You will get a production RAG pipeline and LLM app using Claude and Python
Project details
You will get a production-ready RAG pipeline that lets users ask natural language questions over your documents and get accurate, grounded AI responses.
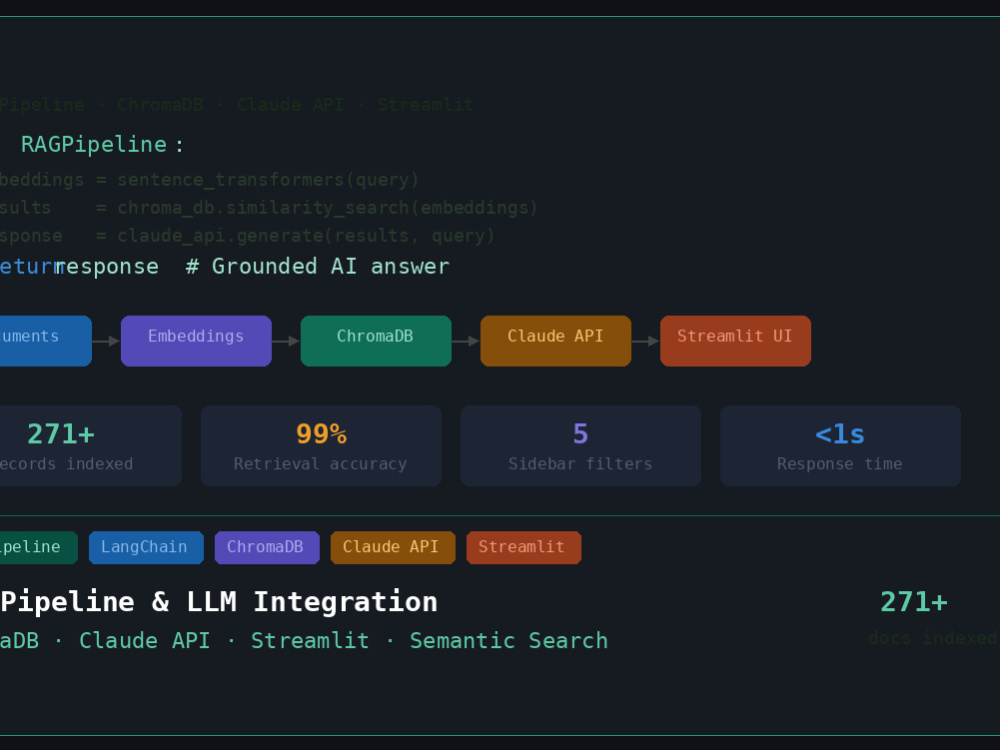
I have built RAG systems using LangChain, ChromaDB, Claude API, and Streamlit including a family office intelligence platform that indexes 271+ records and returns semantic search results in under 1 second.
What makes my service different:
• I build end-to-end systems not just scripts your RAG app will be deployment-ready from day one.
• Semantic search using sentence-transformers so results are contextually relevant, not just keyword matches.
• Sidebar filters, CSV export, and demo queries included
• Full documentation so your team can maintain it
Every delivery includes source code, requirements.txt, README with setup instructions, and a working demo.
I have built RAG systems using LangChain, ChromaDB, Claude API, and Streamlit including a family office intelligence platform that indexes 271+ records and returns semantic search results in under 1 second.
What makes my service different:
• I build end-to-end systems not just scripts your RAG app will be deployment-ready from day one.
• Semantic search using sentence-transformers so results are contextually relevant, not just keyword matches.
• Sidebar filters, CSV export, and demo queries included
• Full documentation so your team can maintain it
Every delivery includes source code, requirements.txt, README with setup instructions, and a working demo.
AI Development Type
Deep Learning, Knowledge Representation, Model TuningAI Tools
Keras, PyTorch, Sonnet, TensorFlowAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$80
|
Standard
$200
|
Advanced
$400
|
|---|---|---|---|
| Delivery Time | 3 days | 6 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Detailed Code Comments | - | ||
Knowledge Graph | - | - | - |
Model Documentation | - | ||
Ontology | - | - | - |
Source Code | |||
Taxonomy | - | - | - |
Optional add-ons
You can add these on the next page.
Additional Revision
+$20Frequently asked questions
About Malik Jamal
Data Scientist and ML Engineer - Churn, Fraud Detection, RAG
Rawalpindi, Pakistan - 4:04 am local time
What I build for clients:
✔ Churn & retention prediction models (95%+ accuracy)
✔ Fraud detection & anomaly detection systems
✔ RAG pipelines using LLMs (Claude API, ChromaDB, Streamlit)
✔ Customer segmentation & clustering (K-Means, DBSCAN)
✔ Power BI dashboards & automated data reports
✔ ML model deployment via Flask APIs on AWS
✔ Explainable AI using SHAP & LIME for business stakeholders
My edge: I don't just build models, I make sure business stakeholders understand the results. I use SHAP/LIME to explain every prediction in plain language, which is rare and highly valued by non-technical clients.
Tech stack:
Python · Scikit-learn · TensorFlow · PyTorch · XGBoost · Pandas
SQL · PostgreSQL · MySQL · Hadoop · AWS · Power BI · Streamlit
Flask · ChromaDB · LangChain · Claude API · Git · CI/CD
Currently, I have completed my MS in Data Science at Bahria University (2026).
If you need a reliable data scientist who delivers clean code, clear documentation, and on-time delivery - let's talk.
Steps for completing your project
After purchasing the project, send requirements so Malik Jamal can start the project.
Delivery time starts when Malik Jamal receives requirements from you.
Malik Jamal works on your project following the steps below.
Revisions may occur after the delivery date.
Data Ingestion and Embedding
Load your documents, chunk them correctly, generate embeddings using sentence-transformers and store in ChromaDB vector database.
Retrieval Pipeline and LLM Integration
Build semantic search retrieval, inject context into prompt template, and connect to your chosen LLM API for grounded response generation.