You will get a professional PDF generated automatically from your data using Python


Project details
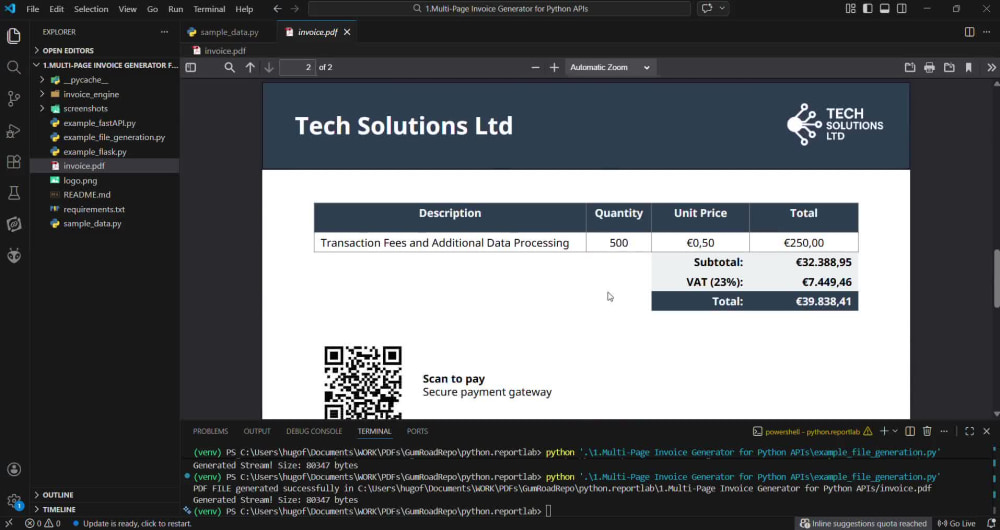
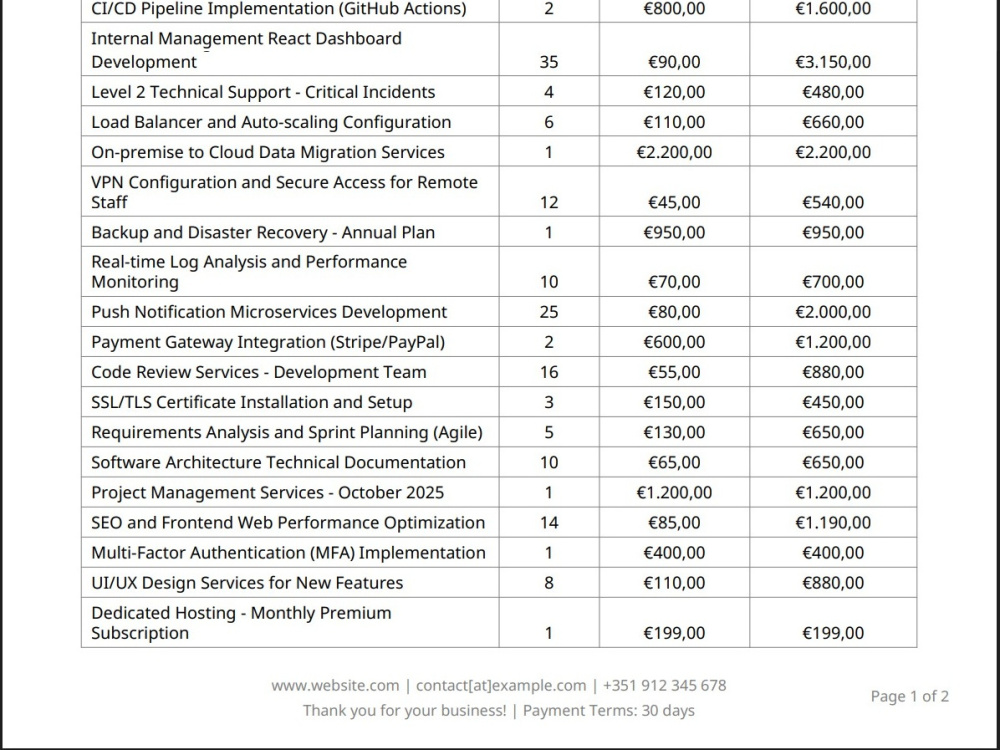
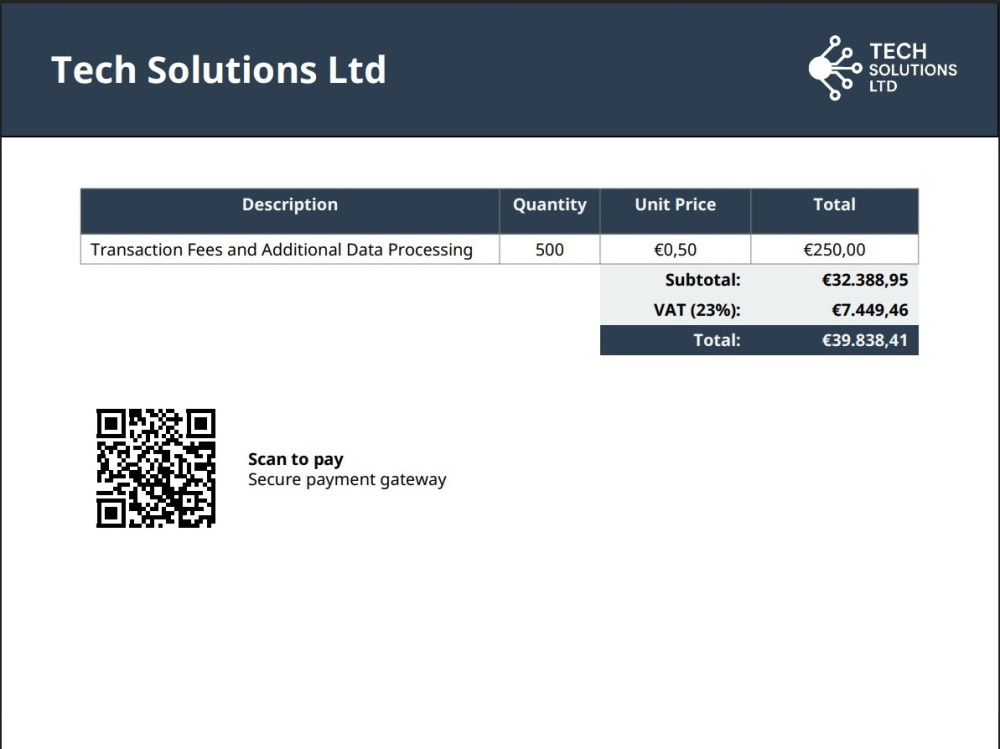
You will get a professional, multi-page PDF invoice generated automatically from your data using Python and ReportLab.
This is a code-based solution — not a Word template or HTML converter. The layout handles complex pagination, repeating headers, VAT calculations, QR codes, and branded designs natively in Python.
With 8+ years of Python development experience and 900+ students trained on Udemy in PDF automation, I deliver production-level results that integrate cleanly with APIs, Django backends, and ERP systems.
Ideal for SaaS platforms, freelancers, and businesses that need invoices generated programmatically — without depending on headless browsers or fragile HTML-to-PDF tools.
This is a code-based solution — not a Word template or HTML converter. The layout handles complex pagination, repeating headers, VAT calculations, QR codes, and branded designs natively in Python.
With 8+ years of Python development experience and 900+ students trained on Udemy in PDF automation, I deliver production-level results that integrate cleanly with APIs, Django backends, and ERP systems.
Ideal for SaaS platforms, freelancers, and businesses that need invoices generated programmatically — without depending on headless browsers or fragile HTML-to-PDF tools.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$30
|
Standard
$90
|
Advanced
$250
|
|---|---|---|---|
| Delivery Time | 2 days | 4 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Optional add-ons
