You will get Structured USPTO Patent Data Generation (Section G & H)
Rising Talent

Project details
Custom USPTO Patent Data Extraction & Structuring (Section G & H)
I provide custom extraction and processing for USPTO patent records. I extract requested CPC codes and structure them into AI-ready datasets optimized for ML, LLMs, Vector DBs, and RAG pipelines.
SUPPORTED CLASSES (Examples):
• Section G (Physics):
G01: Measuring; Testing
G02: Optics
G06: Computing; Calculating; Counting
G08: Signaling
G16: ICT
• Section H (Electricity):
H01: Basic Electric Elements
H02: Generation & Distribution of Electric Power
H03: Basic Electronic Circuitry
H04: Electric Communication Technique
H05: Other Electric Techniques
WORKFLOW:
1. Upon purchase, send a message specifying your target CPC codes (must be from Section G or H) and desired data volume.
Example: "Target: G01, Volume: 100 records"
2. I will extract, process, and deliver the custom dataset directly via message.
DELIVERY FORMATS:
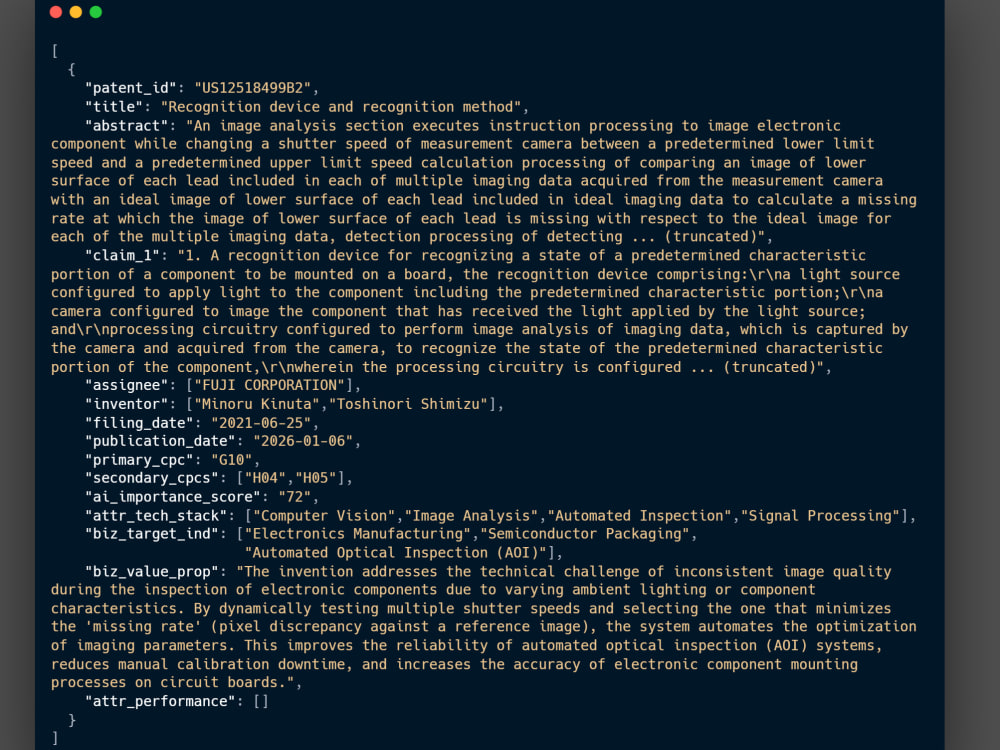
• JSON: Valid arrays tailored for direct Vector DB ingestion.
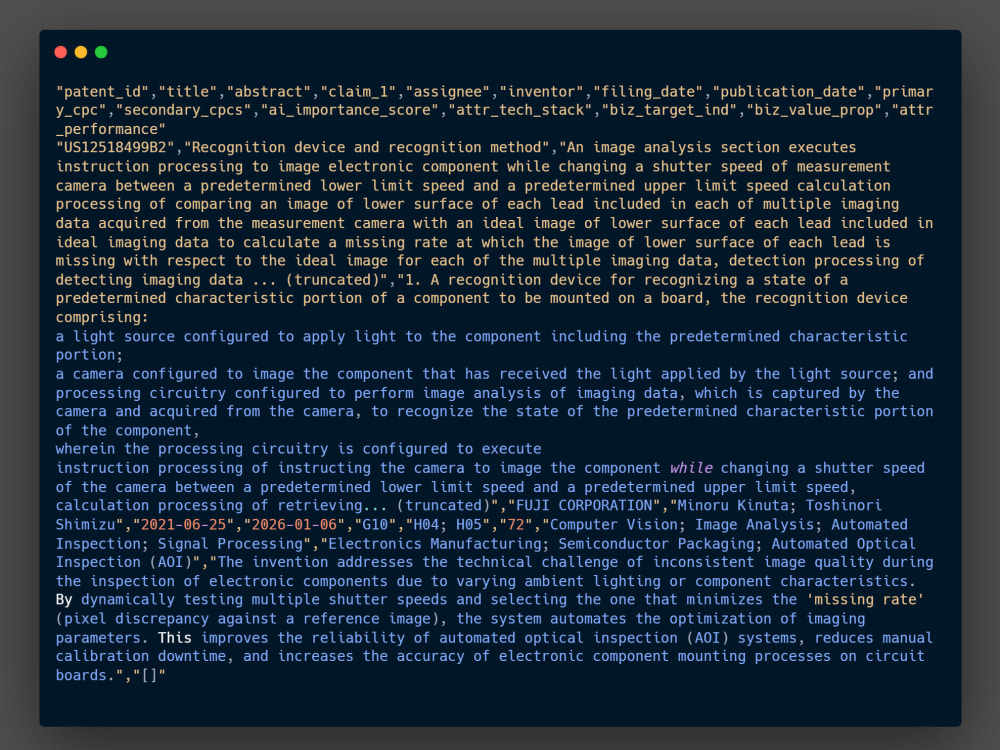
• CSV: Semicolon delimited, optimized for Pandas.
