You will get a production Medallion data pipeline
Project details
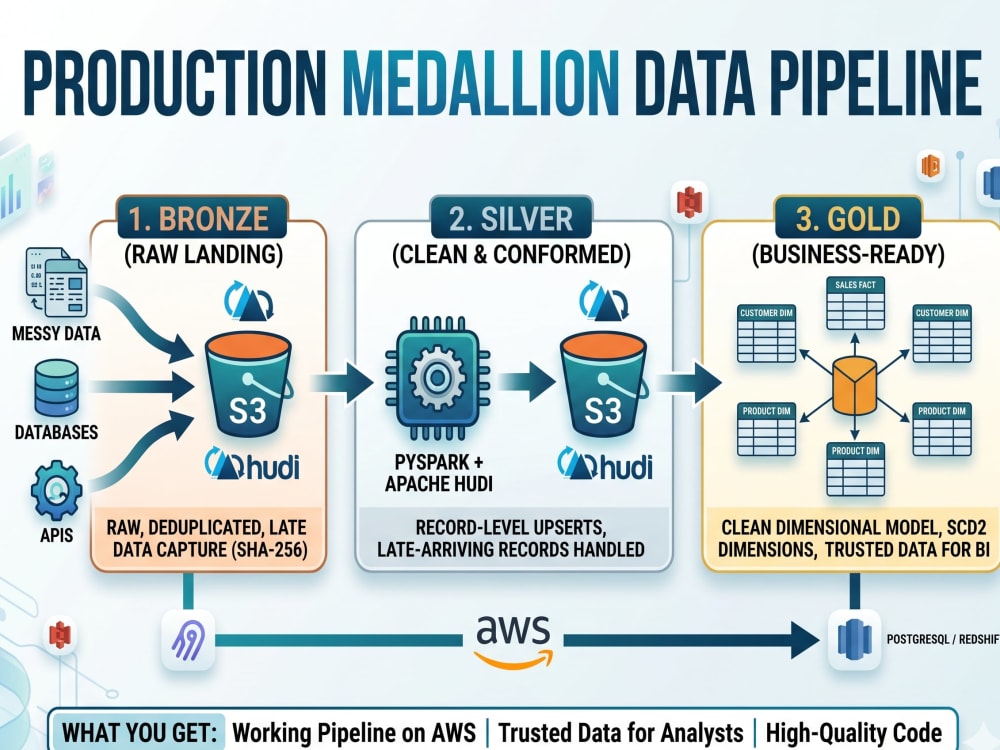
Your raw data is messy, duplicated, and arrives late. Reports built directly on it lie. Medallion architecture fixes this by separating raw landing (Bronze), cleaned conformed data (Silver), and business-ready star schemas (Gold) — so analysts query trusted data, not whatever happened to land last night.
I build the same Medallion stack I run in production today: Airbyte or custom ingestion into S3 Bronze, PySpark + Apache Hudi for Silver with record-level upserts, and a PostgreSQL or Redshift Gold layer modeled as a star schema with SCD2 dimensions.
I build the same Medallion stack I run in production today: Airbyte or custom ingestion into S3 Bronze, PySpark + Apache Hudi for Silver with record-level upserts, and a PostgreSQL or Redshift Gold layer modeled as a star schema with SCD2 dimensions.
Data Tool
PythonWhat's included $1,500
These options are included with the project scope.
$1,500
- Delivery Time 14 days
- Number of Revisions Unlimited
1 review
(1)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
MN
Muhammad Jamal N.
May 19, 2026
Python API Automation Framework — Pytest + Requests (Pet/REST API) — Showcase Project
Thanks Ammad for completing the project before time while maintaining quality work. Definitely will hire you in future. Goodluck
About Ammad
Data Engineer | PySpark, dbt, Airflow, BigQuery | AWS & GCP Pipelines
Lahore, Pakistan - 10:45 pm local time
Recent production work:
• Meta Ads → BigQuery/PostgreSQL pipeline (Airbyte → S3 → PySpark + Apache Hudi) with SCD2 dimensional modeling, SHA-256 deduplication, and late-arriving attribution handling.
• dbt + BigQuery + Looker Studio analytics on 99K+ orders — 7 staging models, 6 marts, 28 data-quality tests, 4-page dashboard.
• Real-time Kafka + PySpark streaming pipeline running 9 concurrent queries with 4 windowed aggregations into PostgreSQL.
• Full AWS data platform on Terraform + EKS + EMR-on-EKS + Airflow with CI/CD.
How I work: I document every architectural decision before I build — scope, schema, and tradeoffs written down first — so downstream teams know exactly what they're querying. You get async-friendly updates on US/EU hours and pipelines that don't silently break on schema drift or duplicate events.
Core stack: Python, PySpark, SQL, Apache Airflow, dbt, Apache Hudi, Apache Kafka, AWS (S3, Glue, EMR, EKS, Athena), GCP/BigQuery, PostgreSQL, ClickHouse, Snowflake, Docker, Terraform, Looker Studio. Focus: ETL/ELT pipelines, dimensional modeling, data warehousing, streaming, and marketing analytics.
If you're building a data pipeline or need messy data turned into something your team can trust, send me the brief — I reply within 24 hours.
Steps for completing your project
After purchasing the project, send requirements so Ammad can start the project.
Delivery time starts when Ammad receives requirements from you.
Ammad works on your project following the steps below.
Revisions may occur after the delivery date.
Discovery and scope doc
30–45 min call to confirm sources, business questions, and SLAs. Deliver a written scope doc with the proposed star schema and Bronze/Silver/Gold layout for sign-off.
Bronze ingestion layer
Set up S3 buckets, configure Airbyte or custom Python connectors, and implement idempotent ingestion with SHA-256 synthetic keys for deduplication,