You will get Actionable Insights and Clean Data from your Web Sources or Dataset.
Project details
Stop struggling with messy Excel files or inaccessible web data. I provide a complete, code-first data solution that transforms raw information into decision-ready assets.
What Sets This Project Apart? Unlike freelancers who manually edit cells, I build robust Python pipelines. This ensures your data is not just "visually" clean, but statistically valid and reproducible.
• Scientific Integrity: With a strong statistical background, I don’t just randomly delete missing values. I use statistical imputation methods to preserve the integrity of your dataset.
• Code-First Precision: I utilize advanced Python libraries (Pandas, NumPy, Selenium) to scrape and clean data. This eliminates human error and handles large datasets effortlessly.
• Beyond Cleaning: I offer Feature Engineering. I don't just hand you the data; I create new powerful variables from it (e.g., deriving "Session Duration" from raw timestamps) to deepen your analysis.
My "Zero to Hero" Pipeline:
* Scrape: Extract structured data from any website (even with pagination).
• Clean: Handle outliers, fix types, and standardize formats.
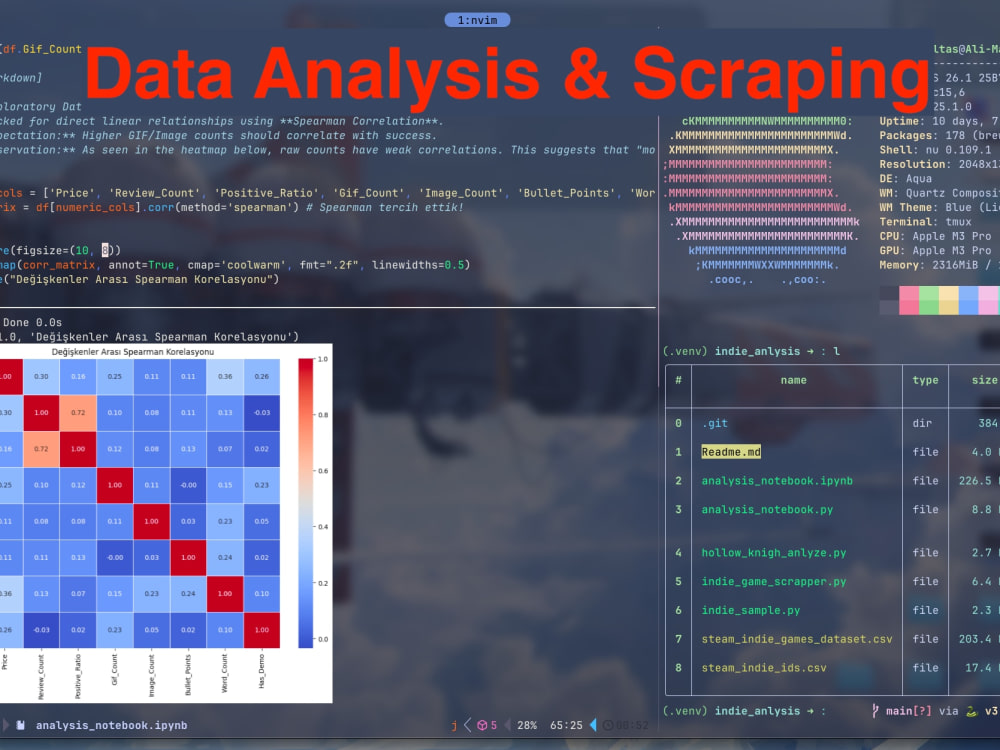
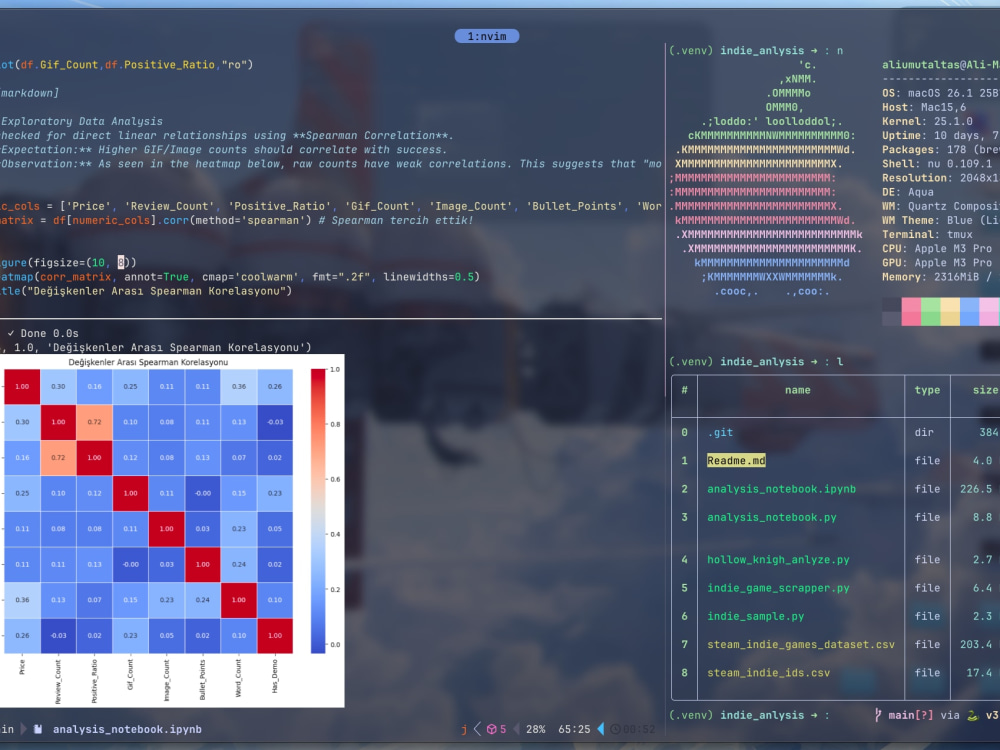
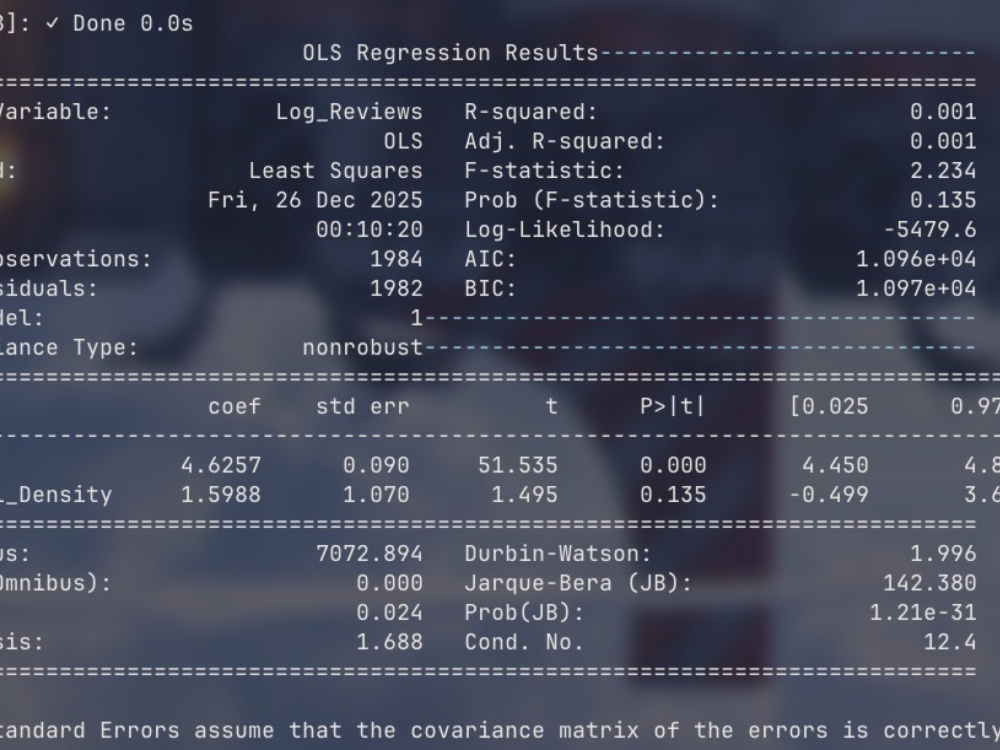
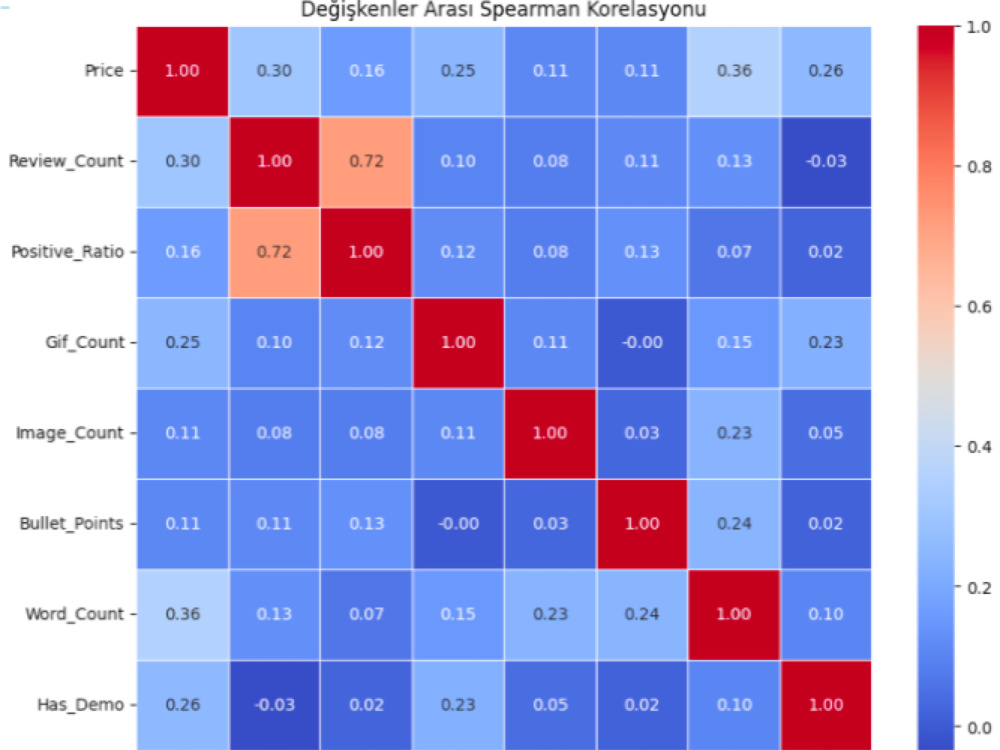
• Analyze: Visualize hidden correlations with professional charts.