SAMPLES:
Check gallery images for data structures. Send a direct message for complete sample files (JSON/CSV) before purchasing.
I provide custom extraction and processing for USPTO patent records. I extract requested CPC codes and structure them into AI-ready datasets optimized for ML, LLMs, Vector DBs, and RAG pipelines.
SUPPORTED CLASSES (Examples):
• Section G (Physics):
G01: Measuring; Testing
G02: Optics
G06: Computing; Calculating; Counting
G08: Signaling
G16: ICT
• Section H (Electricity):
H01: Basic Electric Elements
H02: Generation & Distribution of Electric Power
H03: Basic Electronic Circuitry
H04: Electric Communication Technique
H05: Other Electric Techniques
WORKFLOW:
1. Upon purchase, send a message specifying your target CPC codes (must be from Section G or H) and desired data volume.
Example: "Target: G01, Volume: 100 records"
2. I will extract, process, and deliver the custom dataset directly via message.
DELIVERY FORMATS:
• JSON: Valid arrays tailored for direct Vector DB ingestion.
• CSV: Semicolon delimited, optimized for Pandas.
SAMPLES:
Check gallery images for data structures. Send a direct message for complete sample files (JSON/CSV) before purchasing.
AI Development Type
Knowledge RepresentationAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$5
|
Standard
$49
|
Advanced
$395
|
|---|---|---|---|
| Delivery Time | 1 day | 1 day | 1 day |
AI Model Integration | - | - | - |
Detailed Code Comments | - | - | - |
Knowledge Graph | - | - | - |
Model Documentation | - | - | - |
Ontology | - | - | - |
Source Code | - | - | - |
Taxonomy | - | - | - |
About Toru
Python Data Engineer | SEC EDGAR & USPTO Patents | AI-Ready JSON | MCP
Chiba, Japan - 7:54 am local time
SEC EDGAR (10-K / 10-Q): compliant ingestion via SEC APIs (no brittle browser automation), XBRL/CompanyFacts metrics (YoY/QoQ), MD&A and risk-factor extraction with Gemini/Vertex batch jobs, validation scores, and delivery as JSON/JSONL (one row = one filing). Proven “factory” flow: download → chunk → batch LLM → structured agent bundles → database + object storage.
USPTO patents: AI-ready patent JSON for competitive intelligence, prior art search, and R&D agents—CPC G/H (computing, telecom, semiconductors). Daily automated pipeline on Google Cloud Run (high-volume XML → enriched JSON with claims, business value fields, importance scores). MCP server available for agent integration (search, packages, structured schema).
What you get
• Structured JSON/JSONL with documented fields (identity, facts, narrative events, validation)
• Repeatable batch runs, idempotent upserts, rate-limit–safe SEC access
• Optional: Supabase/Postgres, R2/S3, Vertex Batch, MCP/xpay agent endpoints
• Milestone delivery: prototype on 1 ticker / 10 filings → scale to hundreds or thousands
Typical projects I’m hired for
• SEC filing data extraction pipelines (10-K, 10-Q, 8-K matching)
• XBRL / financial statement fact mapping
• Bulk LLM extraction from MD&A, risk factors, guidance
• USPTO patent datasets for LLM, quant, or IP analytics
• MCP tool design for “buy structured data” agent workflows
Tech stack
Python, ETL, pandas, JSON/JSONL, Google Cloud Run, Gemini/Vertex batch, Supabase, R2, BeautifulSoup/lxml (HTML sections), SEC CompanyFacts/XBRL, MCP, API integration.
How I work
Clear written scope, documented outputs, and testable milestones. I prefer chat/email on Upwork for accuracy and audit trails. Ask me for a sample schema or a one-company demo path before large bulk work.
Communication: Upwork messages only (async). No video or phone calls.
English: written technical communication only — specs, milestones, and deliverables in chat. Best fit for fixed-scope, deliverable-based work.
Steps for completing your project
After purchasing the project, send requirements so Toru can start the project.
Delivery time starts when Toru receives requirements from you.
Toru works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Definition & Order Confirmation
Please specify your required CPC classes (from Section G or H) and data volume. Example: "Target: G01, Volume: 100 records" I will confirm the requirements and proceed with the custom data extraction.
Secure Dataset Delivery
The extracted dataset will be delivered directly via the Upwork message board. For large files, a secure Google Drive link (ZIP archive) will be provided.