You will get a python script in jupyter notebook with multiple machine learning model


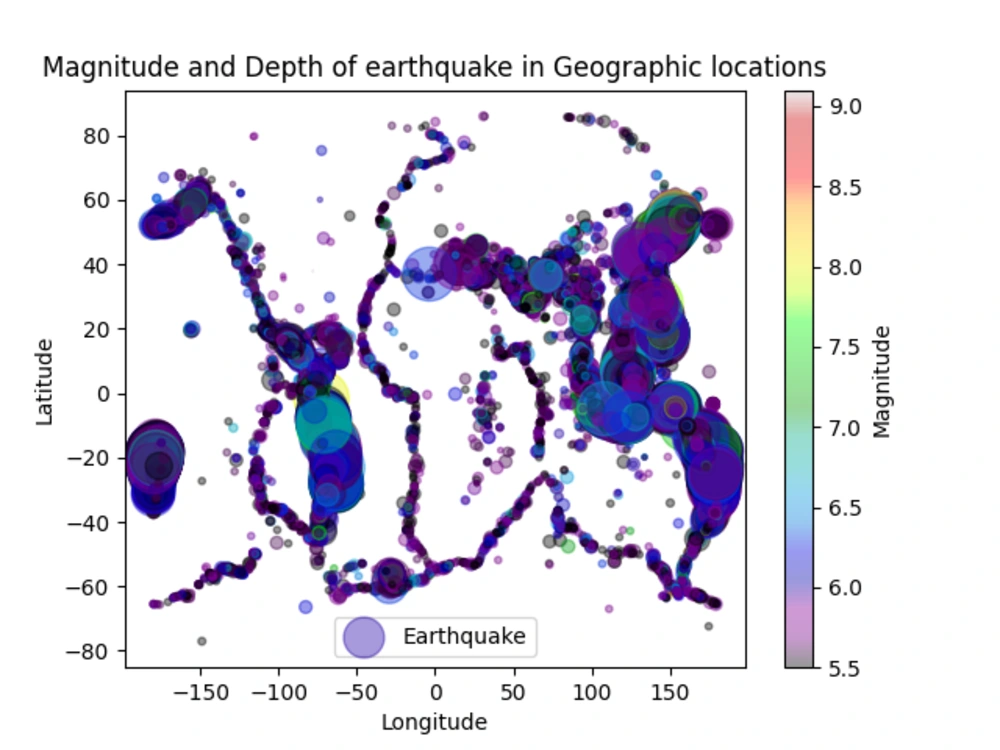
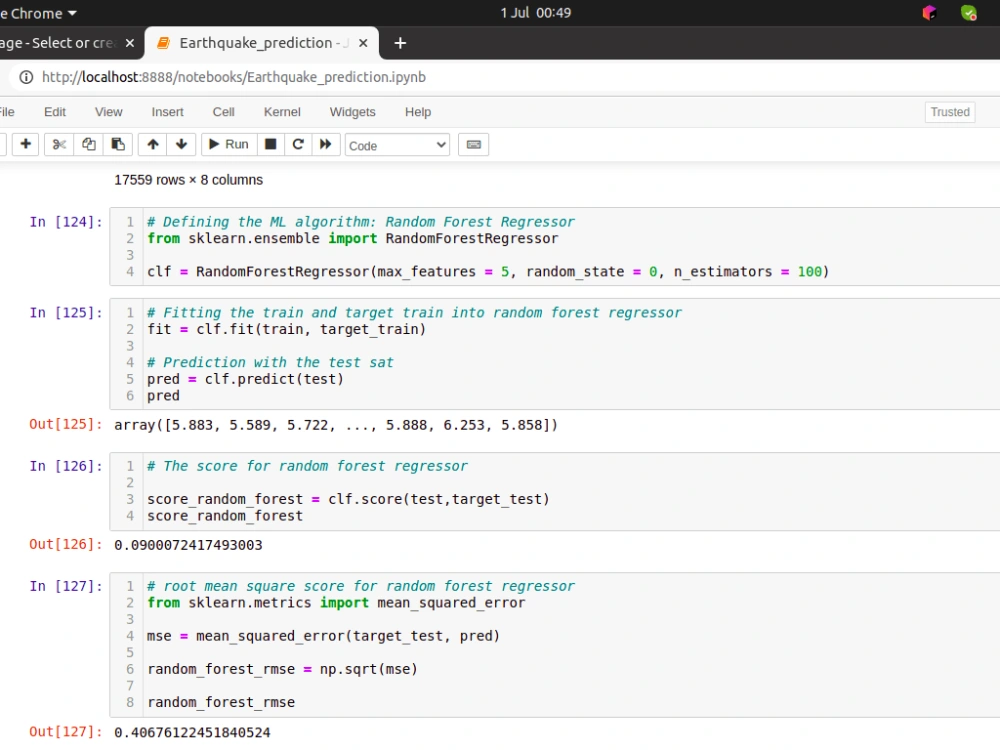
Project details
You will get visualized predicted data generated by multiple machine learning models and deep learning models such as random forest, decision tree, support vector machine, logistic regression, k-means clustering, etc. Before training the data, I will perform Exploratory Data Analysis (EDA) through the correlation matrix, boxplot, scatterplot, histogram, pie chart, etc. You will get the whole python script in jupyter notebook. I will use Scikit-learn to perform general machine learning applications. In the case data arises a complex problem related to data-set connection, I will use python Pandas, NumPy to resolve it. After all, I wil provide the model validation as the cross-value score, mean-squared error, Cohen's kappa score by the Confusion matrix.
What's included
| Service Tiers |
Starter
$25
|
Standard
$40
|
Advanced
$50
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 3 | 5 | Unlimited |
Number of Model Variations | 2 | 4 | 4 |
Number of Scenarios | 1 | 1 | 2 |
Number of Graphs/Charts | 4 | 6 | 8 |
Model Validation/Testing | |||
Model Documentation | - | - | |
Data Source Connectivity | |||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$5
Additional Graph/Chart
+$5About Nazmus
Data Science and Analytics
Chattogram, Bangladesh - 9:48 am local time
Data wrangling: I can group the data by selecting columns with specific name or value from data spread-shit by using pandas, MySQL.
Statistical Programming: I can make general plot, histogram, bar-plot, Probability distribution curve through numpy, scipy, matplotlib, seaborn.
