You will get an end to end real time and batch processing ETL pipeline on AWS
Project details
I will help you design and deliver a production grade, end to end ETL/ELT pipeline on AWS handling both real time streaming and batch processing clean, reliable, and built to scale.
With 10+ years of Data Engineering experience, I have built data infrastructure for clients in finance, retail, telecom, and tech across AWS, GCP, and Azure.
What is included:
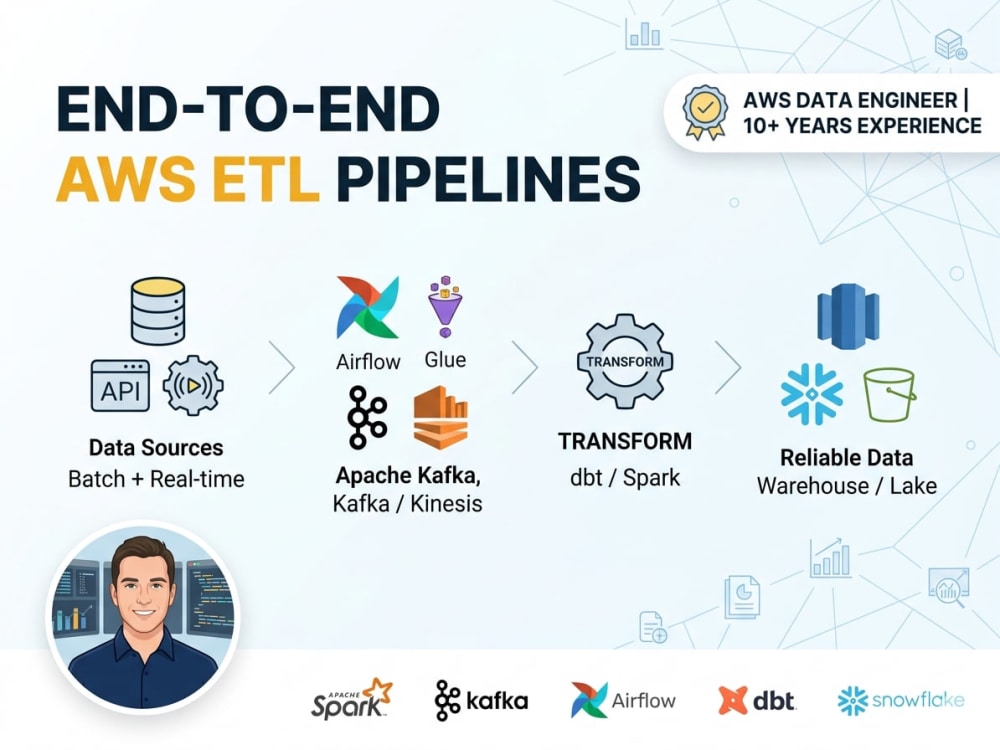
• Data ingestion from APIs, databases, or streaming sources
• Batch processing with AWS Glue, Airflow, and Apache Spark
• Real time streaming with Kafka, Kinesis, and CDC via Debezium
• Transformation and modeling using dbt
• Storage on S3, Redshift, or Snowflake
• Data quality checks with Great Expectations
• Monitoring, alerting, and full documentation
Perfect for you if:
• You need a pipeline built from scratch on AWS
• Your existing pipeline is breaking or not scaling
• You need both batch and real time processing together
Every delivery includes clean code, dbt models, quality gates, and full architecture documentation so your team can maintain and extend it confidently after handover.
Message me before ordering so I can recommend the right package for your needs.
With 10+ years of Data Engineering experience, I have built data infrastructure for clients in finance, retail, telecom, and tech across AWS, GCP, and Azure.
