You will get a Music and Non-music Classification model


Project details
The music and non-music classification model is an advanced algorithm designed to distinguish between audio samples that contain music and those that do not. This model utilizes machine learning techniques, such as deep learning and audio feature extraction, to analyze and classify audio data accurately.
By training on a large dataset of music and non-music audio samples, the model learns to recognize various patterns and characteristics specific to each category.
The music and non-music classification model finds applications in multiple domains. For instance, it can be used in content filtering systems to identify and filter out music-related content from non-music platforms or vice versa. It can assist in automating the categorization and organization of audio files in music libraries or streaming platforms. Moreover, the model can be integrated into audio analysis tools for tasks like audio transcription, where differentiating between speech and music is crucial.
By training on a large dataset of music and non-music audio samples, the model learns to recognize various patterns and characteristics specific to each category.
The music and non-music classification model finds applications in multiple domains. For instance, it can be used in content filtering systems to identify and filter out music-related content from non-music platforms or vice versa. It can assist in automating the categorization and organization of audio files in music libraries or streaming platforms. Moreover, the model can be integrated into audio analysis tools for tasks like audio transcription, where differentiating between speech and music is crucial.
Machine Learning Tools
Keras, NLTK, NumPy, pandas, Python, Python Scikit-Learn, PyTorch, TensorFlow, Word2vecWhat's included $150
These options are included with the project scope.
$150
- Delivery Time 1 day
- Number of Revisions Unlimited
- Number of Model Variations 2
- Model Validation/Testing
- Model Documentation
- Source Code
Optional add-ons
You can add these on the next page.
Additional Model Variation
(+ 2 Days)
+$50
Additional Scenario
(+ 1 Day)
+$50
Cloud Deployment
(+ 1 Day)
+$49
10 reviews
(8)
(1)
(1)
(0)
(0)
This project doesn't have any reviews.
RF
Ryan F.
Nov 3, 2025
Data Scientist – Crypto Signal Engine (Solana)
DB
Devashish B.
Mar 13, 2025
Machine Learning Engineer
AS
Alina S.
Jul 26, 2024
Evaluating AI Responses (Hindi)
FL
Filemon L.
Apr 11, 2024
Talent Store: AI Training - Coding (SCA025)
KS
Ktverse S.
Jul 7, 2023
Image Processing and Deep Learning in Python
Solution provided by Freelancer was not appropriate and I paid in advance but didn't get any proper solution. Project was not done at all.
About Vishwajeet
Machine Learning Expert | Deep Learning Developer | Data Scientist
100%
Job Success
Greater Noida, India - 5:31 am local time
As a winner of the Smart India Hackathon in both 2022 and 2023, I possess strong technical expertise in Machine Learning (ML), Deep Learning (DL), and web development. My diverse skillset encompasses Python, TensorFlow, Keras, Scikit-learn, and more. I also have experience with MLOps, Flask, OpenCV,and web development frameworks.
Here's what sets me apart:
* My victories in Hackathons showcase my ability to tackle complex challenges and deliver innovative solutions, in tight deadlines.
* My top priority is high quality work and I thrive on building successful partnerships and exceeding expectations.
Ready to discuss your project?
Leveraging my skills and experience to bring your vision to life. Contact me today to discuss how I can contribute to your success.
Email: panda18vishu@gmail.com
Steps for completing your project
After purchasing the project, send requirements so Vishwajeet can start the project.
Delivery time starts when Vishwajeet receives requirements from you.
Vishwajeet works on your project following the steps below.
Revisions may occur after the delivery date.
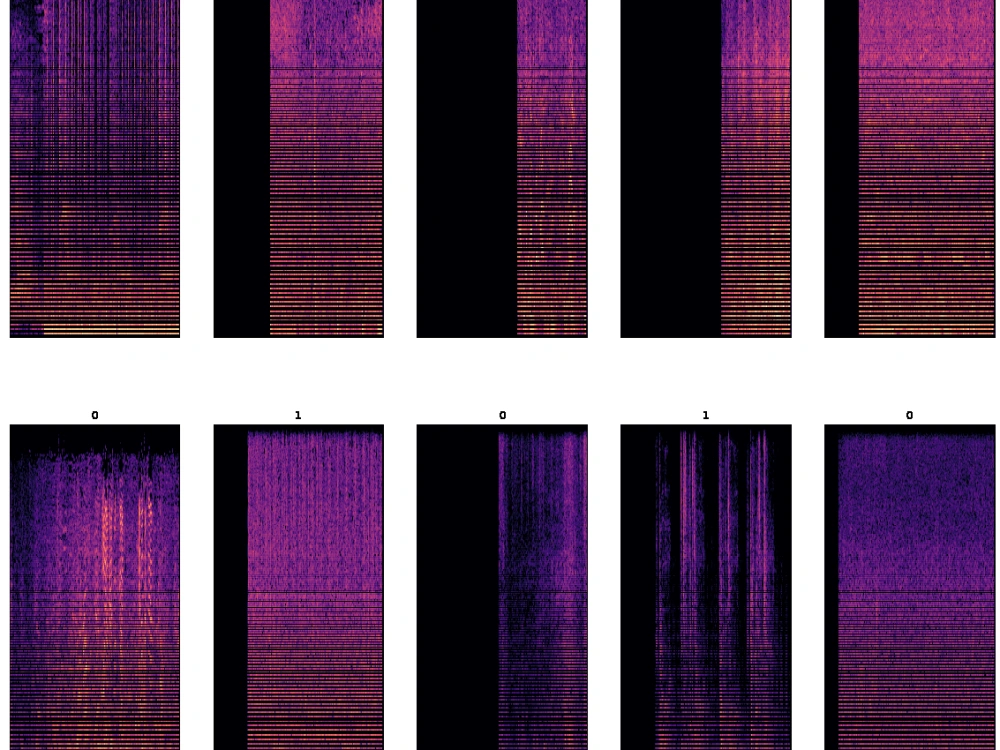
Analyzing and preprocessing the data
Preprocessing audio data for spectrogram analysis involves a series of steps to convert the raw audio signals into a format suitable for spectrogram visualization and subsequent analysis.
Pushing the data for training
We have a model architecture, pushing the data directly to the architecture will automatically starts the training program.