You will get a PDF/OCR data extraction workflow with QA checks
Project details
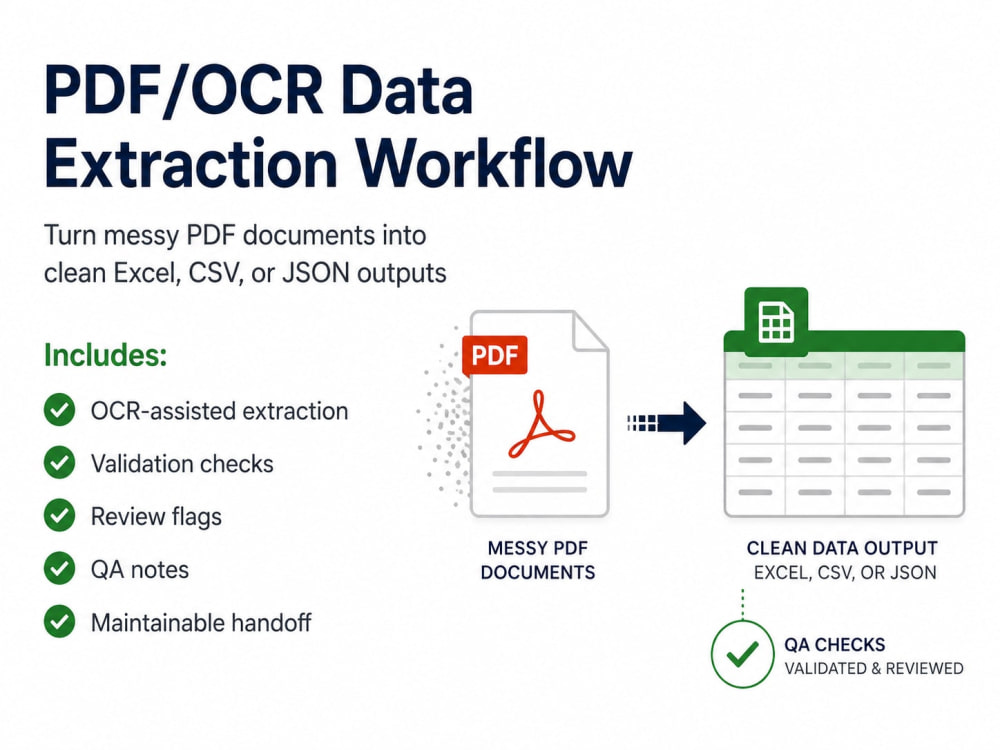
You will get a practical PDF/OCR data-extraction workflow that turns messy PDFs, scans, forms, catalogs, or semi-structured files into clean Excel, CSV, or JSON outputs.
