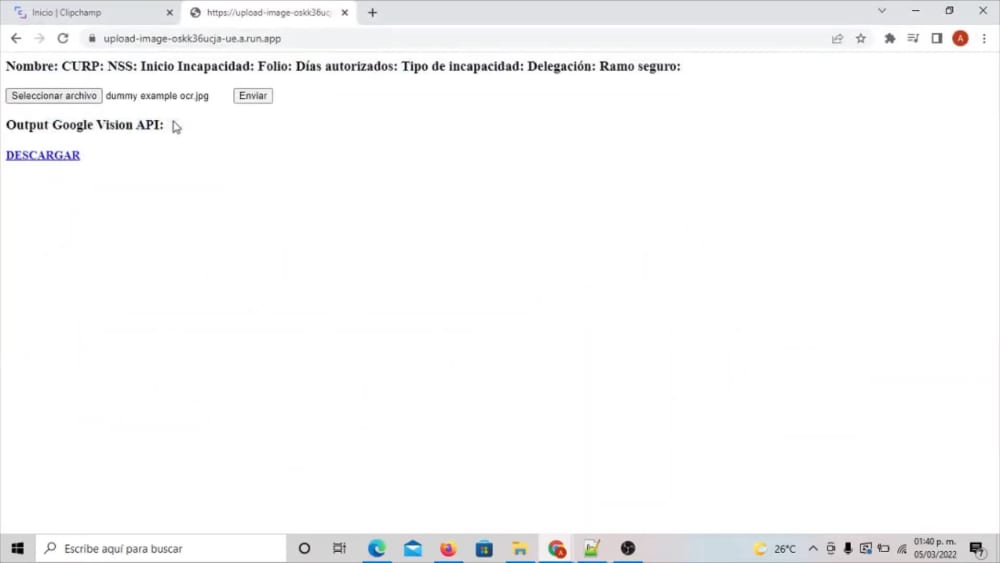
You will get an app to extract text from image / pdf files using Google Cloud Vision API
Project details
You will get an app to extract text from image / pdf files having a pre-defined format. With 2 years of experience in applying computer vision for retail companies, I bring deep learning ready for your enterprise to contribute to their growth and innovation through the latest AI techniques.
What's included $150
These options are included with the project scope.
$150
- Delivery Time 30 days
- Number of Revisions 1
- Source Code
About Antonio de Jesus
Data Scientist
Cuautitlan, Mexico - 4:28 pm local time
The tools that I use are Python, R, SAS, SQL and Scala/Spark. Also machine learning algorithms (supervised and unsupervised) e.g. Xgboost, logistic regressions, k-means clustering, etc., deep learning e.g. recurrent neural networks, and time series algorithms e.g. Vector Autorregression, Arima, etc. Also Google Cloud Compute Engine (to run algorithms such as recurrent neural networks or Bayesian optimization in the cloud).
My activities include data analysis, data wrangling, text mining, webscraping, forecasts of time series, classification and regression tasks, deploying models as websites, among others.
Steps for completing your project
After purchasing the project, send requirements so Antonio de Jesus can start the project.
Delivery time starts when Antonio de Jesus receives requirements from you.
Antonio de Jesus works on your project following the steps below.
Revisions may occur after the delivery date.
Receive sample dataset
I will receive a sample dataset containing image or pdf files having a pre-defined format together with the specific text fields that you want to be extracted.
Evaluate rules for text extraction and their accuracy
If there is a text field where the result is not what you expect, I will let you know at this point (for example if text is not readible due to image defects like blurred documents, weak hand-written text, damaged images, etc.).