You will get a Production-Grade Persistent Memory System for AI Agents
Project details
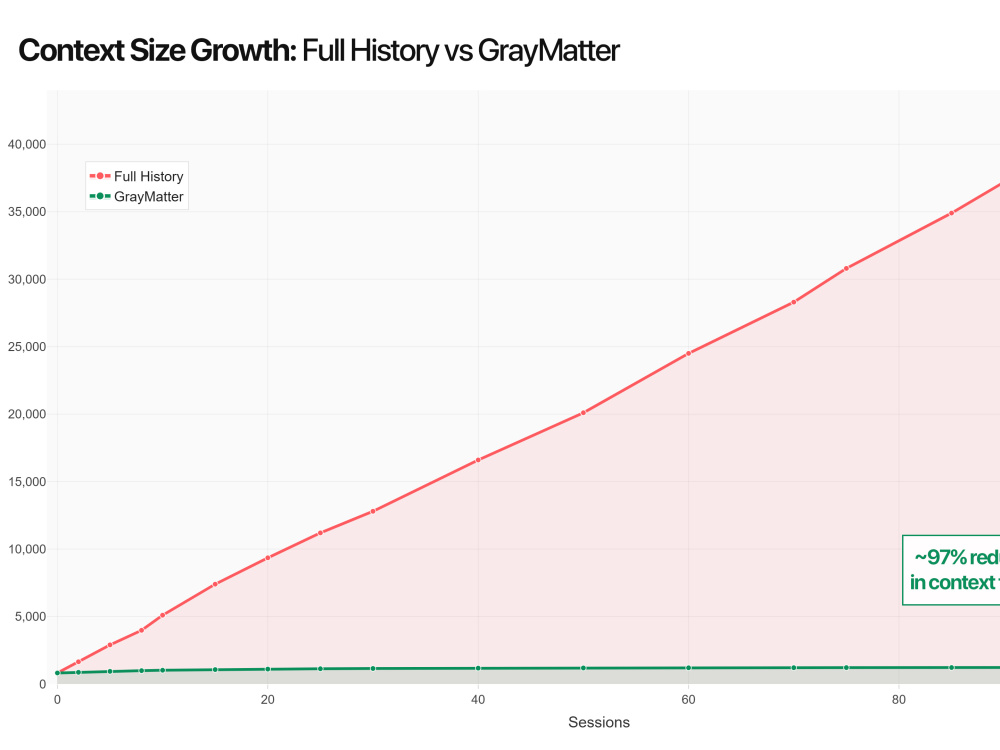
Stop wasting up to 90% of your LLM token budget on repeated context.
Most production AI agents fail to scale because they lack a robust, high-performance, and persistent memory layer. Passing thousands of tokens of chat history and unoptimized context windows back and forth destroys your application's response time and spikes your cloud bills.
I will design and deploy a production-grade, ultra-low-latency persistent memory engine for your autonomous agents or multi-agent teams.
What this project delivers:
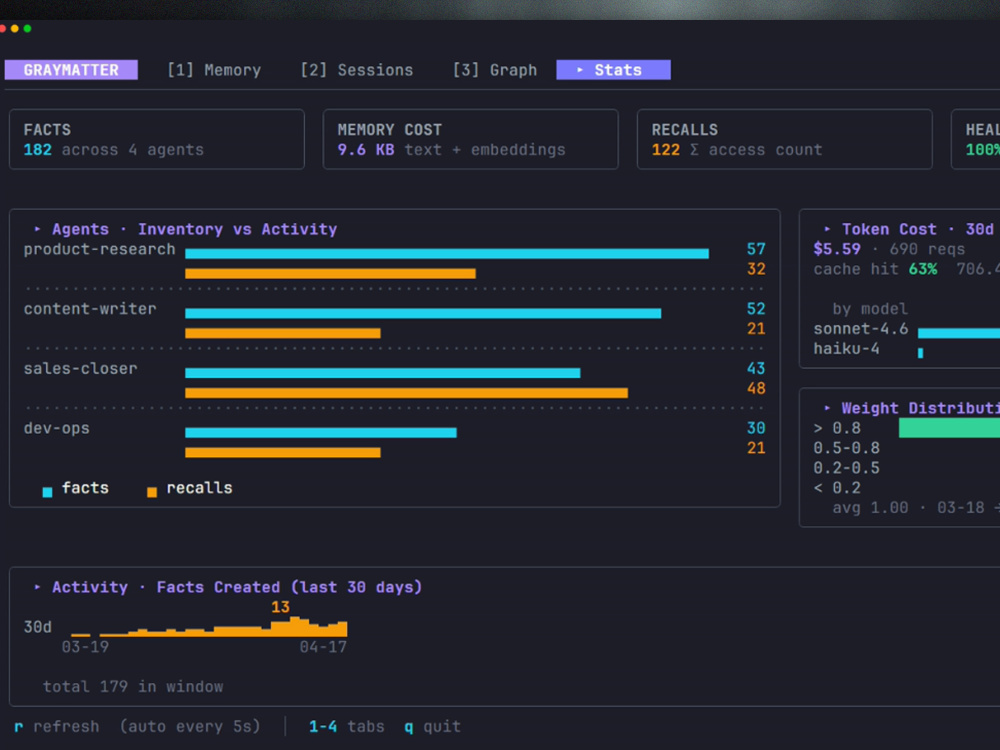
— Hybrid Recall Pipeline: Production-ready retrieval combining vector similarity, keyword scoring, and exponential recency weighting.