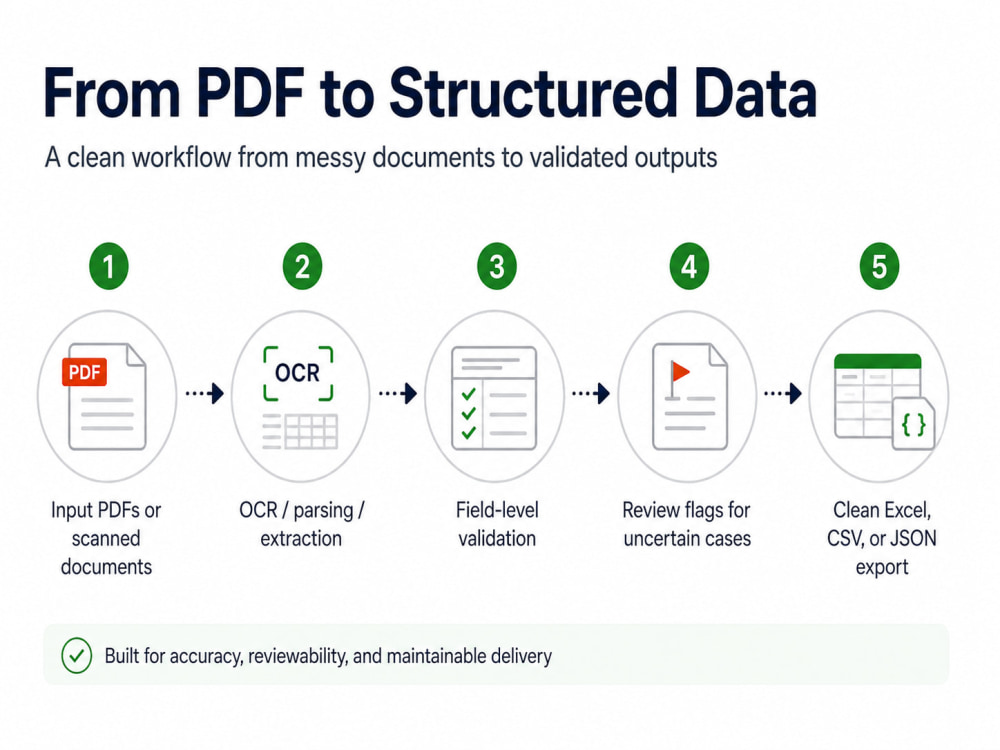
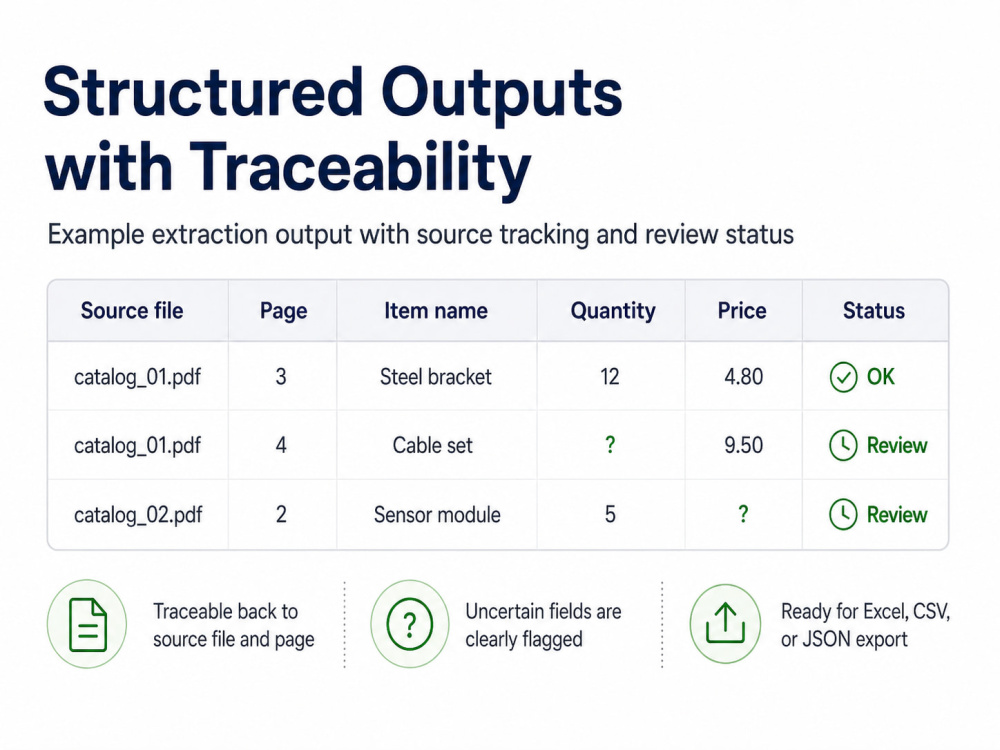
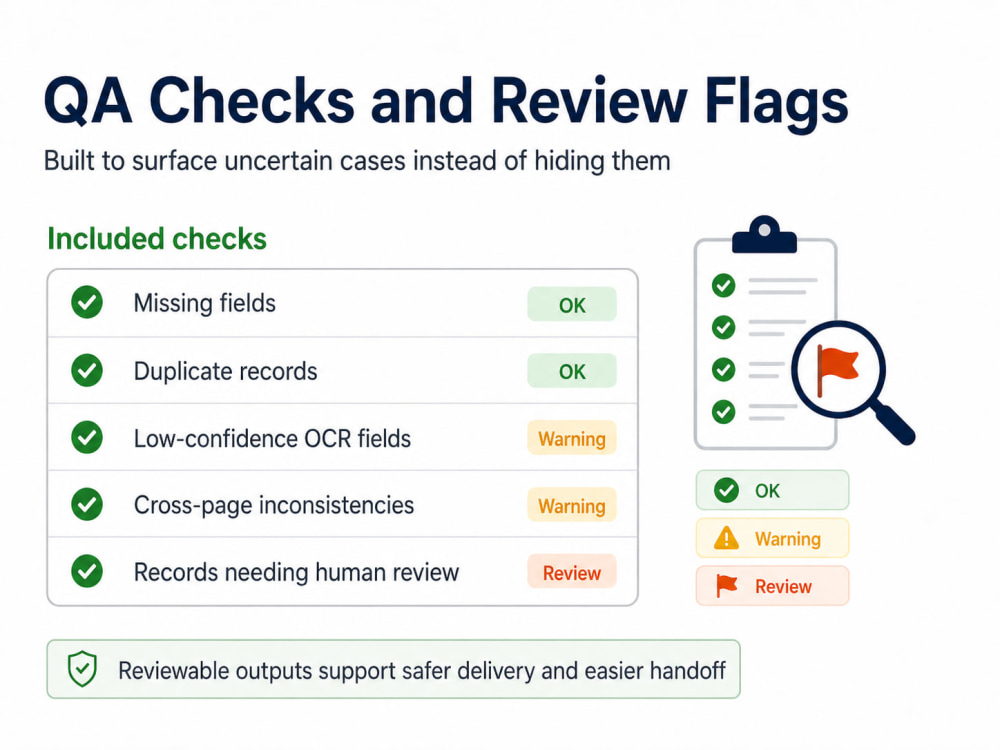
This is not just raw OCR. The workflow is designed around structured fields, validation checks, review flags for uncertain cases, and traceability back to source files or pages where feasible.
