You will get AI Cost Optimization | Cut LLM API & Cloud Costs 40–70% in 14 Days

Project details
You're not overpaying for AI because you chose the wrong model. You're overpaying because nobody designed a cost strategy into the architecture.
I fix that - and I do it fast.
I run a focused AI Cost Optimization engagement: audit your current LLM usage, identify exactly where the waste is, then redesign the routing architecture to eliminate it.
What I deliver:
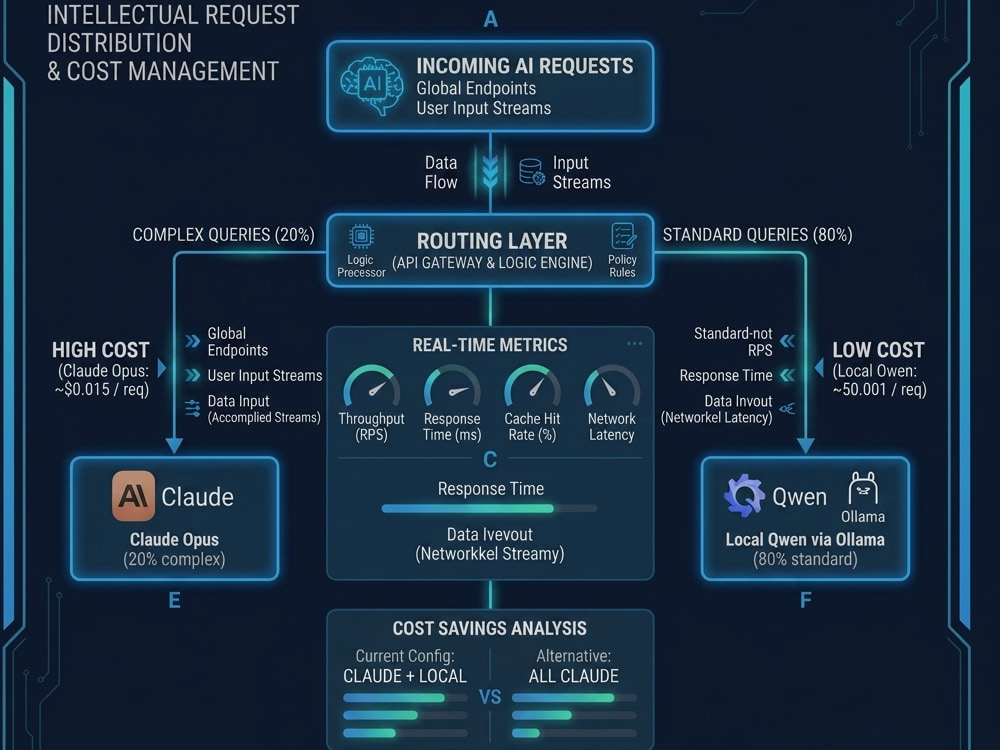
→ Full API cost audit - per-endpoint, per-feature breakdown
→ Hybrid LLM routing design: paid APIs only where they're irreplaceable
→ Local model setup (Ollama + Qwen/Mistral) for high-volume standard tasks
→ Prompt caching implementation for repeated system prompts (~85% input cost reduction)
→ Context compression and batching strategies
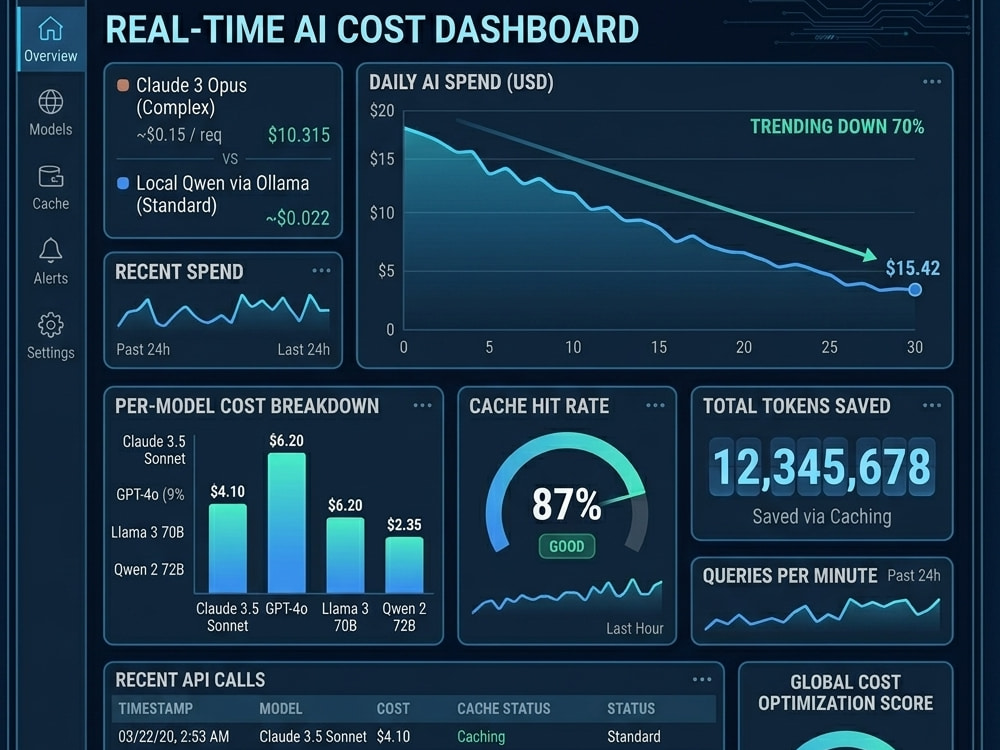
→ Real-time cost monitoring dashboard
Typical outcome: 40-70% reduction in monthly AI spend. In production systems I've achieved up to 90% reduction using hybrid local + cloud architecture.
This is architecture work - not prompt tweaking.
Stack: Claude API · OpenAI · Ollama · Qwen · Mistral · Semantic Kernel · FastAPI · .NET Core · Python
Proof: HiveGPT Inc. USA, Social27 Seattle - production AI systems at enterprise scale.
I fix that - and I do it fast.
I run a focused AI Cost Optimization engagement: audit your current LLM usage, identify exactly where the waste is, then redesign the routing architecture to eliminate it.
