You will get an MCP server (Claude, ChatGPT, Cursor...) for your SaaS, deploy-ready
Project details
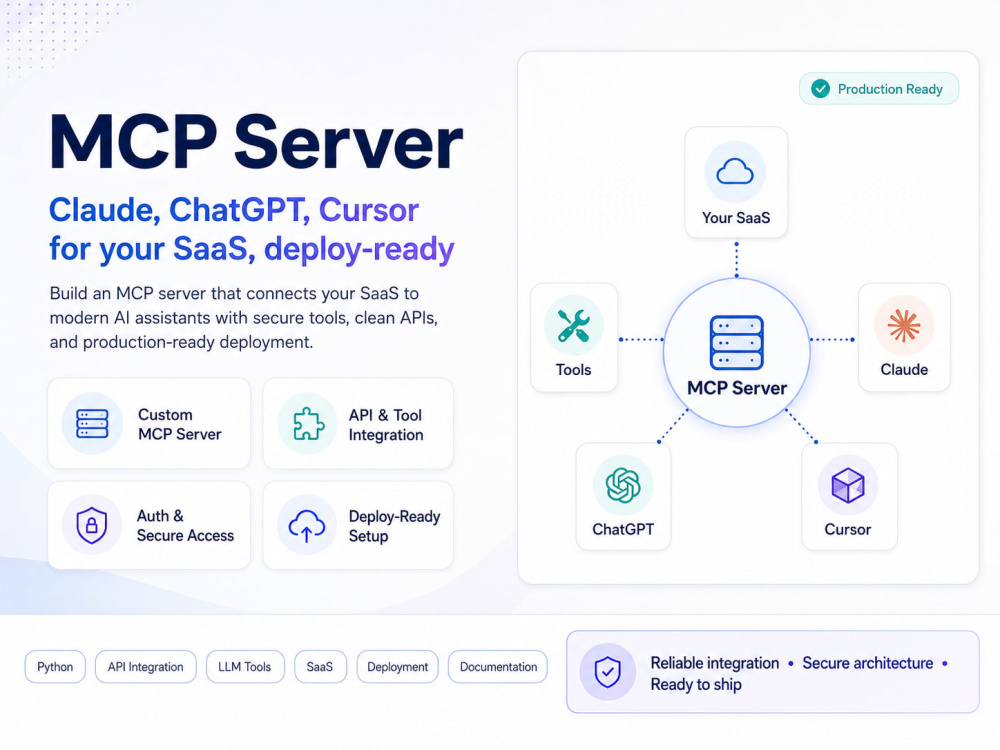
Anthropic's Model Context Protocol is how Claude, ChatGPT, and Cursor talk to your product. SDK installs went from 2 million to 97 million per month in 12 months. Forrester expects 30% of enterprise SaaS to ship one in 2026.
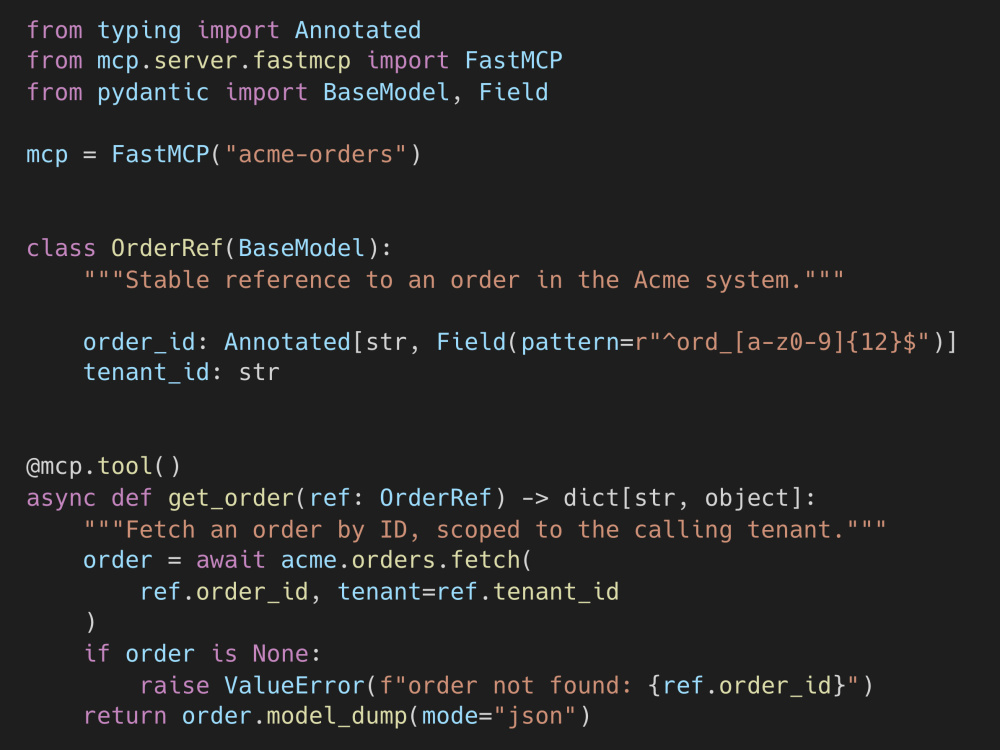
I build production-grade MCP servers. Typed tool schemas with Pydantic, real auth (not just an API key in an env var), proper error semantics, and compatibility tests against Claude Desktop, Cursor, and ChatGPT before delivery. Not a tutorial port.
