You will get a production-ready RAG pipeline for your enterprise data

Project details
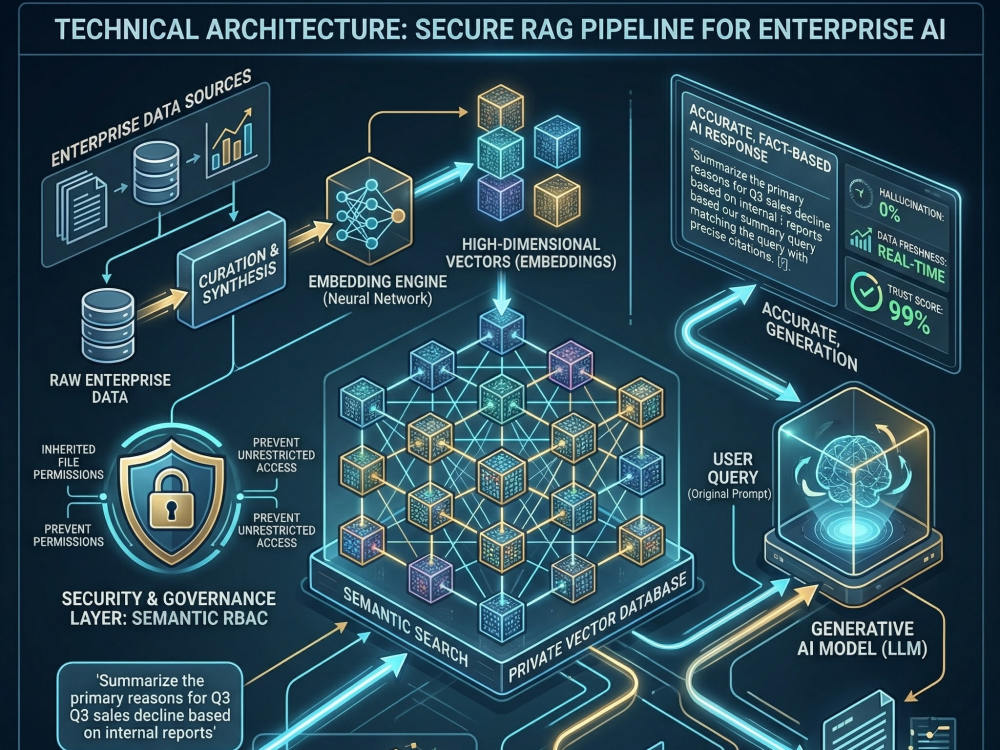
Most RAG implementations work in demos and fail in production. This engagement delivers a production-grade retrieval-augmented generation pipeline built around your specific data, query patterns, and accuracy requirements.