What I deliver:
→ Full API cost audit - per-endpoint, per-feature breakdown
→ Hybrid LLM routing design: paid APIs only where they're irreplaceable
→ Local model setup (Ollama + Qwen/Mistral) for high-volume standard tasks
→ Prompt caching implementation for repeated system prompts (~85% input cost reduction)
→ Context compression and batching strategies
→ Real-time cost monitoring dashboard
Typical outcome: 40-70% reduction in monthly AI spend. In production systems I've achieved up to 90% reduction using hybrid local + cloud architecture.
This is architecture work - not prompt tweaking.
Stack: Claude API · OpenAI · Ollama · Qwen · Mistral · Semantic Kernel · FastAPI · .NET Core · Python
Proof: HiveGPT Inc. USA, Social27 Seattle - production AI systems at enterprise scale.
AI Development Type
Knowledge Representation, Model Tuning, Recommendation System, Software MaintenanceAI Tools
Amazon SageMaker, Azure Machine Learning, Chainer, Deeplearning4j, Google AutoML, NVIDIA AI Platform, Open Neural Network Exchange, PyTorch, Sonnet, TensorFlowAI Development Language
PythonWhat's included $4,000
These options are included with the project scope.
$4,000
- Delivery Time 14 days
- Number of Revisions 1
- AI Model Integration
- Detailed Code Comments
- Knowledge Graph
- Model Documentation
Optional add-ons
You can add these on the next page.