Standard tier: up to 5 typed tools wired to your API, OAuth or static-key auth, FastMCP-style Python server, Claude Desktop manifest, deploy script for Modal/Railway/Fly or your existing infra, README a junior engineer can extend.
Six years writing production AI for Société Générale, Allianz, and Decathlon. Currently shipping a Claude support agent at Decathlon. Built the open-source eval-kit Python library on the same engineering bar.
API access on day 1, delivery on day 8. If the server cannot pass standard tier compatibility tests, I refund the difference.
I build production-grade MCP servers. Typed tool schemas with Pydantic, real auth (not just an API key in an env var), proper error semantics, and compatibility tests against Claude Desktop, Cursor, and ChatGPT before delivery. Not a tutorial port.
Standard tier: up to 5 typed tools wired to your API, OAuth or static-key auth, FastMCP-style Python server, Claude Desktop manifest, deploy script for Modal/Railway/Fly or your existing infra, README a junior engineer can extend.
Six years writing production AI for Société Générale, Allianz, and Decathlon. Currently shipping a Claude support agent at Decathlon. Built the open-source eval-kit Python library on the same engineering bar.
API access on day 1, delivery on day 8. If the server cannot pass standard tier compatibility tests, I refund the difference.
AI Algorithms
CycleGAN, Deep Belief Network, Gated Recurrent Unit, Generative Adversarial Network, Large Language Model, Long Short-Term Memory Network, Multimodal Large Language Model, Recurrent Neural Network, Self-Organizing Map, Transformer ModelAI Applications
AI Chatbot, AI Text-to-Image, AI Text-to-Speech, AI-Enhanced Classification, AI-Enhanced Medical Imaging, AI-Generated Code, AI-Generated Music, AI-Generated Video, AIOps, Conversational AI, Natural Language Generation, Natural Language UnderstandingAI Development Language
PythonAI Tools
Azure OpenAI, Bing AI, Copy.ai, Gradio, Hugging Face, Microsoft 365 Copilot, Microsoft CNTK, PyTorch, Replit, Word2vecAI Models
BERT, BLOOM, Dolly, GPT-4, GPT-J, GPT-Neo, LaMDA, LLaMA, Midjourney AI, OpenAI Codex, Stable Diffusion, WhisperWhat's included
| Service Tiers |
Starter
$900
|
Standard
$2,950
|
Advanced
$6,500
|
|---|---|---|---|
| Delivery Time | 4 days | 8 days | 14 days |
AI Model Integration | - | ||
Batch Normalization | - | - | - |
Database Integration | - | - | |
Detailed Code Comments | |||
Image Upscaling | - | - | - |
MLOps | - | - | |
Model Deployment | - | ||
Model Documentation | |||
Model Monitoring | - | - | |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | |||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | |||
Source Code |
Optional add-ons
You can add these on the next page.
Add 3 more typed tools to your MCP server
(+ 3 Days)
+$400
Custom OAuth flow with your identity provider
(+ 3 Days)
+$600Frequently asked questions
About Amir
Senior AI/LLM Engineer | RAG, AI Agents, LangChain, LLM Evals
Paris, France - 8:57 am local time
Currently at Decathlon building a Claude support agent with RAG over the product catalogue: three Sonnet calls (classify, draft, escalate) through Anthropic's tool-use API, per-call cost accounting, a 50-row eval set running in CI. Before that, three years at Allianz taking the insurer's first LLM applications from prototype to production: a document Q&A system for claim adjusters, a multi-step research agent on LangGraph, and a vendor-neutral wrapper around Anthropic and OpenAI. Three years before that at Société Générale on classical ML and NLP: a transformer-based document classifier for compliance, OCR for scanned regulatory filings, the team's first embeddings-based search.