You can add these on the next page.
Additional Revision
+$10Frequently asked questions
About Hugo
Python Automation | PDF Expert (ReportLab, PyMuPDF) | Data Extraction
Alcochete, Portugal - 5:04 am local time
My work focuses on tasks such as:
• Advanced Extraction: Parsing text, tables, and metadata from searchable or scanned PDFs using PyMuPDF (fitz), pdfplumber, and Camelot.
• Dynamic PDF Generation: Creating custom invoices, certificates, and reports using ReportLab.
• OCR & Image Processing: Converting non-searchable scans into structured data (JSON/CSV) with Tesseract or EasyOCR.
• High-Volume Automation: Processing thousands of files with robust error handling and logging to ensure zero data loss.
I have experience working with document processing, structured data extraction, and automation pipelines that save time and reduce human error.
Typical solutions I build include:
• PDF parsing and structured data extraction
• File renaming and organization workflows
• Report generation
• Custom automation scripts
Tech Stack: Python (Pandas, Regex), PyMuPDF, ReportLab, PDFPlumber, EasyOCR, Tesseract-OCR.
If you have a repetitive manual workflow, I can build a reliable, standalone Python solution that saves you hours of work every week.
Steps for completing your project
After purchasing the project, send requirements so Hugo can start the project.
Delivery time starts when Hugo receives requirements from you.
Hugo works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements Review
I review your data structure and branding requirements to plan the PDF layout.
Template Development
I build the PDF template in ReportLab, handling pagination, tables, and layout automatically.