You will get a real‐time fraud detection pipeline with Python & ML
Project details
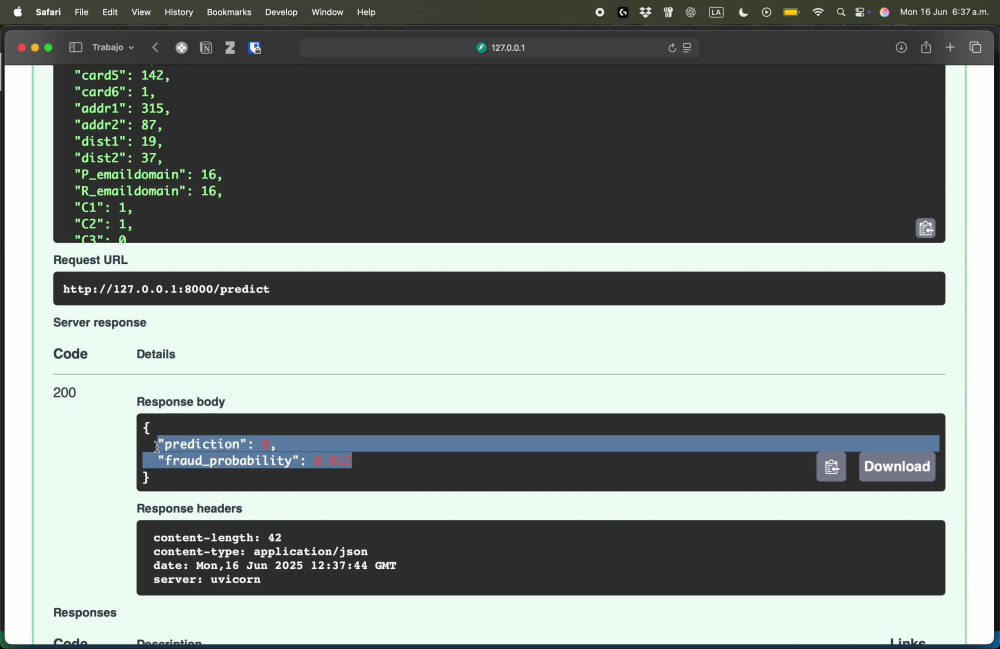
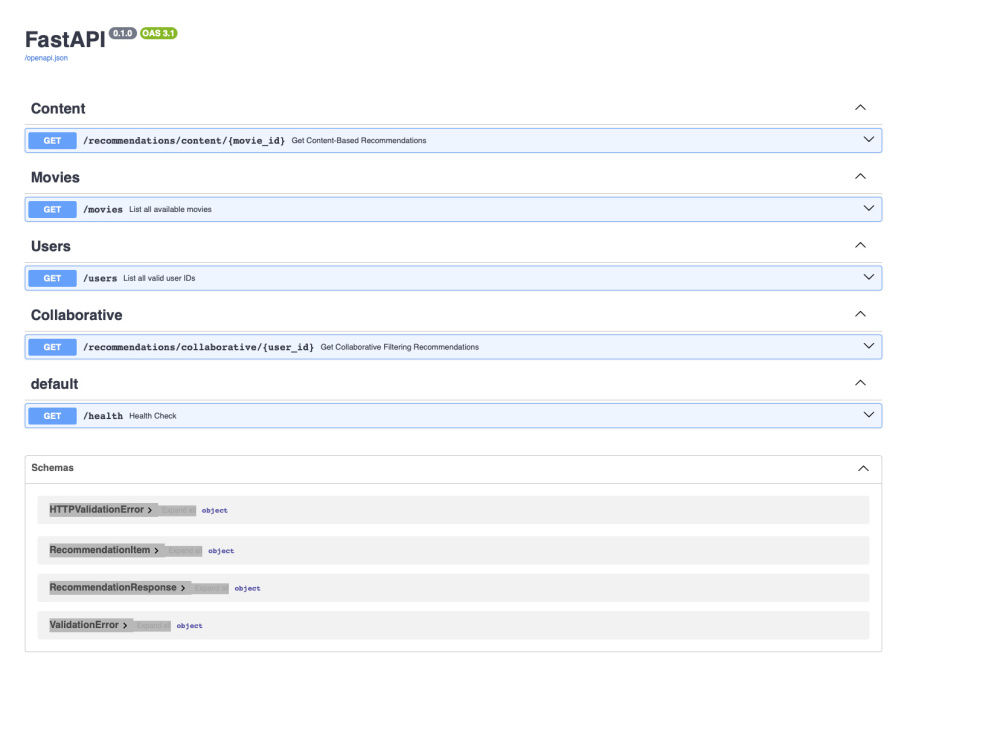
You will get a complete end-to-end fraud detection pipeline built in Python, ready to plug into your production environment. I’ll work closely with you to ingest your transaction data, engineer high-value features (velocity checks, statistical and behavioral signals), train and validate machine-learning models (e.g. XGBoost, Isolation Forest or deep learning approaches), and wrap everything into a clean, documented Python package or API for real-time scoring. With my PhD in Physics and production experience building ML pipelines, I care deeply about code quality, reproducibility (MLflow), and clear, actionable insights.
Machine Learning Tools
MLflow, NumPy, pandas, Python Scikit-Learn, PyTorch, R, scikit-learn, SciPy, SQL, Tableau, TensorFlow, XGBoostWhat's included
| Service Tiers |
Starter
$250
|
Standard
$450
|
Advanced
$750
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 2 | 3 |
Number of Scenarios | 1 | 3 | 5 |
Number of Graphs/Charts | 1 | 3 | 5 |
Model Validation/Testing | |||
Model Documentation | - | - | |
Data Source Connectivity | - | ||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$50 - $150
Additional Revision
+$30
Additional Model Variation
(+ 2 Days)
+$40
Additional Scenario
(+ 2 Days)
+$40
Additional Graph/Chart
(+ 1 Day)
+$25
Model Documentation
(+ 1 Day)
+$50
Data Source Connectivity
(+ 1 Day)
+$50Frequently asked questions
About Manuel Alejandro
Data Scientist | ML Engineer | Recommender Systems | NLP | MLOps
Mexico City, Mexico - 6:07 pm local time
I specialize in building end-to-end ML systems for real-world applications such as fraud detection, personalized recommendations, time series forecasting, and text classification.
My projects are designed for production, featuring modular code, API deployment with FastAPI, Docker containerization, automated pipelines, and clear documentation.
I work with Python, Scikit-learn, XGBoost, FastAPI, Streamlit, SQL (PostgreSQL), and also use R for data exploration.
Whether you need a custom ML model, an automated ETL pipeline, or a visual dashboard for your data, I can deliver clean, scalable solutions.
Steps for completing your project
After purchasing the project, send requirements so Manuel Alejandro can start the project.
Delivery time starts when Manuel Alejandro receives requirements from you.
Manuel Alejandro works on your project following the steps below.
Revisions may occur after the delivery date.
Kickoff & data gathering
Align on deliverables, performance targets (precision, recall, latency) and get your sample transaction & label data.
Exploratory data analysis & feature design
Profile raw data, uncover fraud patterns, build rules & derived features (amount‐per‐time, geolocation drift, device fingerprinting).