You will get a Polars-optimized Python pipeline to eliminate memory crashes
Project details
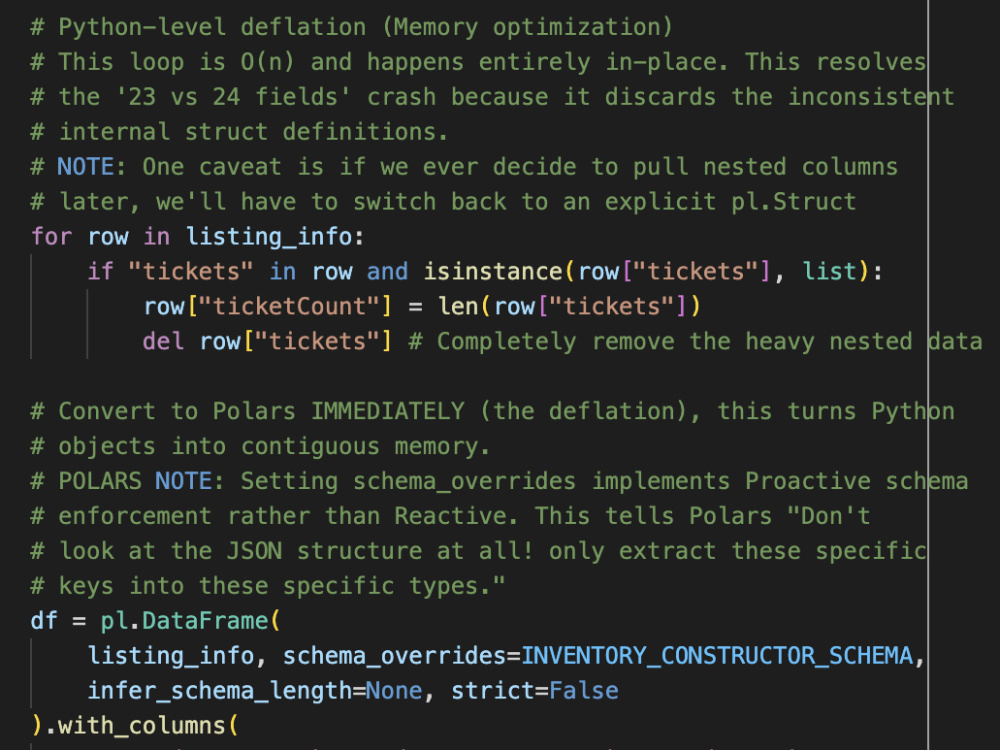
Are your Azure Container Apps crashing due to "Out of Memory" (OOM) errors? I provide specialized performance refactoring to migrate your critical Python workflows from Pandas to Polars. By leveraging the Polars Lazy API and Rust-based execution engine, I significantly reduce memory footprints and execution times—often by 80% or more—without breaking your existing downstream logic. Stop overpaying for cloud compute and start running production-grade, resource-optimized pipelines.
What's included
| Service Tiers |
Starter
$350
|
Standard
$1,200
|
Advanced
$2,500
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
Schema Diagram | - | ||
Permissions Setup | - | - | |
Import/Export Data | |||
Admin Panel Setup | - | - | - |
Optional add-ons
You can add these on the next page.
Automated Unit Testing
(+ 2 Days)
+$300Frequently asked questions
About Roy
Azure Data Engineer | Polars & High-Performance Python Pipelines
Los Angeles, United States - 1:15 pm local time
Core Expertise:
- Azure Stack: End-to-end implementation of Azure SQL Server, Logic Apps, and Container Apps (secured via Key Vault), deployed via Azure DevOps.
- Performance Engineering: Transitioning legacy pipelines to Polars Lazy API to reduce cloud spend and eliminate OOM errors.
- Interoperability: Delivering optimized logic that remains compatible with your team's existing Pandas-based workflows.
- Data Integrity: Designing observable pipelines with advanced SQL performance tuning.
I prioritize production-grade reliability and systemic trust over quick, brittle scripts. Let’s discuss how we can optimize your data infrastructure for scale and stability.
Steps for completing your project
After purchasing the project, send requirements so Roy can start the project.
Delivery time starts when Roy receives requirements from you.
Roy works on your project following the steps below.
Revisions may occur after the delivery date.
Architecture Review & Discovery
I analyze your current Python script, data sources, and Azure environment to identify the exact memory bottlenecks.
Polars Refactor & Optimization
I rewrite the transformation logic using Polars, implementing lazy evaluation and surgical memory management.