You will get AI Evaluation Rubric Design
Project details
Your AI model is only as good as the rubric measuring it. I design evaluation frameworks that catch the failures your users will notice (hallucinations, missed context, wrong reasoning) before they ship.
With 8 years of AI training and evaluation work across multiple major AI development platforms, I've built hundreds of rubrics, golden responses, and adversarial test cases across domains including technical support, gaming, creative writing, and code generation.
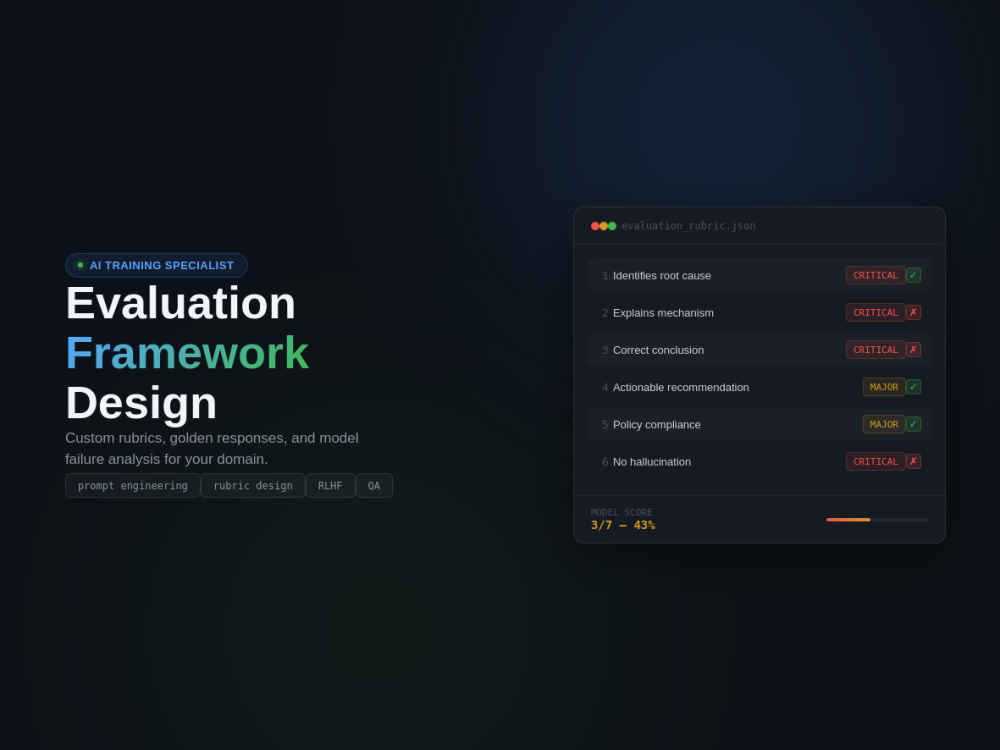
Here's what you get: a custom evaluation prompt designed to surface your model's weak spots, a weighted rubric with scored criteria (Critical/Major/Minor), a golden response showing what a perfect answer looks like, and a model failure analysis showing exactly where and why a typical response falls short.
Every framework I build is designed for real annotator use. Clear enough that your team can apply it consistently, specific enough to catch the failures that matter. I work in any domain. You bring the subject matter expertise, I bring the evaluation methodology.
With 8 years of AI training and evaluation work across multiple major AI development platforms, I've built hundreds of rubrics, golden responses, and adversarial test cases across domains including technical support, gaming, creative writing, and code generation.
Here's what you get: a custom evaluation prompt designed to surface your model's weak spots, a weighted rubric with scored criteria (Critical/Major/Minor), a golden response showing what a perfect answer looks like, and a model failure analysis showing exactly where and why a typical response falls short.
Every framework I build is designed for real annotator use. Clear enough that your team can apply it consistently, specific enough to catch the failures that matter. I work in any domain. You bring the subject matter expertise, I bring the evaluation methodology.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Transformer ModelAI Applications
AI Chatbot, AI Content Creation, AI-Generated Code, Conversational AI, Natural Language Generation, Natural Language Understanding, Sentiment Analysis, Text RecognitionAI Models
ChatGPT, DALL-E, GPT-3, GPT-4, LLaMA, Midjourney AI, Stable DiffusionWhat's included
| Service Tiers |
Starter
$150
|
Standard
$300
|
Advanced
$600
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | - | - | - |
Batch Normalization | - | - | - |
Database Integration | - | - | - |
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | |||
Model Monitoring | - | - | - |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | |||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | - | - | - |
Source Code | - | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$50 - $150
Additional Revision
+$25
Additional domain/prompt
(+ 2 Days)
+$100Frequently asked questions
About Alexandra
AI Annotation Expert | Prompt Design | Evaluation Rubrics | QA
Abingdon, United States - 5:40 am local time
My core work is the writing-heavy side of AI training:
Prompt engineering. I build complex, multi-turn prompts and adversarial test cases designed to stress-test language models and surface failure modes. Chain-of-thought, tree-of-thought, structured reasoning, all of it.
Rubric design and golden responses. I create the evaluation frameworks that set quality standards for annotation teams, then write the benchmark responses that calibrate scoring. I've been selected for rubric academies and pilot cohorts specifically because of this.
Content evaluation and QA. I audit annotator work, resolve ambiguities in guidelines, and maintain consistency across large projects. Text, code, images, audio, video. If it's training data, I've evaluated it.
Writing is the throughline of everything I do. I'm finishing a Creative Writing BFA at Full Sail, I've been published in Crutchfield's national catalog as a technical writer, and I spent four years turning complex electronics specs into language actual humans could understand. That combination of creative and technical writing is why I'm good at this. I can tell you why an AI response fails, not just that it fails.
I also have enough technical background to be useful when projects need it (Python, pandas, Docker, Git, JSON pipelines), but I'm at my best when I'm writing, evaluating, and building the frameworks that keep annotation quality high.
Steps for completing your project
After purchasing the project, send requirements so Alexandra can start the project.
Delivery time starts when Alexandra receives requirements from you.
Alexandra works on your project following the steps below.
Revisions may occur after the delivery date.
Domain review
I study your model's subject area and identify the highest-value evaluation targets.
Framework build
I draft the evaluation prompt, weighted rubric, golden response, and failure analysis.