What I publish on GitHub:
- A production RAG reference that refuses to answer when retrieval does not support the claim. 50-question eval gate blocks merges on more than 3 points of regression.
- A customer-support agent: three Sonnet calls, calibrated confidence, real cost accounting, eval gate in CI.
- A 7-node LangGraph DAG with a parallel fan-out and a critic retry loop. Streams per-node telemetry over SSE.
- An open-source Python library for LLM evals: calibrated LLM-as-judge, synthetic adversarial data, regression diff that fails the PR.
Stack: Python, FastAPI, Anthropic Claude, OpenAI, LangGraph, Voyage embeddings, pgvector, Postgres, Modal, Langfuse, Next.js, Tailwind. Bar: mypy strict, ruff, pytest with a coverage gate, golden-set evals in CI, structlog, per-call cost tracking. Every repo runs make ci clean from a fresh clone.
Best fit for:
- Building a RAG system that has to cite, not invent.
- Taking a multi-step agent prototype to production.
- Setting up the eval and quality engineering layer your team has been meaning to build.
EU timezone, 30+ hours per week, async-friendly.
Steps for completing your project
After purchasing the project, send requirements so Amir can start the project.
Delivery time starts when Amir receives requirements from you.
Amir works on your project following the steps below.
Revisions may occur after the delivery date.
Day 1: kickoff and scope confirmation
Receive your API access, target LLM client list, tool list, auth approach, and deployment target. 30-min sync to confirm tool scope (verb, noun, params) so I don't ship the wrong thing.
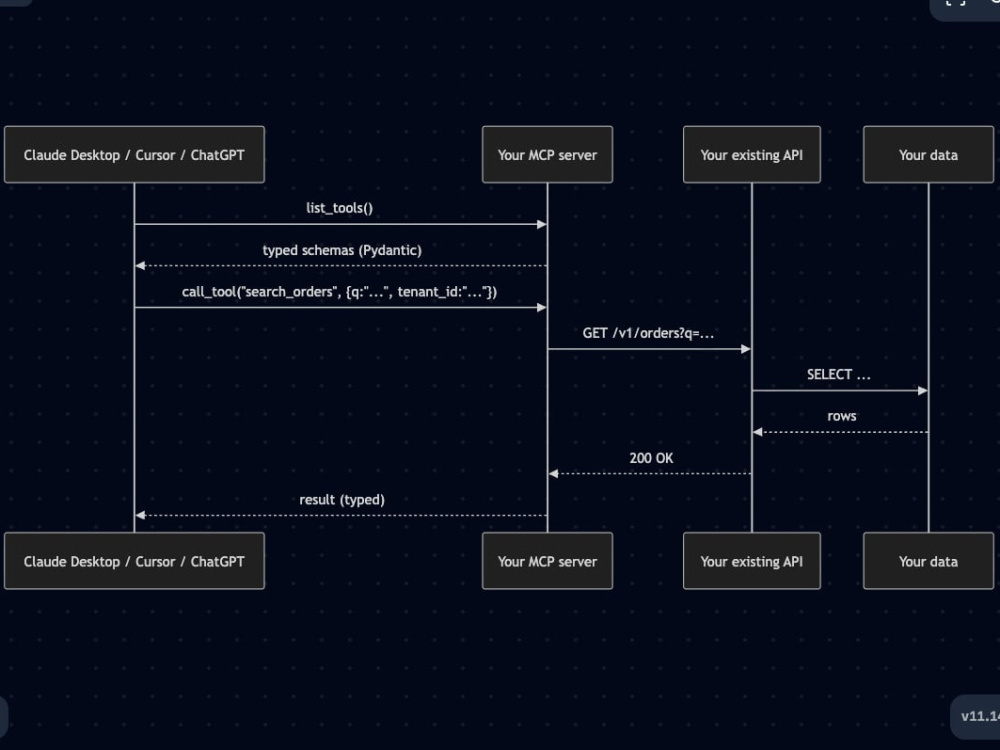
Days 1-3: typed tool schemas wired to your API
Build Pydantic schemas for each tool, wire to your API endpoints, handle pagination and rate limits. Errors map to MCP error semantics so the LLM doesn't hallucinate around a 500.