Fast 10 Days Delivery
+$1,000
Additional Revision
+$500Frequently asked questions
25 reviews
(21)
(2)
(1)
(1)
(0)
This project doesn't have any reviews.
LD
Lokesh D.
Jun 19, 2026
Senior AI Systems Architect -
Full-Spectrum Automation with Zero-Hallucination, multi LLMs Orch
Vijay didn't just complete the project, he elevated it. His ability to architect complex AI systems, eliminate bottlenecks, reduce hallucinations, and create intelligent orchestration layers was remarkable. The final solution was robust, scalable, and far beyond initial expectations. One of the strongest AI engineering professionals we've worked with.
LD
Lokesh D.
May 27, 2026
AI Developer for RAG and Knowledge Bases with using Nextjs, Python and .NetCore APIs
Vijay... is a highly skilled and refined Professional with strong technical skills and commitment. He takes care of my complex <Web and mobile Development project - using RAG, Agentic AI, React, .NetCore WebAPIs, multi LLMs orchestration, ultimate UI/UX and Backend Functions> requirements and completed the delivery on time and of high quality. Will continue to work with him on upcoming projects. Thanks Vijay
RL
Ramesh L.
Jan 23, 2017
WCF expert
Vijay is very good freelancer and completes work on time with greater quality. Will hire him again.
EJ
Ethan J.
May 9, 2016
Creation of a customer driven dynamic grids or views of data
VP
Vijay P.
Feb 27, 2015
ASP MVC5 CodeFirst AZURE Jquery Webpage
Thanks Vijay for your work!
About Vijay
AI Integration Engineer | .NET + Next.js SaaS | LLM Costing | CTO
100%
Job Success
Nathdwara, India - 1:10 am local time
My focus: integrating LLMs, automating workflows, and modernizing .NET or Node.js backends so your product works smarter and costs less to run.
─── What I do ───
→ Add AI features (chat, document parsing, lead automation, voice workflows) to existing SaaS products
→ Architect hybrid LLM systems using local models (Ollama + Qwen) + cloud APIs (Claude, OpenAI) to cut AI costs by 40–70%
→ Build and modernize .NET Core 8/10 APIs, Next.js 15 frontends, Angular 16–20 dashboards
→ Design multi-tenant SaaS architecture, PostgreSQL schemas, pgVector RAG pipelines
→ Act as a Fractional CTO for small SaaS teams who need senior technical leadership without full-time cost
─── My stack ───
Backend: .NET Core 8/10, Node.js, PostgreSQL, MS SQL, MongoDB
Frontend: Next.js 15, Angular 16–20, React, React Native
AI/LLM: Claude API, OpenAI, Ollama, Qwen, Semantic Kernel, RAG, pgVector, multi-agent pipelines
Infra: Azure, Supabase, Firebase, Docker
─── Why clients choose me ───
18+ years delivering enterprise software across India, USA, and UK. I have held senior roles at HiveGPT Inc. (USA) and Social27 (Seattle). I understand what enterprise clients need — security, scalability, and delivery that doesn't slip.
I work with a small, focused team. You get senior-level architecture and clean code — not juniors pretending to be seniors.
If you need someone who can look at your existing product, identify exactly where AI adds value, and implement it without breaking what already works — let's talk.
→ Message me "AUDIT" — I'll review your project and tell you exactly what architecture decisions will matter most.
Steps for completing your project
After purchasing the project, send requirements so Vijay can start the project.
Delivery time starts when Vijay receives requirements from you.
Vijay works on your project following the steps below.
Revisions may occur after the delivery date.
Cost Audit
You share your current API usage data and architecture overview. I analyze cost per endpoint, identify which calls truly need frontier models vs which can run locally, and deliver a savings projection within 48 hours.
Architecture Redesign
I design and implement the hybrid routing layer - local Qwen/Mistral via Ollama for standard tasks, prompt caching for repeated contexts, and batching where applicable. Semantic Kernel or FastAPI orchestration.