What Sets This Project Apart? Unlike freelancers who manually edit cells, I build robust Python pipelines. This ensures your data is not just "visually" clean, but statistically valid and reproducible.
• Scientific Integrity: With a strong statistical background, I don’t just randomly delete missing values. I use statistical imputation methods to preserve the integrity of your dataset.
• Code-First Precision: I utilize advanced Python libraries (Pandas, NumPy, Selenium) to scrape and clean data. This eliminates human error and handles large datasets effortlessly.
• Beyond Cleaning: I offer Feature Engineering. I don't just hand you the data; I create new powerful variables from it (e.g., deriving "Session Duration" from raw timestamps) to deepen your analysis.
My "Zero to Hero" Pipeline:
* Scrape: Extract structured data from any website (even with pagination).
• Clean: Handle outliers, fix types, and standardize formats.
• Analyze: Visualize hidden correlations with professional charts.
Data Tool
Beautiful SoupWhat's included
| Service Tiers |
Starter
$25
|
Standard
$70
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 3 days | 5 days |
Number of Pages Mined/Scraped | 1 | 5 | 8 |
Number of Sources Mined/Scraped | 1 | 2 | 2 |
Number of Revisions | 1 | 2 | 4 |
Optional add-ons
You can add these on the next page.
Additional Page Mined/Scraped
(+ 1 Day)
+$10
Additional Source Mined/Scraped
(+ 1 Day)
+$10
Scraping for Standart Pack
(+ 1 Day)
+$30About Umut
Data Scientist | Predictive Modeling (XGBoost) & Financial Risk Analys
Ankara, Turkey - 1:14 am local time
With a strong academic background in Statistics and a workflow optimized for speed (Python/Neovim), I help businesses and researchers turn raw data into actionable intelligence. My focus is on FinTech, Credit Risk Modeling, and Automated Data Pipelines.
Here is how I can help you:
📊 Machine Learning & Financial Analytics I specialize in building robust models using advanced ensemble methods like XGBoost and LightGBM.
- Case Study: Developed a Credit Risk Analysis model to predict loan defaults, helping financial institutions minimize bad debt and optimize lending strategies.
- Experience: Competed in Datathons building regressor models for complex datasets.
🕷️ Web Scraping & Data Engineering Need data that doesn't exist yet? I build custom scrapers to extract market data, competitor pricing, or leads from the web.
- Tools: Python (Selenium, BeautifulSoup), Bash Scripting.
- Capability: I handle anti-bot measures and deliver clean, structured datasets (CSV, JSON, SQL) ready for analysis.
🎓 Statistical Analysis (Academic & Research) I provide rigorous statistical consulting for academic research, ensuring your methodology is sound and your results are accurate.
- Tools: SPSS, R, Python (Pandas/SciPy).
- Services: Hypothesis Testing, ANOVA, Regression Analysis, and Data Visualization.
🚀 Why Work With Me?
- Technical Speed: As a power user of Neovim and terminal-based workflows, I write and debug code significantly faster than the average developer.
- Statistical Rigor: I don't just "fit" models; I understand the mathematical theory behind them, ensuring your results are statistically significant, not just lucky guesses.
Ready to upgrade your data strategy? Click "Invite to Job" and let's discuss how we can execute your project.
Steps for completing your project
After purchasing the project, send requirements so Umut can start the project.
Delivery time starts when Umut receives requirements from you.
Umut works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Review
I review your data source (or URL) and instructions to ensure I have everything needed to start the pipeline.
Data Processing & Execution
Depending on your package, I either build the scraping bot to extract data OR start cleaning your raw dataset using Python (Pandas).