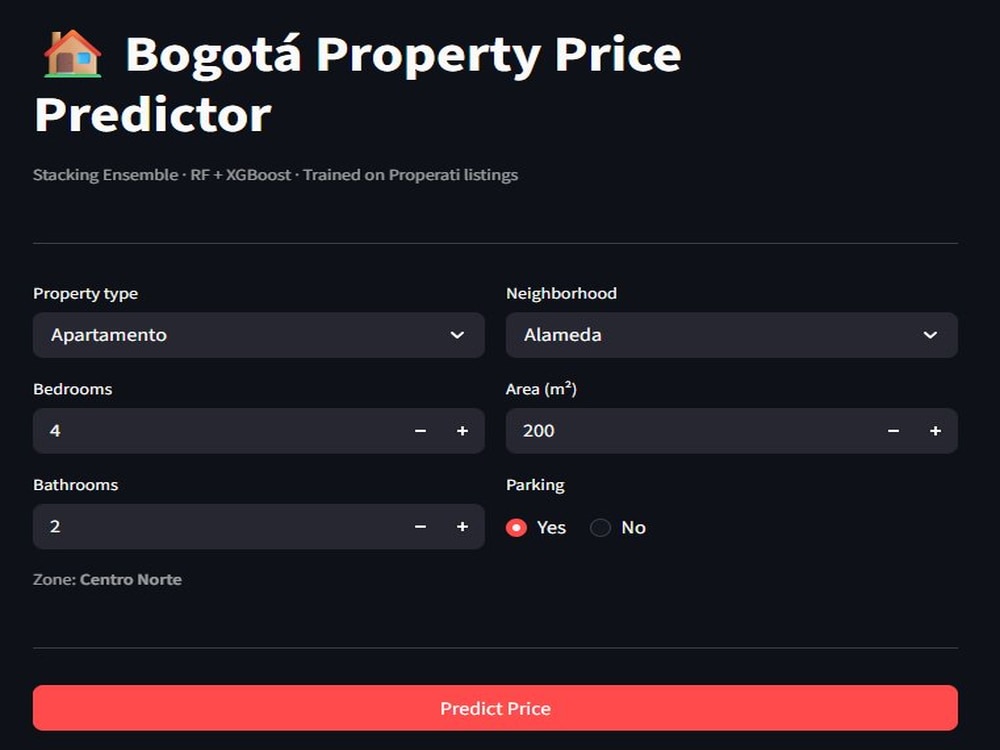
You will get a production-ready property price prediction model, not a half-finished notebook. I built and deployed a Bogotá price predictor on 4,509 listings using a Stacking Ensemble (Random Forest + XGBoost), achieving R² 0.70 and RMSE under 400M COP — available as a live Streamlit app anyone can use.
I apply the same approach to your data. Whether you run a real estate portal, a proptech startup, or a property investment firm, I'll build a model that predicts prices accurately enough to make real decisions.
What makes this different:
• Deployed apps, not just notebooks — clients can actually use the model
• Multi-model comparison (Ridge, RF, XGBoost, Stacking) — I pick what actually works for your data
• Full residual analysis — you'll know where the model is strong and where it isn't
• LatAm real estate expertise + bilingual delivery (English/Spanish)
Send me a data sample and I'll confirm feasibility and expected accuracy within 24 hours. Let's turn your property data into a pricing engine your team can rely on.
I apply the same approach to your data. Whether you run a real estate portal, a proptech startup, or a property investment firm, I'll build a model that predicts prices accurately enough to make real decisions.
What makes this different:
• Deployed apps, not just notebooks — clients can actually use the model
• Multi-model comparison (Ridge, RF, XGBoost, Stacking) — I pick what actually works for your data
• Full residual analysis — you'll know where the model is strong and where it isn't
• LatAm real estate expertise + bilingual delivery (English/Spanish)
Send me a data sample and I'll confirm feasibility and expected accuracy within 24 hours. Let's turn your property data into a pricing engine your team can rely on.
Machine Learning Tools
Microsoft Excel, NumPy, pandas, Python, Python Scikit-Learn, scikit-learn, SQLWhat's included
| Service Tiers |
Starter
$199
|
Standard
$399
|
Advanced
$699
|
|---|---|---|---|
| Delivery Time | 5 days | 10 days | 15 days |
Number of Revisions | 1 | 2 | 3 |
Model Validation/Testing | - | ||
Model Documentation | - | - | |
Data Source Connectivity | |||
Source Code |
Frequently asked questions
About Diego Arley
Data Analyst | Credit Risk & Real Estate Price Prediction
Villa de San Diego de Ubate, Colombia - 2:04 pm local time
WHAT I DO
Credit Risk & Lending Analytics
I analyzed 1.37 million Lending Club loans (2007–2018), uncovering a 21.47% default rate, identifying the most dangerous borrower profiles, and tracking how returns collapsed from +10% in 2013 to −22% by 2018 — delivered as a 4-page interactive Power BI dashboard.
Real Estate Price Prediction
I built a property price prediction model on 4,509 Bogotá listings using a Stacking Ensemble (RF + XGBoost), achieving R² 0.70 and RMSE under 400 M COP. Deployed as a live Streamlit app — not just a notebook.
End-to-End Data Projects
I handle everything: data cleaning, SQL pipelines, Python analysis, visualization, and actionable recommendations. You get a complete deliverable, not a half-finished notebook.
MY STACK
Python (Pandas, Matplotlib, Seaborn, Scikit-learn, XGBoost), SQL (SQLite), Power BI, Streamlit, Git / GitHub
WHY HIRE ME
I've worked at scale — 1.37M rows is not a toy project. I ship deployed apps, not just notebooks. I'm bilingual (Spanish/English) and can work with LatAm and international clients. Every project comes with clean documentation and explanation.
Let's talk about your data challenge. Message me and I'll tell you within 24 hours if I can help — and how.
Steps for completing your project
After purchasing the project, send requirements so Diego Arley can start the project.
Delivery time starts when Diego Arley receives requirements from you.
Diego Arley works on your project following the steps below.
Revisions may occur after the delivery date.
Data Review & Scope Alignment
I review your real estate dataset and confirm the prediction target, market coverage, and which features are available. We define the target accuracy metric (R², RMSE, or MAE) before starting.
Data Cleaning & Feature Engineering
I clean the raw listings, handle missing values and outliers, and engineer features (log-transforms, location encoding, interactions) that historically improve price prediction accuracy.