You will get a RAG pipeline and Q&A API over your documents or data
Project details
You will get a working RAG pipeline that lets users ask questions over your documents and get accurate, cited answers — deployed as an API or runnable script.
RAG (Retrieval-Augmented Generation) is the standard approach for building Q&A systems over private data: PDFs, internal docs, databases, web content. Getting it right requires more than wiring LangChain — chunking strategy, embedding choice, retrieval tuning, and prompt design all matter.
I've built RAG in production as part of EasyOref, an open-source AI agent that extracts and enriches data from live Telegram channels using embeddings and LLM retrieval.
What you get:
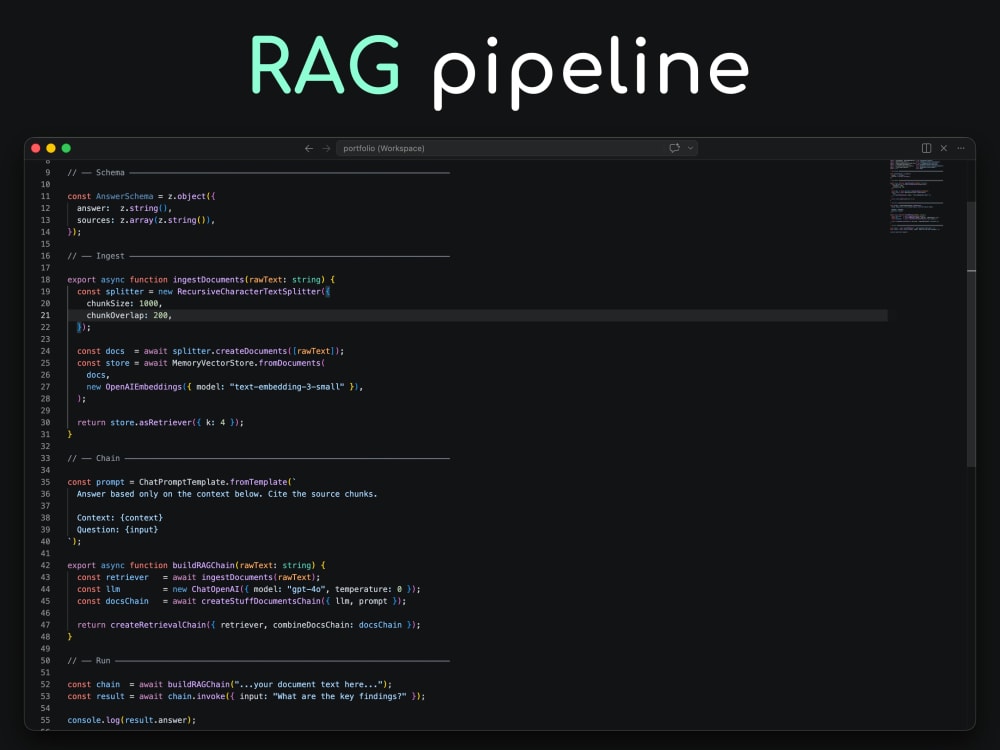
– Document ingestion pipeline (PDF, text, URLs, or DB)
– Vector store with tuned chunk size and overlap
– Retrieval chain with source citations
– REST API endpoint (FastAPI or Express) or CLI script
– Evaluation of retrieval quality
– README with architecture diagram
TypeScript or Python, your choice.
RAG (Retrieval-Augmented Generation) is the standard approach for building Q&A systems over private data: PDFs, internal docs, databases, web content. Getting it right requires more than wiring LangChain — chunking strategy, embedding choice, retrieval tuning, and prompt design all matter.
I've built RAG in production as part of EasyOref, an open-source AI agent that extracts and enriches data from live Telegram channels using embeddings and LLM retrieval.
What you get:
– Document ingestion pipeline (PDF, text, URLs, or DB)
– Vector store with tuned chunk size and overlap
– Retrieval chain with source citations
– REST API endpoint (FastAPI or Express) or CLI script
– Evaluation of retrieval quality
– README with architecture diagram
TypeScript or Python, your choice.
AI Algorithms
Large Language ModelAI Applications
Conversational AI, Natural Language UnderstandingAI Development Language
PythonAI Tools
Hugging FaceAI Models
ChatGPT, GPT-4What's included
| Service Tiers |
Starter
$40
|
Standard
$100
|
Advanced
$200
|
|---|---|---|---|
| Delivery Time | 5 days | 7 days | 14 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | |||
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | - | - | - |
Model Monitoring | - | - | - |
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | - | - |
Setup File | - | - | - |
Source Code | - | - | - |
About Mikhail
Agentic AI Engineer | MCP | LangGraph | LLM Infrastructure
Tel Aviv, Israel - 1:30 am local time
10+ years in production engineering. Led a platform team from 1 to 13 engineers. Shipped products to 5M+ users while keeping 99.5–100% crash-free rate in production.
My flagship project is CyberMem — a self-hosted MCP memory platform I designed and shipped end-to-end, used by Claude, GPT, Cursor, Gemini, and Perplexity. It runs on Docker, Kubernetes, and Raspberry Pi with Prometheus/Grafana observability, Traefik zero-trust auth, automated versioned releases via GitHub Actions, and Vitest test suite. 550+ commits, 25 versioned releases. Live at cybermem.dev.
I also built EasyOref: a LangGraph-based multi-step alert agent with MCP tool use, BullMQ queues, RAG enrichment, and Telegram delivery — running live in production.
What I work on:
- MCP server development (memory, API bridges, file gateways, custom tools) — Docker/K8s deployed, schema-driven, with auth, observability, and docs
- LangGraph / LangChain workflows — stateful agents with tool use, conditional branching, human-in-the-loop, rollback
- RAG pipelines — document ingestion, embeddings, vector store, retrieval tuning, clean Q&A API
- MCP client setup — Claude Desktop, Cursor, Windsurf, Perplexity — wired correctly with working auth
- Architecture reviews — for teams building agent systems before committing to a design
Positioning: AI Infra Engineer who ships production systems, not demos.
Stack: TypeScript/Node.js, Python, LangGraph, LangChain, FastMCP, Docker, Kubernetes, Redis, BullMQ, Prometheus, Vitest, GitHub Actions.
Send me a short message with your use case, and I'll tell you the fastest way to ship it.
Portfolio: mikhailkogan.dev
Steps for completing your project
After purchasing the project, send requirements so Mikhail can start the project.
Delivery time starts when Mikhail receives requirements from you.
Mikhail works on your project following the steps below.
Revisions may occur after the delivery date.
Ingest & index documents
Chunk, embed and store your documents in a vector store
Build retrieval chain
Wire retriever to LLM, tune prompts, add source citations