You will get audit and optimize your RAG pipeline for better retrieval quality
Rising Talent
Rising Talent
Project details
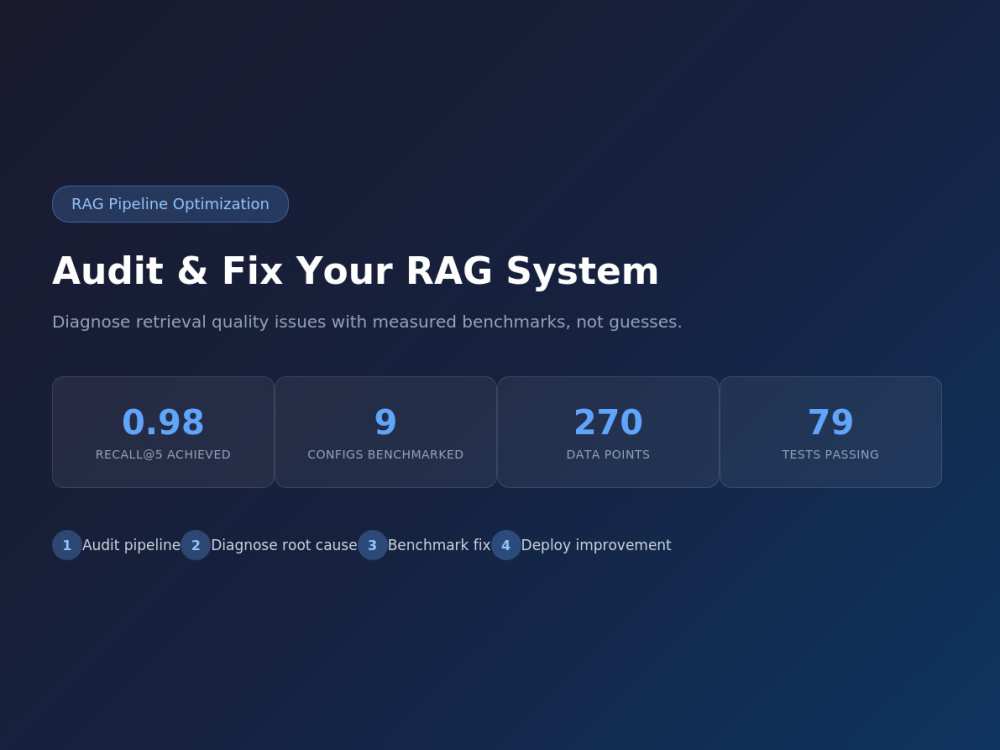
Is your RAG system returning irrelevant chunks, hallucinating, or missing obvious answers? I diagnose exactly why — with measured benchmarks, not guesses.
I built a production RAG system benchmarked across 9 retrieval configurations (Recall@5 0.98, MRR 0.80, 270 data points). I use the same evaluation methodology to audit your pipeline: chunking strategy, embedding model, retrieval config, and ranking.
Current RAG clients in US tax/compliance and Spanish legal — both privacy-sensitive, production systems. Stack: Python, FastAPI, Qdrant, pgvector, Ollama, OpenAI, Docker.
Public reference: github.com/egtimer/fastapi-rag-lab (79 tests, 6 ADRs, RAGAS eval pipeline).
Send me a message describing your setup and I'll tell you if I can help.
I built a production RAG system benchmarked across 9 retrieval configurations (Recall@5 0.98, MRR 0.80, 270 data points). I use the same evaluation methodology to audit your pipeline: chunking strategy, embedding model, retrieval config, and ranking.
Current RAG clients in US tax/compliance and Spanish legal — both privacy-sensitive, production systems. Stack: Python, FastAPI, Qdrant, pgvector, Ollama, OpenAI, Docker.
Public reference: github.com/egtimer/fastapi-rag-lab (79 tests, 6 ADRs, RAGAS eval pipeline).
Send me a message describing your setup and I'll tell you if I can help.
Machine Learning Tools
ArcGIS, MLflow, NumPy, Python, PyTorch, Tesseract OCRWhat's included
| Service Tiers |
Starter
$500
|
Standard
$800
|
Advanced
$2,000
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 9 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 0 | 3 | 5 |
Number of Scenarios | 3 | 10 | 29 |
Number of Graphs/Charts | 0 | 0 | 3 |
Model Validation/Testing | |||
Model Documentation | |||
Data Source Connectivity | - | ||
Source Code | - |
Frequently asked questions
1 review
(0)
(1)
(0)
(0)
(0)
This project doesn't have any reviews.
AG
Ander G.
May 4, 2026
AI Automation Specialist (n8n + Database + Web Form Automation) – Long-term collaboration possible
About Eduardo
AI Engineer | RAG, LLM Fine-Tuning & Document AI | Production Systems
Santa Cruz de Tenerife, Spain - 3:59 am local time
regulated industries — legal, tax, compliance, healthcare.
Currently active on Upwork with two long-term clients in EU and US.
Production track record:
- US tax compliance RAG over 50+ IRS documents — 100% local Docker,
zero cloud, hybrid retrieval (Recall@5 0.98 benchmarked on a
270-point golden dataset, RAGAS metrics)
- Spanish legal form automation — OCR + LLM extraction + n8n
workflows reducing manual review 75-90%
- AI Tech Lead at Icod Systems — multilingual document
classification (IT/ES/EN), LoRA/QLoRA fine-tuning with +25-40%
accuracy on domain tasks
See Portfolio section below for two public production repos:
- fastapi-rag-lab: 9 retrieval configs benchmarked, 79 tests,
Langfuse tracing, 6 ADRs
- agentic-sql-assistant: LangGraph agent, tool calling, 85 tests
Best fit if you need:
- RAG over your documents (legal, tax, compliance, healthcare)
- Document automation: OCR + LLM extraction + workflow integration
- Local/private LLM deployment (Ollama, Qdrant) for data sovereignty
- Production discipline: golden datasets, evaluation, observability
Stack: Python, FastAPI, Qdrant, Ollama, OpenAI/Anthropic API,
LangChain/LangGraph, Hugging Face, Docker, n8n, Tesseract/PaddleOCR.
Native Spanish, professional English. Available 15-25 hrs/week for
long-term engagements. Based in Tenerife (UTC+1).
Steps for completing your project
After purchasing the project, send requirements so Eduardo can start the project.
Delivery time starts when Eduardo receives requirements from you.
Eduardo works on your project following the steps below.
Revisions may occur after the delivery date.
Review your codebase: chunking, embeddings, retrieval config, and indexing
Run diagnostic queries and document which chunks are retrieved vs expected