What is included:
• Data ingestion from APIs, databases, or streaming sources
• Batch processing with AWS Glue, Airflow, and Apache Spark
• Real time streaming with Kafka, Kinesis, and CDC via Debezium
• Transformation and modeling using dbt
• Storage on S3, Redshift, or Snowflake
• Data quality checks with Great Expectations
• Monitoring, alerting, and full documentation
Perfect for you if:
• You need a pipeline built from scratch on AWS
• Your existing pipeline is breaking or not scaling
• You need both batch and real time processing together
Every delivery includes clean code, dbt models, quality gates, and full architecture documentation so your team can maintain and extend it confidently after handover.
Message me before ordering so I can recommend the right package for your needs.
Database Type
PostgreSQL, MongoDB, TeradataWhat's included
| Service Tiers |
Starter
$150
|
Standard
$200
|
Advanced
$1,000
|
|---|---|---|---|
| Delivery Time | 5 days | 7 days | 10 days |
Number of Revisions | 1 | 2 | 2 |
Number of Tables Added | 5 | 15 | 30 |
Schema Diagram | - | ||
Permissions Setup | - | ||
Import/Export Data | |||
Admin Panel Setup | - | - |
About Nofel
Cloud Data Engineer | AWS, Azure, DevOps | Snowflake, dbt, Databricks
Lahore, Pakistan - 9:13 pm local time
I build production grade data solutions for clients across finance, retail, telecom, and tech supporting both startups and large enterprises. My work spans greenfield data platform builds, legacy ETL modernization, cloud migrations, and real time streaming architectures ensuring every pipeline is reliable, observable, and built to scale.
I specialize in end to end Data Engineering delivery:
- ETL/ELT pipeline development, orchestration, and automation (Airflow, AWS Glue, Azure Data Factory, Fivetran, Apache Beam)
- Real time and streaming architectures (Apache Kafka, Apache Flink, AWS Kinesis, Google Pub/Sub, Debezium, CDC)
- Data transformation and modeling using dbt (data build tool) with fully tested and documented dbt models
- Cloud Data Warehouse design and optimization (Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse Analytics)
- Data Lakehouse architecture with open table formats (Apache Iceberg, Delta Lake, Apache Hudi) on Databricks and cloud storage
- Big data processing and distributed computing (Apache Spark, Spark SQL, Trino, Presto, Athena)
- Data Quality frameworks and observability (Great Expectations, Soda)
Data Governance, Data Lineage, Data Catalog, and Metadata Management (OpenMetadata, DataHub)
- Multi cloud data platform design across AWS (S3, Glue, Redshift, Athena), GCP (BigQuery, Pub/Sub, Cloud Storage), and Azure (Synapse, Data Lake, Data Factory)
Pipeline stabilization, performance optimization, and cost reduction for underperforming data systems
How I work:
I follow proven data engineering principles to ensure:
- Pipelines align with business goals and analytical requirements
- Technical debt, bottlenecks, and data quality risks are eliminated early
- Architectures remain modular, maintainable, and cloud agnostic where possible
- Platforms scale reliably with data volume, team size, and workload growth
I treat data infrastructure as a business enabler, not just a technical implementation. Every design decision focuses on reducing pipeline failures, improving data reliability, and accelerating time to insight for your teams.
The difference I bring:
You can use modern data engineering to:
- Build scalable ETL/ELT pipelines that handle growing data volumes without breaking
- Move from batch only to real time streaming with Kafka, Flink, and Kinesis
- Migrate legacy data systems to modern cloud platforms like Snowflake or Databricks
- Implement a Data Lakehouse that gives you both flexibility and warehouse grade reliability
- Enforce Data Governance, Data Lineage, and Data Quality across your entire data platform
- Replace fragmented, manual, or unreliable data workflows with automated, observable pipelines
Let's build a data platform that actually scales.
Steps for completing your project
After purchasing the project, send requirements so Nofel can start the project.
Delivery time starts when Nofel receives requirements from you.
Nofel works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements Gathering
Review client requirements, data sources, target destination, and pipeline scope to finalize the delivery plan.
Architecture Design
Design the end to end pipeline architecture including ingestion, transformation, storage, and streaming layers.