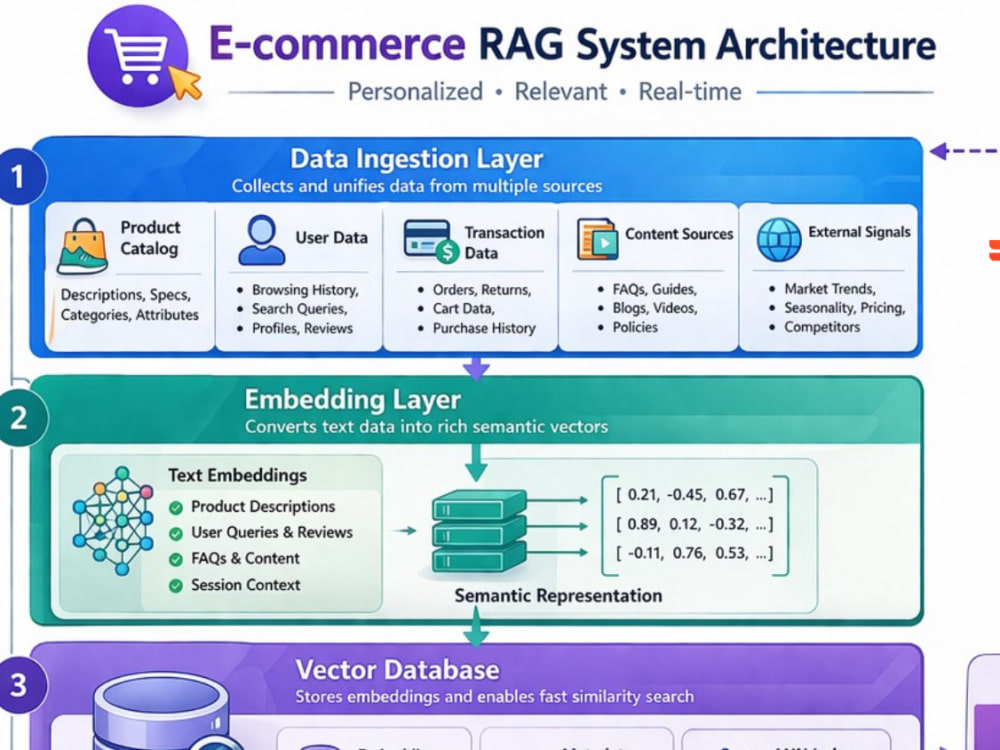
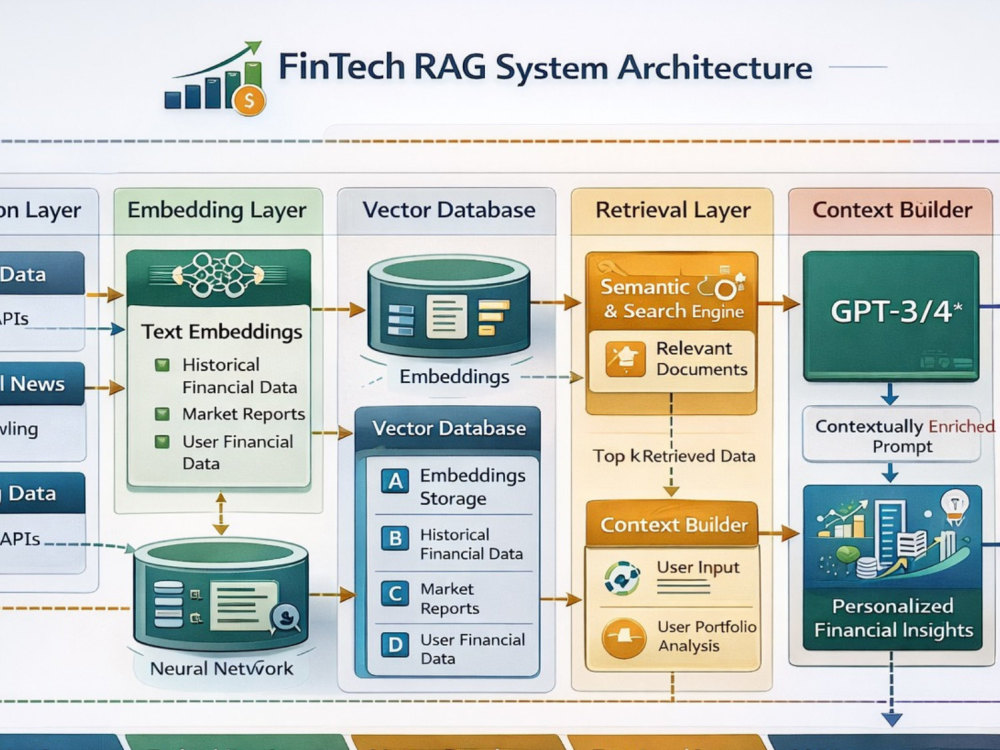
Includes chunking strategy selection and implementation, embedding pipeline, vector store setup (pgvector, Pinecone, or Weaviate), hybrid retrieval with reranking, hallucination mitigation, and a FastAPI serving layer with observability.