Machine learning: I use Forest Random Classification, Support Vector Machine Algorithm to make the class of the data out of the Test and Train data-set by using Scikit learn.
Data-presentation and Image Data Processing: I use matplotlib, pyglet to present the data and I use matplotlib and Pillow to present/edit by labeling Image.
Graphical toolkit: I use tkinter to make a User interface to create flexibility for opening, manipulating and presenting data (e.g., a calculator can be provided by tkinter in which, user can open a database, make a histogram, save the histogram through the action of selecting/clicking some button)
Problem Solving Strategy: I have a deep understanding about the underlying Higher Calculus of the Machine learning algorithm and Statistical analysis and those were accomplished by the Academic Study/courses. I can identify the appropriate solution of the problem by using mathematical and programming skill in a much faster way.
Experience: I used python programming skill on a research of the Micro-climate Simulation to open, process and present the data through the pandas, matplotlib and seaborn.
Steps for completing your project
After purchasing the project, send requirements so Nazmus can start the project.
Delivery time starts when Nazmus receives requirements from you.
Nazmus works on your project following the steps below.
Revisions may occur after the delivery date.
Data-base connection by NumPy, Pandas
In some situations, feature data and label/target data may be two different data set. In that case, data value matching, data concatenation, data merging may be needed to perform.
Exploratory Data Analysis (EDA)
EDA is needed to check whether we have over-correlated data or under-correlated data, outliers. To make the EDA model, I will perform correlation, scatterplot, box-plot, and, if necessary, barplot (vertical or horizontal) pie chart on the data.