I work across Python automation, ETL, document processing, and QA-oriented data workflows. The goal is to give you outputs that are usable, inspectable, and maintainable, not a fragile demo that only works on one perfect sample.
Depending on the selected package, I can deliver a sample extraction, a validated workflow for an agreed batch, or a reusable pipeline with handoff notes and QA documentation.
This is not just raw OCR. The workflow is designed around structured fields, validation checks, review flags for uncertain cases, and traceability back to source files or pages where feasible.
I work across Python automation, ETL, document processing, and QA-oriented data workflows. The goal is to give you outputs that are usable, inspectable, and maintainable, not a fragile demo that only works on one perfect sample.
Depending on the selected package, I can deliver a sample extraction, a validated workflow for an agreed batch, or a reusable pipeline with handoff notes and QA documentation.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$150
|
Standard
$300
|
Advanced
$750
|
|---|---|---|---|
| Delivery Time | 3 days | 7 days | 14 days |
Number of Pages Mined/Scraped | 20 | 100 | 250 |
Number of Sources Mined/Scraped | 1 | 0 | 3 |
Number of Revisions | 1 | 2 | 2 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$100 - $400
Additional Page Mined/Scraped
(+ 1 Day)
+$5
Additional Source Mined/Scraped
(+ 3 Days)
+$100
Additional Revision
+$100Frequently asked questions
30 reviews
(30)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
ED
Emmerich D.
Apr 6, 2026
Indian education data scraping
EL
Emil L.
Jan 30, 2024
Mixpanel integration with Shiny Dashboard R
Juan is a great R develop - thank you!
RB
Rosie B.
Oct 23, 2020
Simple Excel to R
Juan was incredibly professional and pick up the scope of the project very quickly. He understood the business case and helped develop the R shiny app with perfection. He have fantastic customer service skills and was extremely patient and polite. I would recommend his service and would also work with him in the future. Thanks again Juan!
JT
Jan-Erik T.
Feb 10, 2020
Ocean Data Project
Juan is very talented and was a huge help. Overall great experience.
UZ
Ulrich Z.
Aug 16, 2018
convert each class of an S4 object into a dataframe
thank you
About Juan Luis
RAG & AI Automation Engineer | Python/R ETL, Scraping, PDF/OCR
Vigo, Spain - 8:17 am local time
I build reliable AI, RAG, document automation, and Python/R data workflows for teams that need clean data, structured extraction, repeatable reports, and less manual work.
My strongest fit is where AI meets messy operational reality: PDFs, Word documents, spreadsheets, websites, APIs, surveys, research datasets, and business workflows that need to become clean, validated, reviewable outputs.
I combine senior experience in Python/R automation, ETL, scraping, reporting, applied machine learning, and reproducible data workflows with recent formal training in RAG, agentic AI, generative AI applications, LangChain/LangGraph-style workflows, tool/API integration, prompting, and responsible AI use.
I do not treat AI as a black box. For RAG, agentic AI, document extraction, and LLM-assisted workflows, I focus on structure, validation, confidence flags, rejected-row handling, source evidence, review packets, logs, and outputs that clients can inspect and trust.
Relevant proof:
• 38 Upwork jobs and 2,300+ hours delivered
• Long-running automation, scraping, R/Shiny, ETL, reporting, and data workflow projects
• IBM RAG and Agentic AI Professional Certificate
• IBM AI Developer Professional Certificate
• Google AI Professional Certificate
• Strong Python, R, SQL, AWS, Docker, machine learning, and data engineering background
• Public portfolio examples in PDF/OCR extraction, DOCX standardization, review packets, validation workflows, and structured exports
• Consistent focus on QA, reproducibility, documentation, and maintainable handover
What I can help with:
• RAG and LLM-assisted workflow automation
• Agentic AI prototypes and multi-step AI workflows
• PDF/OCR extraction and document-to-table workflows
• AI-assisted Word/PDF document processing
• ETL pipelines and data cleaning
• Web scraping and structured data extraction
• Excel, CSV, Google Sheets, and workbook automation
• Automated reports in PDF, HTML, Excel, Quarto, R Markdown, or dashboards
• R/Python statistical analysis and reproducible reporting
• Applied machine learning and predictive modeling
• Survey and people analytics workflows
• Geospatial and research data pipelines, when relevant
For document and AI-assisted workflows, my goal is not just to make a model produce an answer. I design workflows that are reviewable, testable, and maintainable: structured outputs, validation checks, QA notes, documentation, and practical handover.
For data and reporting projects, I focus on reliable pipelines: clear assumptions, documented transformations, reproducible code, clean outputs, and workflows clients can reuse after delivery.
Clients usually hire me when they need something more reliable than a quick one-off script: data extraction, reporting automation, document processing, web data collection, RAG/AI workflow automation, or messy operational data turned into clean, usable outputs.
Steps for completing your project
After purchasing the project, send requirements so Juan Luis can start the project.
Delivery time starts when Juan Luis receives requirements from you.
Juan Luis works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements and sample files
You send sample PDFs, target fields, preferred output format, and any known rules or examples.
Scope and structure review
I review the files, confirm assumptions, identify layout risks, and define the extraction structure.