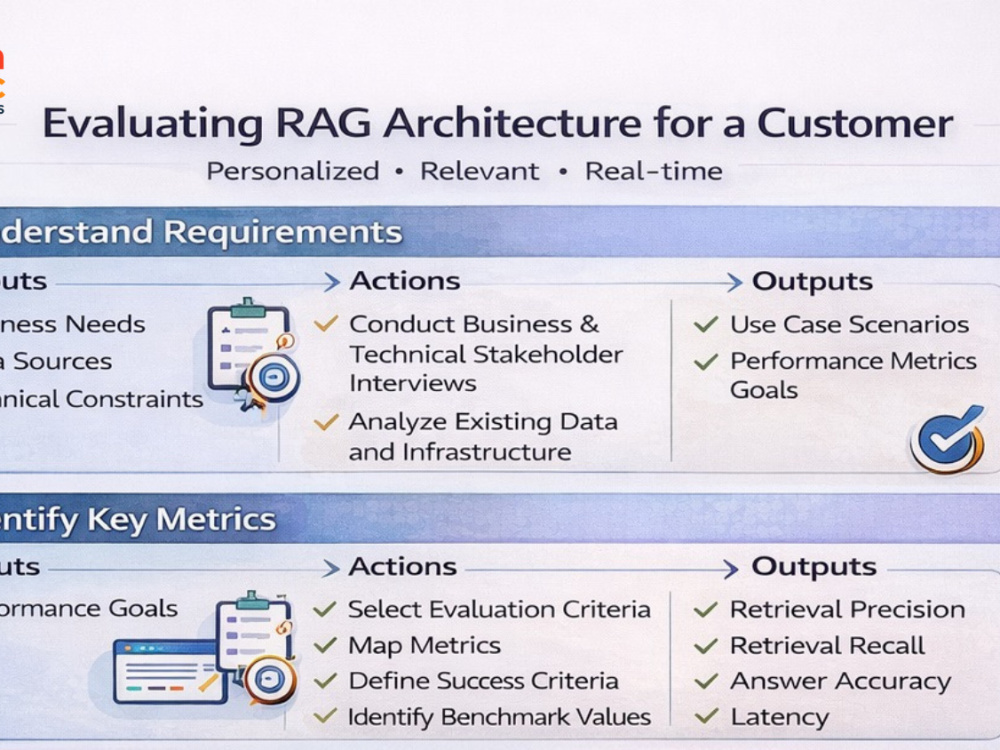
I also deliver an evaluation harness so you have objective metrics — faithfulness, context precision, and answer relevance — before the system goes live.
What's Included
• Chunking strategy design and implementation (fixed, recursive, or semantic)
• Embedding pipeline with the right model for your domain
• Vector store selection and config (pgvector, Pinecone, Weaviate)
• Hybrid retrieval combining dense vector search
• Cross-encoder reranking for precision-optimised results
• Hallucination mitigation and output filtering
• FastAPI serving layer with API key auth
• Evaluation harness measuring faithfulness, context precision, and ans relevance
• Docker Compose environment with Prometheus and Grafana observability
Includes chunking strategy selection and implementation, embedding pipeline, vector store setup (pgvector, Pinecone, or Weaviate), hybrid retrieval with reranking, hallucination mitigation, and a FastAPI serving layer with observability.
I also deliver an evaluation harness so you have objective metrics — faithfulness, context precision, and answer relevance — before the system goes live.
What's Included
• Chunking strategy design and implementation (fixed, recursive, or semantic)
• Embedding pipeline with the right model for your domain
• Vector store selection and config (pgvector, Pinecone, Weaviate)
• Hybrid retrieval combining dense vector search
• Cross-encoder reranking for precision-optimised results
• Hallucination mitigation and output filtering
• FastAPI serving layer with API key auth
• Evaluation harness measuring faithfulness, context precision, and ans relevance
• Docker Compose environment with Prometheus and Grafana observability
AI Algorithms
Feedforward Neural Network, Generative Adversarial Network, Large Language Model, Multimodal Large Language ModelAI Applications
AI Chatbot, AI Content Creation, AI Text-to-Image, AI Text-to-Speech, AI-Generated Code, Conversational AI, Image Analysis, Image Recognition, Image-to-Image Translation, Natural Language Understanding, Object Detection, Text RecognitionAI Development Language
PythonAI Tools
Azure OpenAI, Copy.ai, GitHub Copilot, Hugging Face, PyTorch, Replit, Streamlit, TensorFlowAI Models
ChatGPT, DALL-E, GPT-3, GPT-4, LLaMA, Midjourney AI, WhisperWhat's included
| Service Tiers |
Starter
$799
|
Standard
$1,499
|
Advanced
$2,999
|
|---|---|---|---|
| Delivery Time | 7 days | 14 days | 21 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | - | - | - |
Batch Normalization | - | - | - |
Database Integration | - | - | - |
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | - | - | - |
Model Monitoring | - | - | - |
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | - | - |
Setup File | - | - | - |
Source Code | - | - | - |
1 review
(1)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
SR
Satya R.
Jun 5, 2017
CI/CD with Jenkins
Sudarshan is highly experienced and he quickly grabbed my requirement and was very straight to the point. He has good subject expertise with a positive attitude.
