You will get a scalable data ingestion pipeline
Project details
I build production-ready data ingestion and web extraction systems designed for reliability and scalability.
With a background in high-throughput distributed systems processing millions of records per day, I design solutions that handle real-world constraints such as rate limits, anti-bot protections, structured storage, and cloud deployment.
Whether you need a proof-of-concept scraper or a fully automated data pipeline with scheduling, monitoring, and storage integration, I focus on clean architecture, fault tolerance, and performance optimization.
You receive a maintainable, well-structured solution built using professional engineering practices, including testing, documentation, and scalable design principles.
If you're looking for a system that works reliably in production, you're in the right place.
With a background in high-throughput distributed systems processing millions of records per day, I design solutions that handle real-world constraints such as rate limits, anti-bot protections, structured storage, and cloud deployment.
Whether you need a proof-of-concept scraper or a fully automated data pipeline with scheduling, monitoring, and storage integration, I focus on clean architecture, fault tolerance, and performance optimization.
You receive a maintainable, well-structured solution built using professional engineering practices, including testing, documentation, and scalable design principles.
If you're looking for a system that works reliably in production, you're in the right place.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$350
|
Standard
$1,300
|
Advanced
$3,500
|
|---|---|---|---|
| Delivery Time | 5 days | 10 days | 21 days |
Number of Pages Mined/Scraped | 5000 | 50000 | 500000 |
Number of Sources Mined/Scraped | 1 | 3 | 5 |
Number of Revisions | 1 | 2 | 3 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$200 - $800
Additional Page Mined/Scraped
(+ 1 Day)
+$100
Additional Source Mined/Scraped
(+ 3 Days)
+$250
Automated Scheduling & Monitoring
(+ 3 Days)
+$350
Advanced Anti-Bot Handling
(+ 4 Days)
+$350
Cloud Deployment Setup
(+ 3 Days)
+$350About Tom
Backend & Data Engineer | Scalable High-Performance Data Acquisition
Veliko Turnovo, Bulgaria - 8:42 pm local time
I transformed a fully manual, single-person scraping workflow into a 24/7, horizontally scalable, containerized data acquisition platform processing over 1.7M+ records per day (630M+ per year). What was once limited to ~500 items/day is now a fully automated distributed system powering core company operations.
My expertise sits at the intersection of backend engineering and data engineering:
- Architecting distributed scraping and crawling systems with sophisticated anti-bot bypass techniques (Akamai, DataDome, Cloudflare, Kasada)
- Reverse-engineering front-end/back-end communication to extract data directly from hidden API endpoints
- Designing database-driven job queues and self-serve configuration systems
- Building high-throughput, concurrent pipelines using Python, PySpark, SQL, and Azure
- Developing containerized infrastructure with Docker and production-grade CI/CD
- Engineering idempotent, fault-tolerant ingestion pipelines with deterministic hashing and deduplication
I specialize in systems that must handle:
- Large-scale parallelism
- Performance constraints
- Reliability requirements
- Real-world complexity and evolving anti-automation defenses
Beyond implementation, I take ownership of delivery end-to-end, from requirement breakdown and architectural design to testing, code reviews, CI/CD integration, and production reliability. I translate business needs into scalable technical systems that continue operating long after deployment.
If you're building data-intensive platforms, distributed processing systems, or high-performance backend infrastructure, I bring both architectural vision and hands-on execution at scale.
Steps for completing your project
After purchasing the project, send requirements so Tom can start the project.
Delivery time starts when Tom receives requirements from you.
Tom works on your project following the steps below.
Revisions may occur after the delivery date.
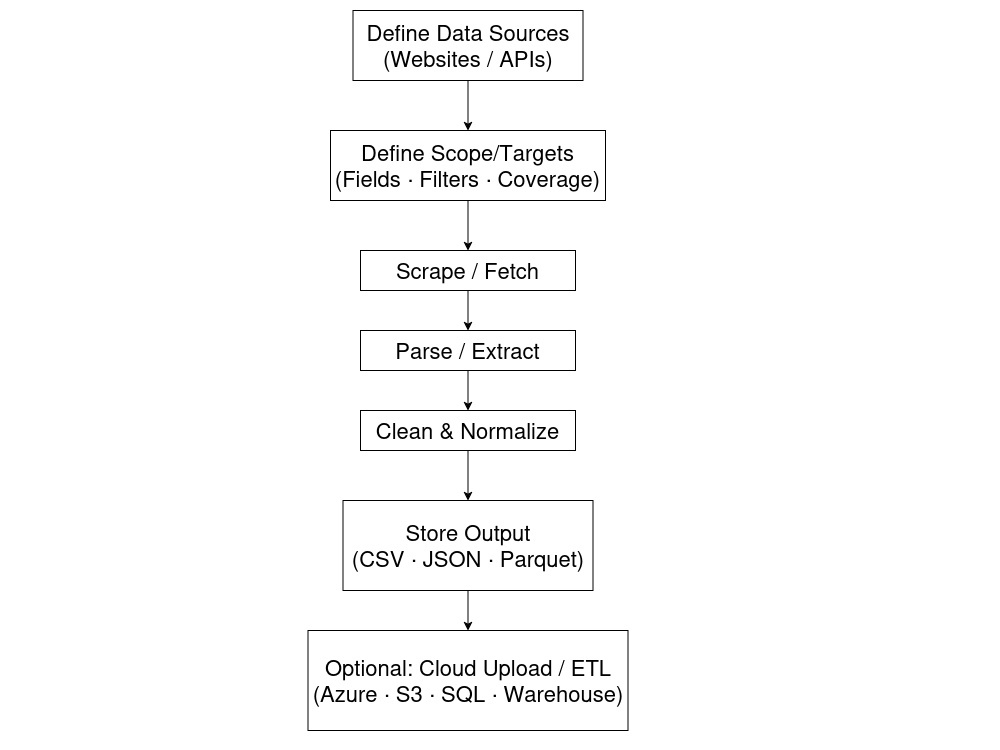
Requirement Analysis & Architecture Design
Review client requirements, analyze target sources, and design a scalable extraction and processing architecture.
Development & Integration
Implement scraping logic, data validation, processing workflows, and storage integration based on agreed scope.