— ACID Storage Layer: High-performance embedded storage for facts, metadata, and state checkpoints.
— Context Consolidation Engine: Background workers that automatically summarize and prune memory via exponential decay to keep your context windows clean.
— Framework Native Integration: Adapters for your existing stack (LangGraph, CrewAI, AutoGen, or custom async pipelines).
Get a deterministic, secure, and production-tested memory layer without rewriting your core agent logic.
Most production AI agents fail to scale because they lack a robust, high-performance, and persistent memory layer. Passing thousands of tokens of chat history and unoptimized context windows back and forth destroys your application's response time and spikes your cloud bills.
I will design and deploy a production-grade, ultra-low-latency persistent memory engine for your autonomous agents or multi-agent teams.
What this project delivers:
— Hybrid Recall Pipeline: Production-ready retrieval combining vector similarity, keyword scoring, and exponential recency weighting.
— ACID Storage Layer: High-performance embedded storage for facts, metadata, and state checkpoints.
— Context Consolidation Engine: Background workers that automatically summarize and prune memory via exponential decay to keep your context windows clean.
— Framework Native Integration: Adapters for your existing stack (LangGraph, CrewAI, AutoGen, or custom async pipelines).
Get a deterministic, secure, and production-tested memory layer without rewriting your core agent logic.
AI Development Type
Deep Learning, Model TuningAI Tools
MLflow, NVIDIA AI Platform, PyTorchAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$1,200
|
Standard
$3,000
|
Advanced
$5,000
|
|---|---|---|---|
| Delivery Time | 3 days | 7 days | 11 days |
Number of Revisions | 2 | 4 | 5 |
AI Model Integration | |||
Detailed Code Comments | |||
Knowledge Graph | - | - | |
Model Documentation | - | ||
Ontology | - | - | - |
Source Code | |||
Taxonomy | - | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$200 - $550About Nick
AI Infrastructure & MLOps Engineer | High-Throughput & FinOps Optimiz
Palermo, Argentina - 2:54 am local time
What I bring to your production systems:— Inference Fleet Optimization: Multi-GPU vLLM serving clusters, tensor parallelism, and model routing (AWQ quantization vs full-precision) to slash GPU spend by up to 38%.— Agent Governance & FinOps: Deterministic runtime enforcement, per-session spend caps, and circuit breakers to stop uncontrolled tool-call loops and token waste.— Production Memory Systems: Zero-dependency persistent memory runtimes using bbolt and vector indexes, reducing repeated-context token consumption by 90%.— High-Throughput Pipelines: Ingestion engines handling 10M+ records using async workers and vectorized batch processing.Core Stack: Go, Python, Rust, vLLM, Triton Inference Server, LangGraph, CrewAI, AutoGen, MCP Server/Client, Docker, Kubernetes, Prometheus, Grafana.Available for immediate, high-impact, fixed-scope contracts. Let's fix your scaling and cost bottlenecks this week.
Steps for completing your project
After purchasing the project, send requirements so Nick can start the project.
Delivery time starts when Nick receives requirements from you.
Nick works on your project following the steps below.
Revisions may occur after the delivery date.
Codebase & Architecture Audit
I review your current agent architecture, identify token overhead leaks, and map out framework integration bottlenecks.
Memory Layer Core Integration
Deployment of the embedded storage, hybrid vector retrieval pipeline, and context consolidation background workers.