About sudarshan
Enterprise AI Architect | GenAI Systems | Ex-AWS | Fractional CTO
Hyderabad, India - 4:21 pm local time
I am Sudarshan Angirash, an enterprise AI and solutions architect with 20 years of experience building production-grade systems across cloud, DevOps, and AI. I am the founder of TechTonic IT Solutions and the author of two technical books on multi-agent AI systems and Rust programming. Before going independent, I was a System Development Manager at Amazon Web Services, where I led a team of 35 engineers and built a multi-agent AI system that processed over 15,000 customer queries per day with 95% accuracy, reducing manual support effort by nearly half.
I do not just design systems on whiteboards. I build them, ship them, and hand them over production-ready.
In the last 12 months alone, I have delivered four production AI products as a solo founder. One of them went from zero to $3,200 in monthly recurring revenue with 1,200 active users within four months of launch. Another is an enterprise-grade, multi-tenant performance management SaaS with 20-plus third-party integrations, built and delivered in five months. A third went from concept to live product in two weeks. These are not case studies from a decade ago. They are proof of what I deliver right now.
WHAT I WORK ON
My engagements typically fall into three categories.
The first is architecture and strategy. If you are planning an AI initiative, evaluating your current stack, or trying to understand why your GenAI project is not performing, I will audit your architecture, identify every bottleneck and risk, and give you a prioritised, actionable roadmap. I have done this for teams at every stage, from early-stage startups to enterprise engineering divisions.
The second is fractional CTO and technical leadership. If you need senior technical judgment on an ongoing basis without the cost of a full-time hire, I work as a fractional CTO for companies that need architecture decisions made, vendor choices evaluated, teams guided, and technical roadmaps owned. I bring the depth of someone who has made these decisions at AWS scale and lived with the consequences.
The third is end-to-end build and delivery. If you need a production AI system designed and built, I handle the full scope. Multi-agent pipelines, RAG architectures, MLOps infrastructure, API layers, observability, security. I work directly alongside your engineering team or independently, and I deliver working software, not slide decks.
TECHNICAL DEPTH
On the AI side, I work with LangGraph, PyTorch, AWS Bedrock, SageMaker, LlamaIndex, and the full ecosystem of retrieval-augmented generation tooling. I have built hybrid retrieval pipelines combining dense vector search with BM25 sparse retrieval, cross-encoder reranking layers, vector store abstractions supporting pgvector, Pinecone, and Weaviate, and evaluation harnesses measuring faithfulness, context precision, and answer relevance. I have open-sourced a production RAG reference implementation on GitHub that demonstrates how each of these layers should be built and why.
On the infrastructure side, I work with AWS at depth across EKS, SageMaker, Bedrock, Glue, CloudWatch, and Lambda. I have designed and led migrations of ML workloads from monolithic deployments to containerised EKS-based pipelines, reducing model
deployment time from two weeks to two days. I work with Kubernetes, Docker, Terraform, Kafka, Prometheus, and Grafana as standard parts of any production deployment.
On the application side, I build with Python, FastAPI, Node.js, React, PostgreSQL, and Rust. I have delivered full-stack SaaS products, REST and event-driven APIs, multi-tenant data architectures with row-level security, and CI/CD pipelines with automated quality gates.
I am published on enterprise AI architecture topics on LinkedIn and have written two books available on Amazon. My GitHub profile hosts open-source reference implementations that demonstrate how I approach production problems. My personal site at angirash.in has a full account of my career and the systems I have built.
HOW I WORK
I communicate in plain language. I will tell you what I think, including when I think an approach is wrong or when a simpler solution exists. I do not pad engagements and I do not bill hours that are not producing value for you.
I work in focused engagements with clear scope and defined deliverables. For architecture reviews and strategy engagements, I typically deliver written findings and a prioritised roadmap within two weeks. For build engagements, I agree on milestones upfront and deliver against them.
I am based in Hyderabad, India and work with clients across the US, UK, Europe, and the Asia-Pacific region. I am available for calls across US Eastern, US Pacific, and UK time zones.
If you are building something serious with AI and you want someone who has done it at scale, let us talk.
Steps for completing your project
After purchasing the project, send requirements so sudarshan can start the project.
Delivery time starts when sudarshan receives requirements from you.
sudarshan works on your project following the steps below.
Revisions may occur after the delivery date.
Discovery call
A focused 30-minute conversation to understand your problem, assess whether I am the right person to help, and determine the best engagement type. I come prepared — I will have reviewed your website, product, and any context you share in advance.
Requirements & Scoping
Based on the discovery call, I draft a high-level BRD that captures the problem statement, business goals, success metrics, stakeholder map, and initial scope boundary. We then align on deliverables, timeline, and commercial terms before work begins.