You will get a production-ready model optimized for edge devices with faster inference
Project details
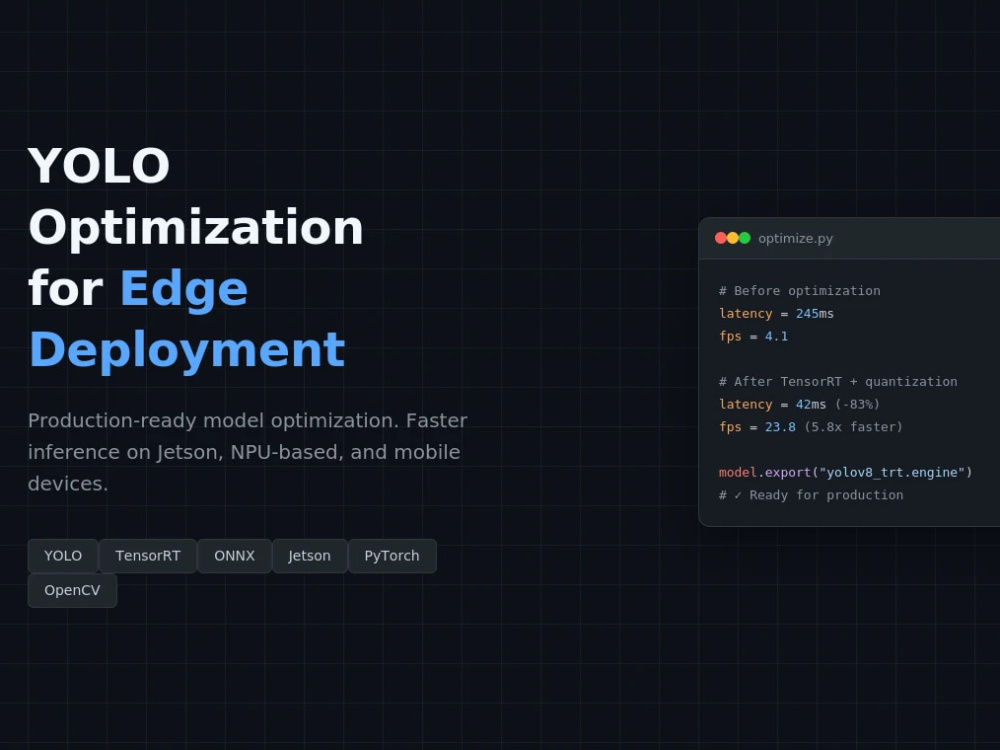
I optimize YOLO models for edge deployment, reducing latency by 40-60% while maintaining accuracy. With production experience across different retail deployments on Jetson and Qualcomm devices, I can also deliver TensorRT-optimized models ready for real-time inference.
What you get:
• Detailed analysis of your current model's bottlenecks
• Optimized model (TensorRT, ONNX, or INT8 quantized)
• Benchmark report with before/after metrics
• Clean, documented Python code for inference
I work with YOLOv5, v7, v8, v9, and v11. Target platforms: Jetson (Nano, Xavier, Orin), Qualcomm, desktop GPU, or cloud deployment.
What you get:
• Detailed analysis of your current model's bottlenecks
• Optimized model (TensorRT, ONNX, or INT8 quantized)
• Benchmark report with before/after metrics
• Clean, documented Python code for inference
I work with YOLOv5, v7, v8, v9, and v11. Target platforms: Jetson (Nano, Xavier, Orin), Qualcomm, desktop GPU, or cloud deployment.
AI Development Type
Deep Learning, Model TuningAI Tools
NVIDIA AI Platform, OpenCV, PyTorch, TensorFlowAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$75
|
Standard
$200
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 3 days | 7 days | 14 days |
Number of Revisions | 0 | 2 | 3 |
AI Model Integration | - | ||
Detailed Code Comments | - | ||
Knowledge Graph | - | ||
Model Documentation | - | ||
Ontology | - | ||
Source Code | - | ||
Taxonomy | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$25 - $100
Additional Revision
+$15Frequently asked questions
About Gabriel
Edge AI & Computer Vision Engineer | YOLO, TensorRT, Jetson
Recife, Brazil - 12:18 pm local time
As an ML Engineer specializing in Edge AI and Computer Vision, I've spent 2+ years building and deploying real-time inference systems for major retail clients, including surveillance, person detection, facial recognition (ReID), and ALPR pipelines.
What I bring to your project:
→ End-to-end CV pipeline development (data → training → optimization → deployment)
→ Edge deployment: NVIDIA Jetson, Qualcomm, Raspberry Pi
→ Model optimization: TensorRT, ONNX, quantization for real-time inference
→ Production MLOps: Triton Inference Server, Docker, AWS Lambda, CI/CD
→ YOLO specialist: trained and deployed across different retail locations
I also research radar-camera fusion for autonomous vehicles at UFPE, so I can implement state-of-the-art architectures when your project needs cutting-edge solutions.
Tech stack: Python, PyTorch, TensorFlow, OpenCV, TensorRT, ONNX, Triton, Docker, AWS, Deepstream
Based in Brazil (GMT-3), available for async collaboration with US/EU teams.
Let's discuss your CV challenge, I'll tell you honestly if I can help.
Steps for completing your project
After purchasing the project, send requirements so Gabriel can start the project.
Delivery time starts when Gabriel receives requirements from you.
Gabriel works on your project following the steps below.
Revisions may occur after the delivery date.
Receive model files and sample data from client
Analyze model architecture and profile bottlenecks